目录
实现结果如下:

?百度API
这里聊天机器人的功能也是结合第一篇的语音识别(【python】tkinter界面化+百度API―语音识别_张顺财的博客-CSDN博客)和新的百度API智能对话定制与服务平台去实现的。我们需要在百度AI开放平台-全球领先的人工智能服务平台? ?或者智能对话定制与服务平台UNIT-百度AI开放平台?去创建获取ID、API key和Secre Key。

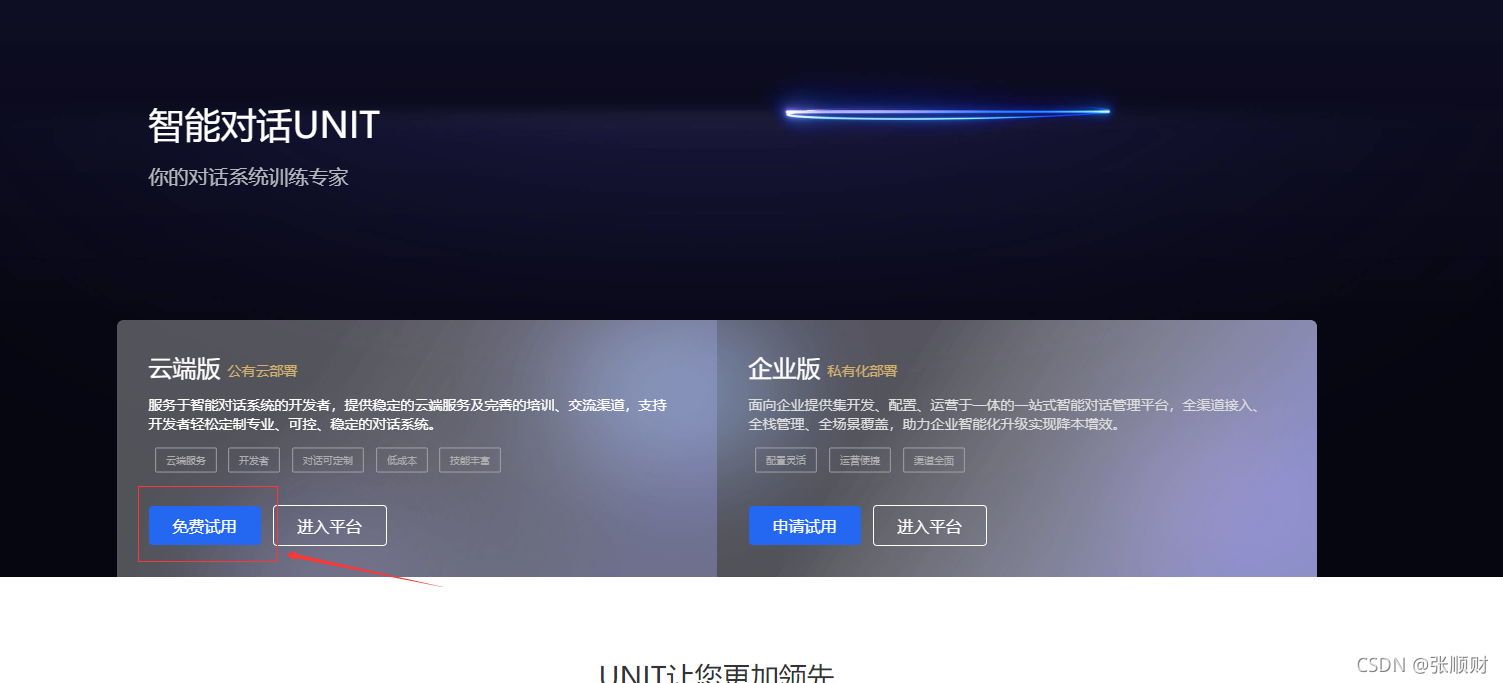
??进入选择立即使用之后跳转到如下页面,然后选择云端版的免费试用
?点击创建机器人,填写信息后创建

创建完机器人我们需要 为机器人添加技能,添加步骤如图所示: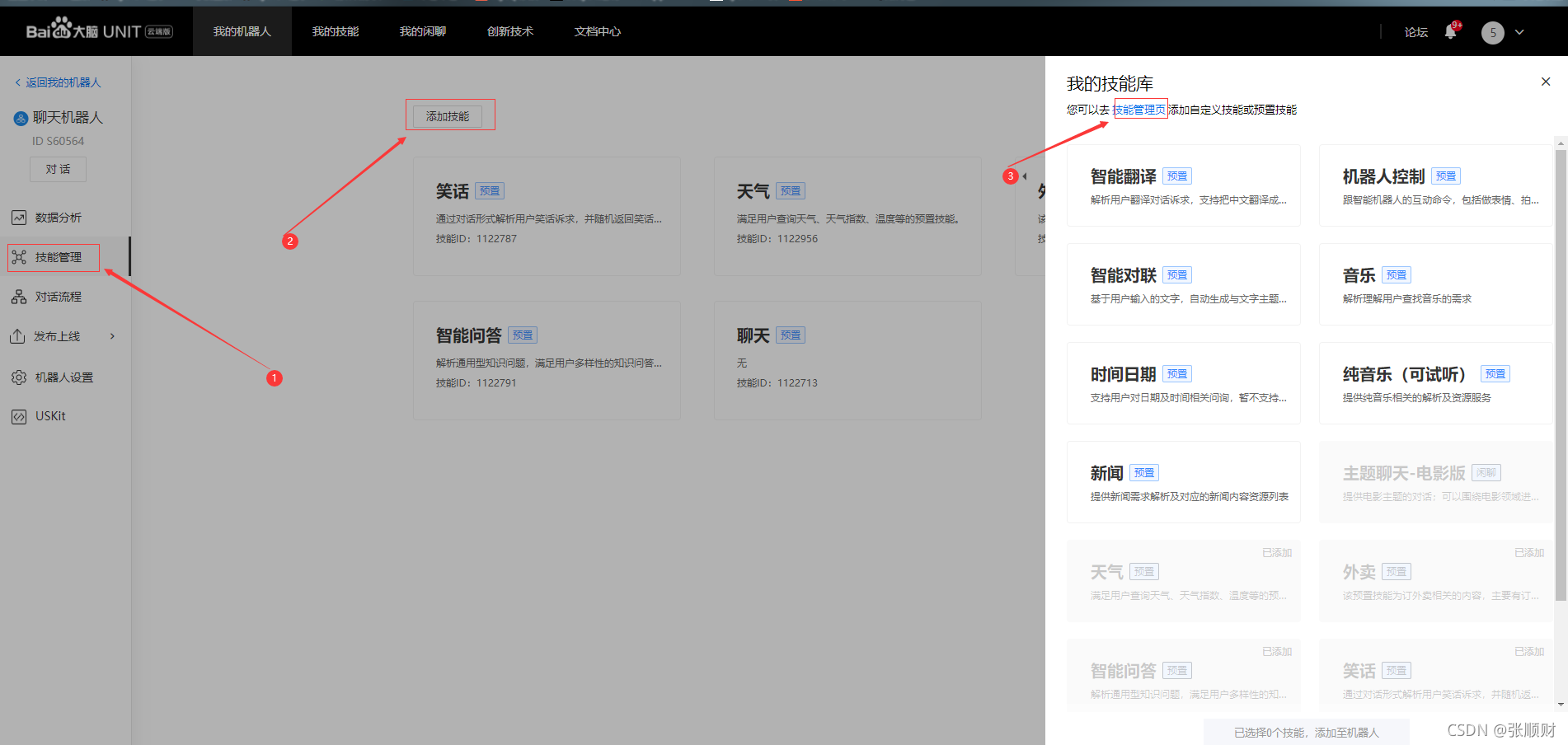
?
然后是获取我们机器人的ID、API key和Secre Key。
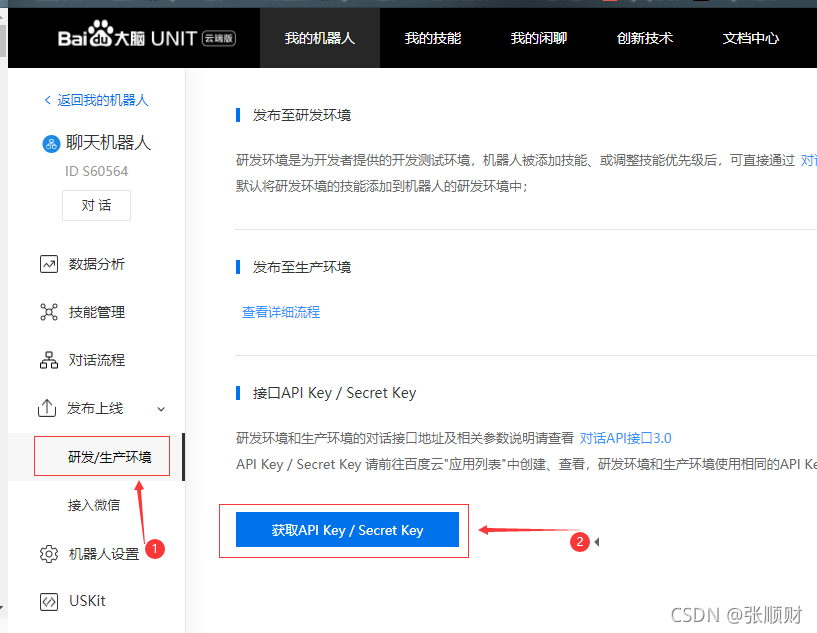
 ?技术文档看这里:https://ai.baidu.com/ai-doc/UNIT/qkpzeloou
?技术文档看这里:https://ai.baidu.com/ai-doc/UNIT/qkpzeloou
?tkinter界面设计
1.界面的初始化及布局:
def __init__(self):
self.ID = '语音识别的ID'
self.Key = '语音识别的API key'
self.Secret = '语音识别的secret key'
# 用语音类创建对象
self.client = AipSpeech(self.ID, self.Key, self.Secret) # 语音识别对象
#创建窗口
self.page = Tk()# Toplevel() # Tk()
self.page.resizable(width=False, height=False)
self.page.title('聊天机器人') #设置标题
self. page. geometry('500x800') #设置窗口大小
# 打开图像,转为tkinter兼容的对象,
img = Image.open('5.jpg').resize([500,800])
self.img = ImageTk.PhotoImage(img)
#创建画布,将图像作为画布背景, 铺满整个窗口
self.canvas = Canvas(self.page, width=500, height=800) #设置画布的宽、高
self.canvas.place(x=0, y=0)
self.canvas.create_image(250,400,image = self.img) #把图像放到画布,默认放置中心点
self.canvas.create_text(250, 100, text='聊天机器人', font=('宋体', 40))
self.canvas.create_text(110, 170, text='内容:', font=('宋体', 20), fill='green')
self.canvas.create_text(110, 270, text='回答:', font=('宋体', 20), fill='blue')
# 创建内容文本框
self.text = Text(self.page, width=22, height=2, font=('宋体', 20))
self.text.place(x=100, y=200)
# 创建回答文本框
self.Reply = Text(self.page, width=22, height=2, font=('宋体', 20))
self.Reply.place(x=100, y=300)
# 创建按钮,游客直接登录到单词界面,学生则需验证账号密码
Button(self.page, width=8, text='聊天', font=('宋体', 20), fg='white',
command=lambda:self.adio_run(), bg='dodgerblue', activebackground='black',
activeforeground='white').place(x=200, y=600) # activebackground 设置按键按下有变化 activebforeground设置前景色
Button(self.page, width=8, text='返回', font=('宋体', 20), fg='white',
command=lambda:self.back(), bg='dodgerblue', activebackground='black',
activeforeground='white').place(x=200, y=650)
Button(self.page, width=5, text='清空', font=('宋体', 20), fg='white',
command=lambda: self.delete_text(), bg='dodgerblue', activebackground='black',
activeforeground='white').place(x=330, y=380)
self.page.mainloop(0)2.access_token的获取模块
def token(self):
Key = '聊天机器人的API key'
Secret = '聊天机器人的secret key'
url = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=' + Key + '&client_secret=' + Secret
result = requests.post(url)
result = result.json()
access_token = result['access_token']
return access_token3.智能对话模块(百度API的调用)
def Unit(self,chat):
url = 'https://aip.baidubce.com/rpc/2.0/unit/service/v3/chat'
url = url + '?access_token=' + self.token()
params = {
'version': '3.0',
'service_id': '聊天机器人的ID',
'log_id': str(random.random()),
'session_id': '',
'request': {'terminal_id': '123456', 'query': chat},
}
response = requests.post(url=url, json=params)
result = response.json()
'result{response[{action[{confidence,say'
# 报错的处理
if result['error_code'] != 0:
return '网页正忙'
result = result['result']['responses'][0]['actions']
reply_act = random.choice([conf for conf in result if conf['confidence'] > 0])
reply = reply_act['say']
# print(reply)
return reply上面代码里聊天机器人的ID不是APIkey那个界面的ID,而是创建完机器人那个界面的ID。如图:

?4.下面是录音模块,文本朗读模块和语音转文本模块的内容
def get_adio(self, sec=0):
p = pyaudio.PyAudio()
stream = p.open(format=pyaudio.paInt16,
channels=1,
rate=16000,
input=True,
frames_per_buffer=1024)
wf = wave.open('test.wav', 'wb')
wf.setnchannels(1)
wf.setsampwidth(p.get_sample_size(pyaudio.paInt16))
wf.setframerate(16000)
print('开始说话')
stopflag = 0
conflag = 0
while True:
data = stream.read(1024)
rt_data = np.frombuffer(data, np.dtype('<i2'))
fft_temp_data = fftpack.fft(rt_data, rt_data.size, overwrite_x=True)
fft_data = np.abs(fft_temp_data)[0:fft_temp_data.size // 2 + 1]
# print(sum(fft_data) // len (fft_data))
# 判断麦克风是否停止,判断说话是否结束,#麦克风阀值,默认7000
if sum(fft_data) // len(fft_data) > 7000:
conflag += 1
else:
stopflag += 1
oneSecond = int(16000 / 1024)
if stopflag + conflag > oneSecond: # 如果两种情况的次数超过一帧的大小
if stopflag > oneSecond // 3 * 2: # 其中无声的部分超过一帧的2/3,则停止
break
else:
stopflag = 0
conflag = 0
wf.writeframes(data)
print('停止说话')
stream.stop_stream()
stream.close()
p.terminate()
wf.close()
return 'test.wav'
def say(self,text):
engine = pyttsx3.init()
engine.say(text)
engine.runAndWait()
def StoT(self):
file = self.get_adio()
# 调用对象进行识别,需要为对象传递参数:
# 识别三种格式:wav,pcm,amr
# 语音文件,语音格式,采样频率,识别ID(1573:中文普通话)
Format = file[-3:]
data = open(file, 'rb').read()
result = self.client.asr(data, Format, 16000, {'dev_pid': 1537})
result = result['result'][0]
# print(result)
return result
def adio_run(self):
self.delete_text()
text = self.StoT()
self.text.insert('insert',text)
# print('原文:', text)
reply = self.Unit(text)
self.Reply.insert('insert',reply)
# print('回答内容:', reply)
self.say(reply)完整代码
from tkinter import *
from PIL import Image,ImageTk
import random
import requests
from scipy import fftpack
import wave
import numpy as np
import pyaudio
import pyttsx3
from aip import AipSpeech
#主界面面设计,创建类,在构造方法中没计界面
class UnitPage():
def __init__(self):
self.ID = '语音识别的ID'
self.Key = '语音识别的API key'
self.Secret = '语音识别的secret key'
# 用语音类创建对象
self.client = AipSpeech(self.ID, self.Key, self.Secret) # 语音识别对象
#创建窗口
self.page = Tk()# Toplevel() # Tk()
self.page.resizable(width=False, height=False)
self.page.title('聊天机器人') #设置标题
self. page. geometry('500x800') #设置窗口大小
# 打开图像,转为tkinter兼容的对象,
img = Image.open('5.jpg').resize([500,800])
self.img = ImageTk.PhotoImage(img)
#创建画布,将图像作为画布背景, 铺满整个窗口
self.canvas = Canvas(self.page, width=500, height=800) #设置画布的宽、高
self.canvas.place(x=0, y=0)
self.canvas.create_image(250,400,image = self.img) #把图像放到画布,默认放置中心点
self.canvas.create_text(250, 100, text='聊天机器人', font=('宋体', 40))
self.canvas.create_text(110, 170, text='内容:', font=('宋体', 20), fill='green')
self.canvas.create_text(110, 270, text='回答:', font=('宋体', 20), fill='blue')
# 创建内容文本框
self.text = Text(self.page, width=22, height=2, font=('宋体', 20))
self.text.place(x=100, y=200)
# 创建回答文本框
self.Reply = Text(self.page, width=22, height=2, font=('宋体', 20))
self.Reply.place(x=100, y=300)
# 创建按钮,游客直接登录到单词界面,学生则需验证账号密码
Button(self.page, width=8, text='聊天', font=('宋体', 20), fg='white',
command=lambda:self.adio_run(), bg='dodgerblue', activebackground='black',
activeforeground='white').place(x=200, y=600) # activebackground 设置按键按下有变化 activebforeground设置前景色
Button(self.page, width=8, text='返回', font=('宋体', 20), fg='white',
command=lambda:self.back(), bg='dodgerblue', activebackground='black',
activeforeground='white').place(x=200, y=650)
Button(self.page, width=5, text='清空', font=('宋体', 20), fg='white',
command=lambda: self.delete_text(), bg='dodgerblue', activebackground='black',
activeforeground='white').place(x=330, y=380)
self.page.mainloop(0)
def delete_text(self):
self.text.delete(0.0, END)
self.Reply.delete(0.0, END)
def token(self):
Key = '聊天机器人的API key'
Secret = '聊天机器人的secret key'
url = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=' + Key + '&client_secret=' + Secret
result = requests.post(url)
result = result.json()
access_token = result['access_token']
return access_token
def get_adio(self, sec=0):
p = pyaudio.PyAudio()
stream = p.open(format=pyaudio.paInt16,
channels=1,
rate=16000,
input=True,
frames_per_buffer=1024)
wf = wave.open('test.wav', 'wb')
wf.setnchannels(1)
wf.setsampwidth(p.get_sample_size(pyaudio.paInt16))
wf.setframerate(16000)
print('开始说话')
stopflag = 0
conflag = 0
while True:
data = stream.read(1024)
rt_data = np.frombuffer(data, np.dtype('<i2'))
fft_temp_data = fftpack.fft(rt_data, rt_data.size, overwrite_x=True)
fft_data = np.abs(fft_temp_data)[0:fft_temp_data.size // 2 + 1]
# print(sum(fft_data) // len (fft_data))
# 判断麦克风是否停止,判断说话是否结束,#麦克风阀值,默认7000
if sum(fft_data) // len(fft_data) > 7000:
conflag += 1
else:
stopflag += 1
oneSecond = int(16000 / 1024)
if stopflag + conflag > oneSecond: # 如果两种情况的次数超过一帧的大小
if stopflag > oneSecond // 3 * 2: # 其中无声的部分超过一帧的2/3,则停止
break
else:
stopflag = 0
conflag = 0
wf.writeframes(data)
print('停止说话')
stream.stop_stream()
stream.close()
p.terminate()
wf.close()
return 'test.wav'
def say(self,text):
engine = pyttsx3.init()
engine.say(text)
engine.runAndWait()
def StoT(self):
file = self.get_adio()
# 调用对象进行识别,需要为对象传递参数:
# 识别三种格式:wav,pcm,amr
# 语音文件,语音格式,采样频率,识别ID(1573:中文普通话)
Format = file[-3:]
data = open(file, 'rb').read()
result = self.client.asr(data, Format, 16000, {'dev_pid': 1537})
result = result['result'][0]
# print(result)
return result
def adio_run(self):
self.delete_text()
text = self.StoT()
self.text.insert('insert',text)
# print('原文:', text)
reply = self.Unit(text)
self.Reply.insert('insert',reply)
# print('回答内容:', reply)
self.say(reply)
def Unit(self,chat):
url = 'https://aip.baidubce.com/rpc/2.0/unit/service/v3/chat'
url = url + '?access_token=' + self.token()
params = {
'version': '3.0',
'service_id': '聊天机器人的ID',
'log_id': str(random.random()),
'session_id': '',
'request': {'terminal_id': '123456', 'query': chat},
}
response = requests.post(url=url, json=params)
result = response.json()
'result{response[{action[{confidence,say'
# 报错的处理
if result['error_code'] != 0:
return '网页正忙'
result = result['result']['responses'][0]['actions']
reply_act = random.choice([conf for conf in result if conf['confidence'] > 0])
reply = reply_act['say']
# print(reply)
return reply
def back(self):
self.page.destroy()
UnitPage()