ЧАбд
зюНќВЉжїдкзіЕФвЛИіЯюФПжаЩцМАЕНСЫжаЮФNERШЮЮёЁЃЫљвдЕїбаСЫНќаЉФъРДжаЮФNERЩЯгаЪВУДЫЂАёЕФФЃаЭЁЃЗЂЯжСЫСНИіБІВиФЃаЭ:FLATКЭLEBERTЁЃБОЦЊЮФеТНЋМђЕЅНщЩмЯТетСНИіФЃаЭИїздЕФЫМЯы,ВЂеыЖдLEBERTЕФGitHubДњТызівЛаЉЪЕбщЩЯЕФЗжЮіЁЃзюКѓ,ЛЙЛсЬсГівЛаЉNERЪ§ОндіЧПЗНЗЈЁЃ
дЮФСДНг:жаЮФNERЁЊЯюФПжаЕФSOTAгІгУ

вЛЁЂFLAT(ACL2020)
1ЁЂТлЮФБъЬт:ЁЖ?FLAT: Chinese NER Using Flat-Lattice Transformer ЁЗ
2ЁЂТлЮФСДНг:https://arxiv.org/pdf/2004.11795.pdf
3ЁЂGithub:https://github.com/LeeSureman/Flat-Lattice-Transformer
4ЁЂЗНЗЈ
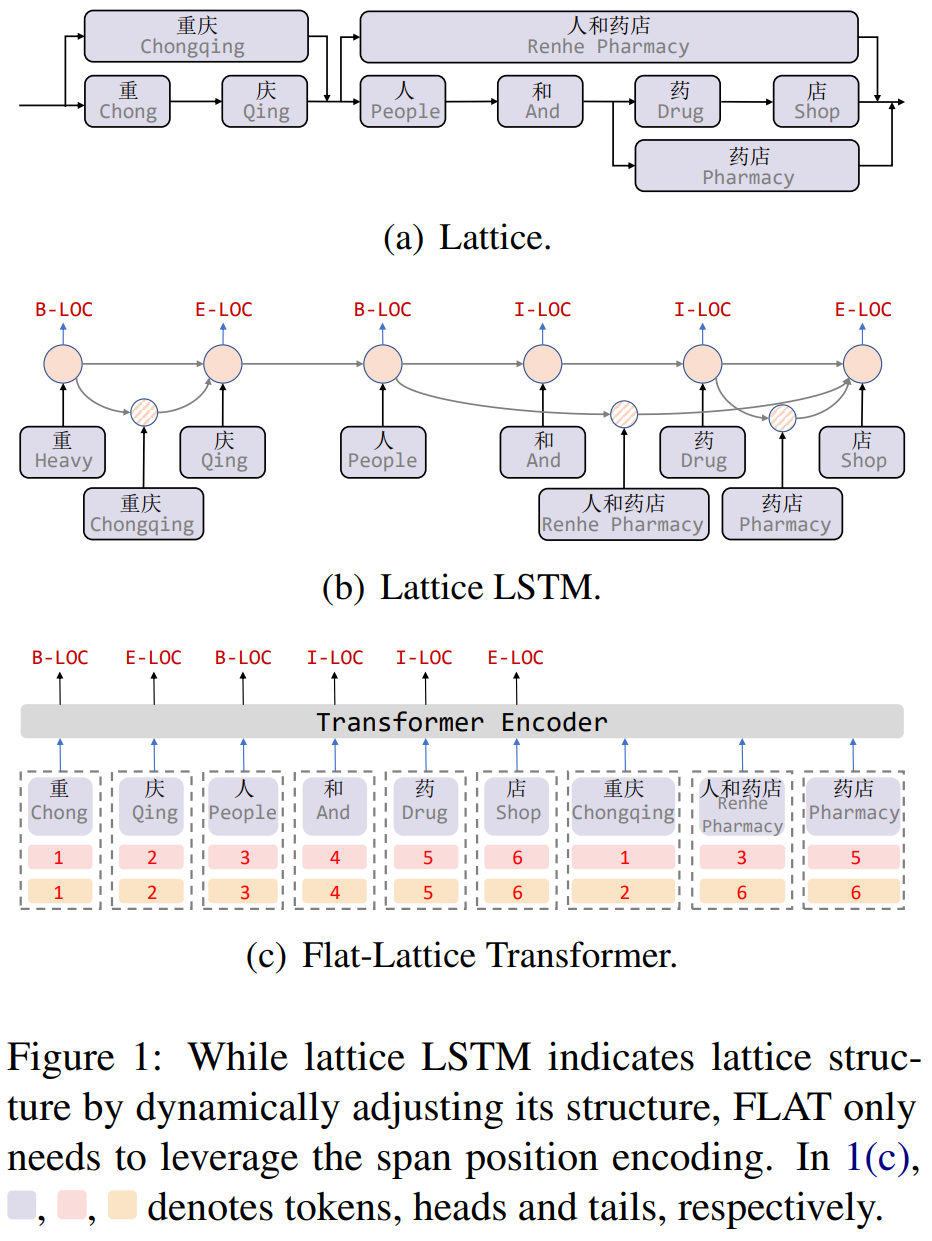
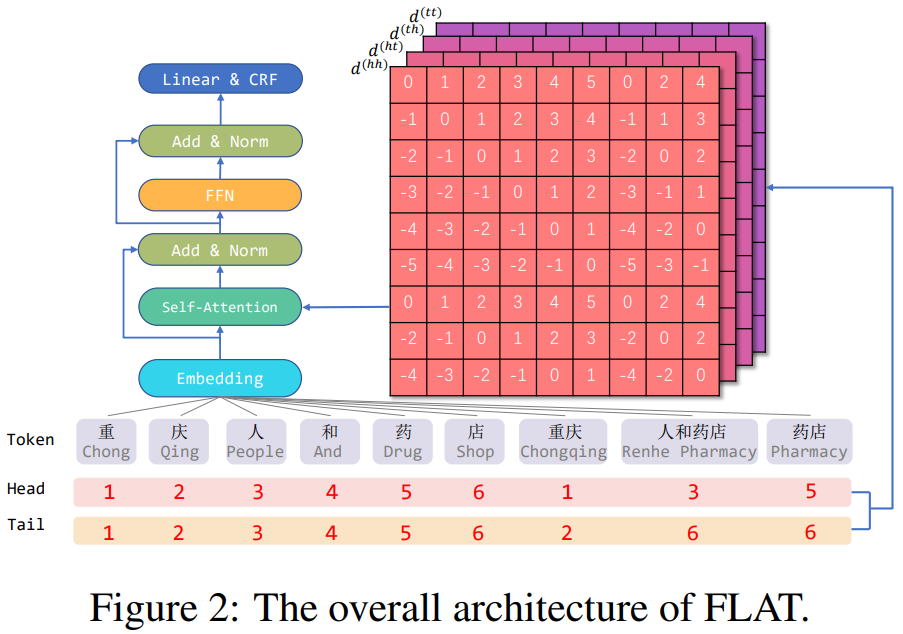
FLATНсЙЙШчЯТЭМFigure1(c)ЫљЪО,УПИізжЗћКЭУПИіЧБдкЕФwordЪЙгУheadКЭtailСНИіЫїв§ШЅБэЪОtokenдкЪфШыађСажаЕФОјЖдЮЛжУ,headБэЪОПЊЪМЫїв§,tailБэЪОНсЪјЫїв§,ЖдгкУПИізжЗћ,headКЭtailЪЧвЛбљЕФ;УПИіwordЪЧВЛвЛбљЕФ,БШШчword ЁАжиЧьЁБ,headЮЊ1,tailЮЊ2,ЫЕУїађСажаЕквЛИізжЗћКЭЕкЖўИізжЗћЮЊЁАжиЧьЁБЁЃ
5ЁЂЬкбЖвєРжЮФБОNER
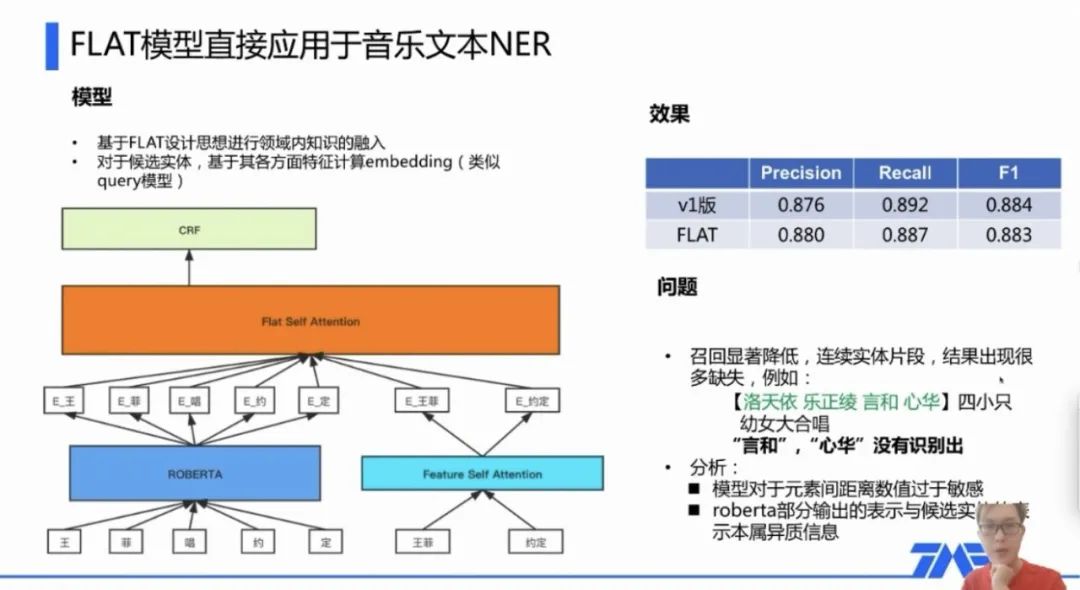
жЎЧАЬ§ЗжЯэБЈИц,ЬкбЖQQвєРждкзівєРжЮФБОNERЪБ,ВЩгУЕФОЭЪЧFLATФЃаЭЁЃЦфNERгХЛЏЗНАИОЭЪЧ:ЩшМЦИќКУЕФСьгђФкжЊЪЖШкШыФЃаЭЁЃЖјИУЯюФПЪЧ2020ФъзіЕФ,ЕБФъСьгђФкжЊЪЖШкШыЕФSOTAБуЪЧACL2020ГЩЙћFLATЁЃИУФЃаЭживЊЫМЯыдкгк:1)КђбЁЪЕЬхКЭдtokenЗХЕНЭЌвЛађСажа;2)жЊЪЖШкШыдкattentionМЦЫуЪБНјааЁЃ
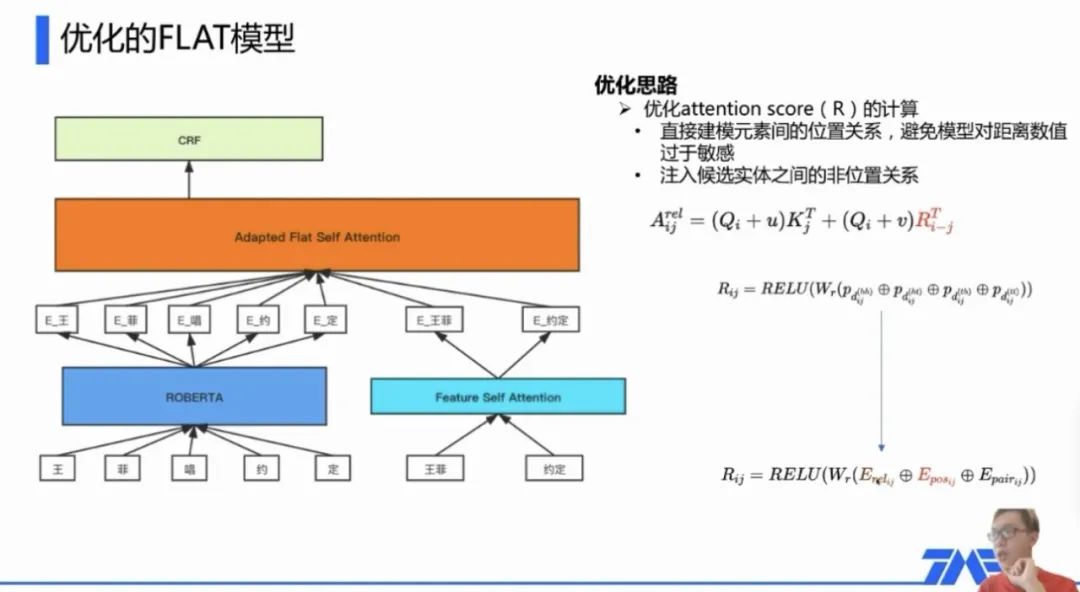
етРяИНЩЯСНеХЕБЪБЕФНиЭМ,ЖдFLATжБНггІгУЕФаЇЙћвдМАШчКЮзігХЛЏ:
ЖўЁЂLEBERT(ACL2021)
1ЁЂТлЮФБъЬт:
ЁЖ Lexicon Enhanced Chinese Sequence Labelling Using BERT Adapter ЁЗ
2ЁЂТлЮФСДНг:https://arxiv.org/abs/2105.07148
4ЁЂЗНЗЈ
ИУЮФдкжаЮФNER,жаЮФДЪадБъзЂ,ЗжДЪШЮЮёЩЯЪЕЯжstate of the artЁЃдкФЃаЭжаЬэМгДЪаХЯЂВЂВЛЫуКБМћ,дкДЫжЎЧАОЭгаКмЖрТлЮФВЩгУСЫетжжЗНЗЈ,ВЂЧвФЃаЭаЇЙћЖМВЛДэ,ЕЋетЦЊТлЮФЯрБШгкжЎЧАЕФТлЮФдкаХЯЂШкКЯЩЯзіСЫвЛаЉИФБфЁЃ
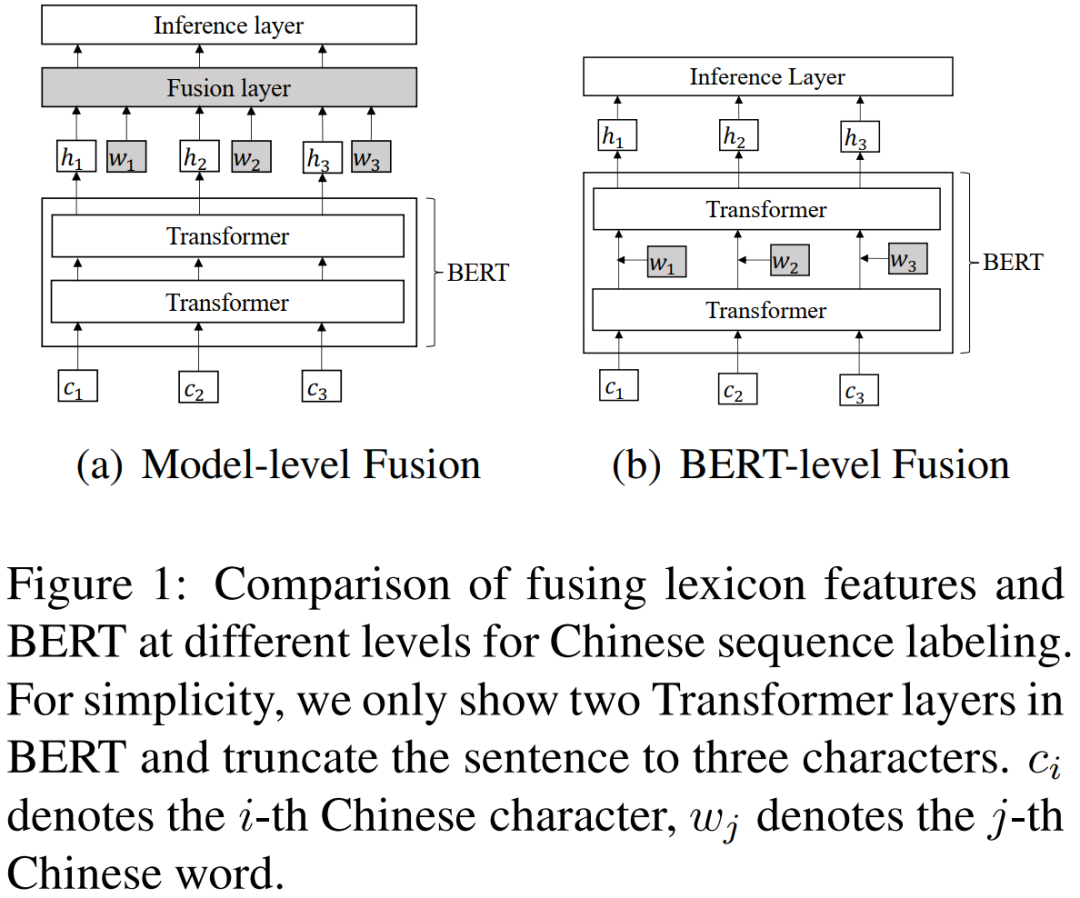
ФЃаЭНсЙЙШчЩЯЫљЪО,зѓБпЪЧЦфЫћФЃаЭЕФаХЯЂШкКЯЗНАИ,ЪЧНЋBERTФЃаЭЕФЪфГіКЭДЪаХЯЂЭЈЙ§вЛИіШкКЯВу(БШШчЯпадВу),ЕУЕНШкКЯКѓЕФЯђСП,етИіЯђСПМШАќКЌСЫзжаХЯЂвВАќКЌСЫДЪаХЯЂ,ЕЋЪЧБОЦЊТлЮФШЯЮЊетбљШкКЯЕФаЇЙћвЛАу,гкЪЧЬсГіСЫСэвЛжжШкКЯЗНАИ,вВОЭЪЧгвБпЕФФЃаЭ,ЯрБШгкзѓБпЕФФЃаЭ,етИіФЃаЭНЋШкКЯаХЯЂВуЗХдкСЫBERTФЃаЭжаЕФФГвЛВуКѓУц,етЪЙЕУзжаХЯЂКЭДЪаХЯЂФмИќКУЕФШкКЯЁЃ
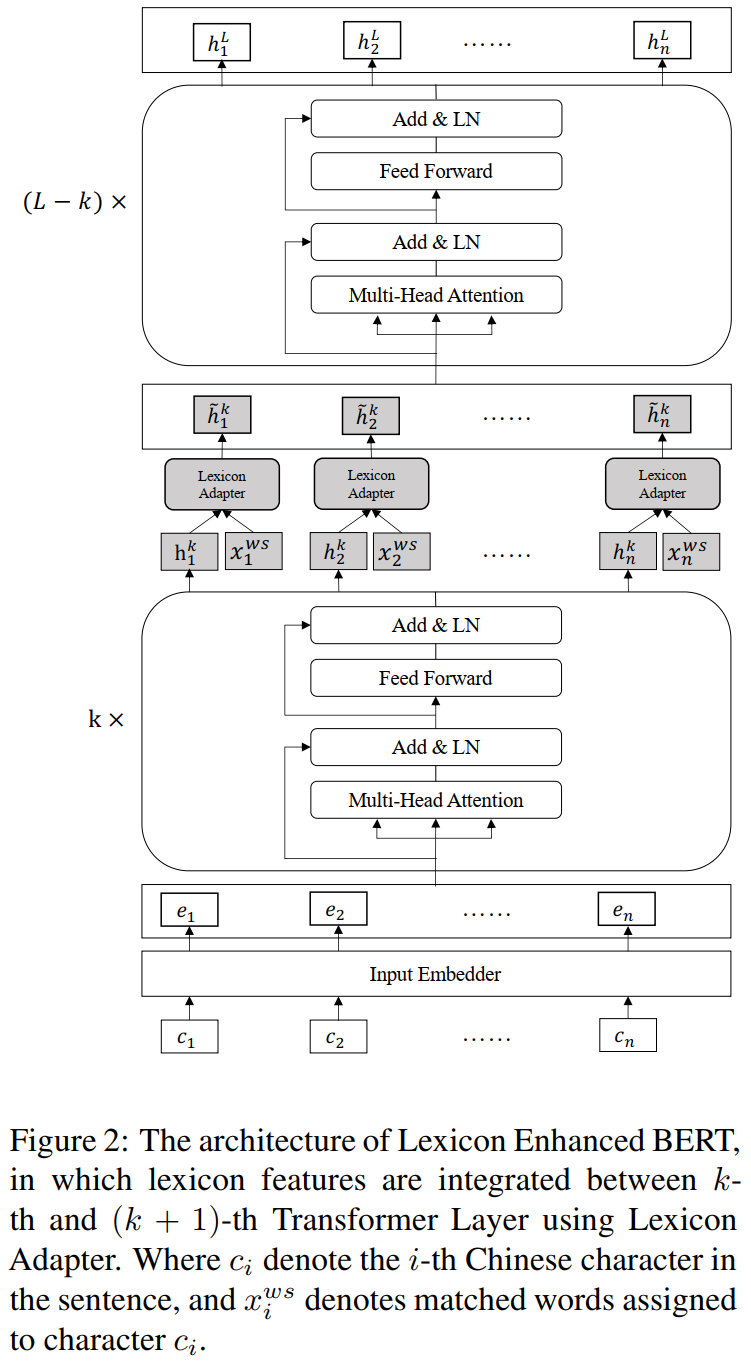
LEBERTНсЙЙЭМШчЩЯЫљЪО,ПЩвдПДзїЪЧLexicon AdapterКЭBERTЕФНсКЯ,ЦфжаLexicon AdapterгІгУЕНСЫBERTЕБжаЕФФГвЛИіTransformerВуЁЃ
ЖдгкИјЖЈЕФжаЮФОфзг
![]()
,НЋЦфЙЙНЈГЩcharacter-words pair sequenceаЮЪН
![]()
ЁЃ
![]()
БэЪОАќКЌзжЗћ
![]()
ЕФДЪЛузщГЩЕФзщКЯ,ЦфжаBERTЕФЪфШыЮЊ
![]()
,МйЩшЕкkВуtransformerЪфГі
![]()
,Lexicon AdapterЧЖШыЕНЕкkВуКЭЕкk+1ВуTransformerжЎМфЁЃ
Ш§ЁЂвЛаЉЙигкLEBERTИДЯжЪЕбщ
1ЁЂЖдЪ§ОнЕФНтЖС
1)бЕСЗЪ§ОнжївЊзщГЩЮФМўШчЯТЭМ,train.jsonКЭ train.char.bmes КЭ labels.txt
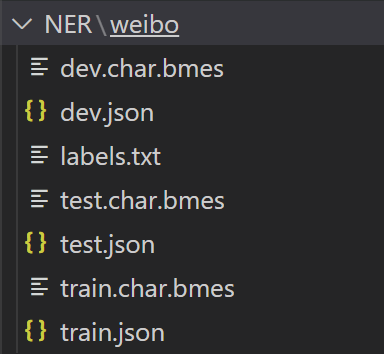
2)labels.txt(БъзЂБъЧЉЮФМў,ВЩгУЕФЪЧIOBESБъзЂЗЈ)

3)train.json

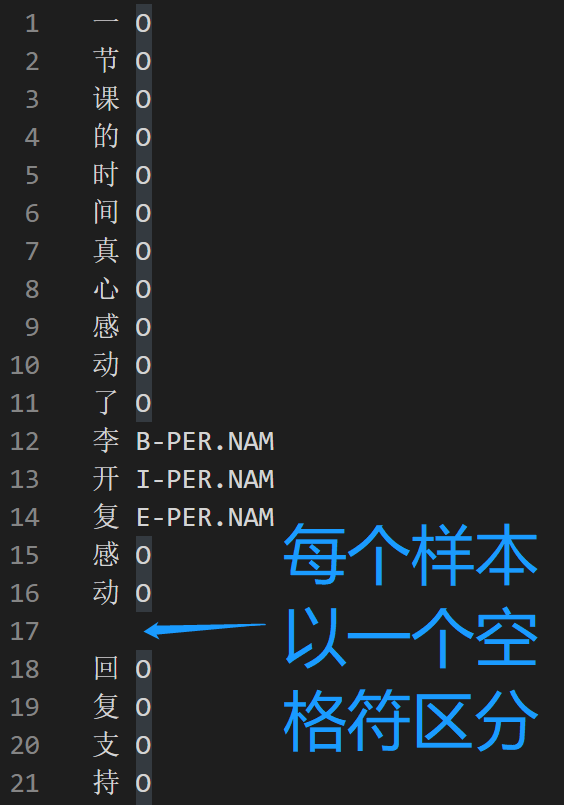
4)train.char.bmes ??ИУЮФМўЖдгІtrain.jsonжаЕФУПвЛЬѕбЕСЗЪ§Он,жЛЪЧtrain.char.bmesашвЊвдЁАchar-БъЧЉЁБЕФЗНЪННјааДцДЂЁЃ
2ЁЂBUGИДЯж
ЁОЬтЭтЛАЁПетПщЮвжЛЬсСНИіБШНЯСюШЫЭЗЬлЕФBUG,БЯОЙдкВЉжїНтОіЫќУЧЪБзіСЫвЛаЉСаЕФбщжЄЪЕбщ,ЯыЯыЛЙЪЧгаБивЊЬсвЛЬс,вдЗНБуКѓУцИДЯжЪЕбщЕФИЮЕлУЧФмЧсЫЩвЛаЉЁЃЕБШЛШчЙћФудкИДЯжЕФЪБКђЛЙгаЪВУДЦфЫћЕФBUG,вВПЩвдЫНаХЮвРВ,вВаэЮвжЊЕРФи!!!
1)ЕквЛИіbug

НтОіЗНАИ:
vocab.pyжаconvert_id_to_itemжаidЛсГЌЙ§idx2itemСаБэЕФЗЖЮЇ,Trainer.pyжаЕк526ааЕФlabel_vocabЁЃДђгЁвЛЯТlabel_vocab.init_vocab(),ФуЛсЗЂЯжitem2idxКЭidx2itemЛсжиИДНјСаБэ,ЕМжТСаБэГЌГіЗЖЮЇЁЃ
2)ЕкЖўИіbug
ФЃаЭбЕСЗЪБдЄВтаЇЙћКмКУ,ЕЋЪЧЕЅЖРгыВтЪдаЇЙћКмВюЕФбщжЄЁЃ
НтОіЗНАИ:АЂУжЭгЗ№,етПЩАбВЉжїелФЅЕФЙЛЧКЕФ,зіСЫNЖрИібщжЄКѓ,ШЗЖЈЪЧЗжВМЪНбЕСЗЕМжТФЃаЭВЮЪ§БЃДцЪБТЉЕєСЫФГМИВуВЮЪ§,жТЪЙЕЅЖРдЄВтМгдиФЃаЭЪБетМИВуВЮЪ§жижУЁЃ
-
дЄВтДњТыбщжЄ:жиаТбЕСЗПЊдДЪ§ОнweiboNER,ВЂНјаабЕСЗНзЖЮдЄВтКЭЕЅЖРМгдиФЃаЭдЄВт,НсЙћЪЧбЕСЗНзЖЮдЄВтаЇЙћКмКУ,ЕЅЖРдЄВтаЇЙћЗЧГЃВюЁЃдЄВтДњТыУЛЮЪЬт;
-
ФЃаЭВЮЪ§бщжЄ:бЕСЗНзЖЮКЭЕЅЖРдЄВтНзЖЮ,ФЃаЭМгдиЪБЕФВЮЪ§ЖдБШЁЃбЕСЗЪБМгдиЕФФЃаЭВЮЪ§ЪЧЭъећЕФ,ЖјЕЅЖРНјаадЄВтЪБФГаЉВуВЮЪ§ЛсБЛжижУ(weigthжижУжЕЮЊ1.ЕФОиеѓЁЂbiasжижУжЕЮЊ0.ЕФОиеѓ);
-
бЕСЗЪБЛсЬсЪО:some weights of the model checkpoint were not used when initializing ЁЃетЪЧе§ГЃЕФ,BERT checkpoint ЪЧгЩ Mask Language model КЭ Next Sentence Predict бЕСЗЕФВЮЪ§,ЖдгкЯТгЮШЮЮё,жЛЛсгУЕНBERTБрТыЦї,вЛаЉШЈжиНЋВЛЛсгУЕНЯТгЮШЮЮёжа;
-
ЗжВМЪНбщжЄ:дФЃаЭбЕСЗЪБНјааСЫЗжВМЪНВЮЪ§ЩшжУ,ФГаЉВЮЪ§БЛЗжВМбЕСЗЕМжТЕЅЖРдЄВтМгдиФЃаЭЪБУЛгаМгдиВПЗжВЮЪ§,НјЖјЕМжТВЮЪ§жижУЁЃШЅЕєЗжВМЪНВЮЪ§НјаабЕСЗКѓ,дкПЊдДЪ§ОнweiboNERЩЯ,бЕСЗЪБдЄВтНсЙћгыЕЅЖРМгдибЕСЗКѓЕФФЃаЭНјаадЄВтНсЙћЪЧвЛжТЕФЁЃ
ЁО run_demo.sh жаШЅЕєЗжВМЪНВЮЪ§:-m torch.distributed.launch --master_port 13517 --nproc_per_node=1 ЁП
ЫФЁЂNERжаЕФЪ§ОндіЧП
1ЁЂЪЕЬхЬцЛЛ
НтОіЪЕЬхВЛОљКтЕФЮЪЬтЁЃгаЕФЪЕЬхдкЪ§ОнжаГіЯжДЮЪ§НЯЩй,ЮвУЧПЩвдЭЈЙ§ЪЕЬхНЯЖрЕФбљБО,НЋИУЯЁШБЪЕЬхЬцЛЛЩЯШЅЁЃБШШчЁАдТОљЪеШыЁБПЩвдЬцЛЛЮЊЁАЦНОљЪеШыЁБЁЃ
2ЁЂЪЕЬхРЉГф
НтОіЪЕЬхРраЭЩйЕФЮЪЬтЁЃБШШчЪЕЬхЁАвЛЭђЁБ,ЮвУЧПЩвдРЉГфЪЕЬхЕФРраЭЮЊЁА1ЭђЁБЛђЁАвМЭђЁБЕШЁЃ
3ЁЂЪЕЬхЙцБм
НтОіЪЕЬхГхЭЛЮЪЬт,ВЛЭЌжаБъЧЉПЩФмЛсЖдгІЕНЭЌвЛжжЪЕЬхЁЃБШШчЖдгкН№ЗўжЪМьЯюФПжа,ЮвУЧЩшжУСЫСНжжБъЧЉMAN(ТњЦк)КЭMONTH(УПИідТ),ЕЋетСНжжБъЧЉЖМКИЧСЫЩйВПЗжЯрЭЌЕФЪЕЬх,ЕМжТNERФЃаЭдкЪЖБ№етРрЪЕЬхЪБзМШЗЖШНЯЕЭЁЃ
4ЁЂЗЧЪЕЬхЦЌЖЮЬцЛЛ
діМгЮФБОдыЩљ,діЧПФЃаЭдкЭЌвЛЗЧЪЕЬхЮФБОжаЪЖБ№ВЛЭЌЪЕЬхЕФФмСІЁЃБШШч:етЪЧжмНмТзЕФИшЧњЦпРяЯуЁЊЁЊ>ЦпРяЯуЪЧжмНмТзГЊЕФЁЃ
5ЁЂЪЕЬхУћШХЖЏ
діМгЪЕЬхдыЩљЁЃдкЪЕЬхЕФЛљДЁЩЯдіМгШХЖЏаХЯЂ,БШШч:ПЩвддкЁАУПвЛЬьЁБЕФЛљДЁЩЯдіМгШХЖЏаХЯЂЁАУПУПЁБ,БфЮЊЁАУПУПУПвЛЬьЁБЁЃ
6ЁЂЪЕЬхбљадРЉді
діМгЖдгІБъЧЉЪЕЬхЕФЗсИЛадЁЃ