����LibSVMѵ����д���ߺ���
һ��LibSVMԭ��
(һ)libSVM���
libSVM��̨��������(Chih-Jen Lin) ����2001�꿪����һ��֧����������,���������ٶ�ͦ��,���Ժܷ���Ķ������������ع顣����libSVM����С,�������,���������,�����ǿ�Դ��,������չ,��˳�ΪĿǰ����Ӧ������SVM�Ŀ⡣
��ʵ��ʹ��libSVM3.18�汾
(��) libSVM ����������
- Java�ļ��� ,��ҪӦ����javaƽ̨;
- Python�ļ���,������������ѡ�Ĺ���,�Ժ����;
- tools�ļ���,��Ҫ�����ĸ�python�ļ�,�������ݼ�����(subset),������ѡ(grid),���ɲ���(easy), ���ݲ�(checkdata);
- windows�ļ��� ���� ����libSVM�ĸ�exe�����,�������õĿ��������,���滹�и�heart_scale,��һ �������ļ�,������ ���±���,���������õġ�
- svm-toy�ļ�,һ�����ӻ��Ĺ���,����չʾѵ�����ݺͷ������,������Դ��,������ij�����windows�ļ�����;
- heart_scale�ļ�,�Dz����õ�ѵ���ļ�
- ����.h��.cpp�ļ����dz����Դ��,���Ա������Ӧ��.exe�ļ�������,����Ҫ����svm.h��svm.cpp�ļ�,svm-predict.c��svm-scale.c��svm-train.c(����һ��svm-toy.c��svm-toy�ļ�����)���ǵ��õ�����ļ��еĽӿں���,��������windows����Ӧ���ĸ�exe��������,����� README �� FAQ �Ǻܺõİ����ļ���
(��) libSVM��ѵ���ı��ĸ�ʽ
���ȱ����˽�libSVM���ݸ�ʽ,��ʽ����:
< label > < index1>:< value1> < index2>:< value2> ��//ʵ��ʹ��ʱ������<>
<���> <����1>:<����ֵ1> <����2>:<����ֵ2>��//ʵ��ʹ��ʱ������<>
ע��:<���>һ���ʾ������������,Ҳ��������1��-1,����1������2�Ǵ�1��ʼ��������,Ҳ����ά��������ֵ1������ֵ2��ʾ���������ԡ�����,��һ������һ��Ů��,��������Ϊ1��Ů��Ϊ-1���������������غ�����,���ʽ����:
+1 1:70 2:178
-1 1:50 2:165
�����ʽ��,70��50�ֱ��������-����,175��165��������-����
(��) ��������svm-scale
svm-scale��������ԭʼ�����������ŵ�,��Χ�����Լ���,һ����[0,1]��[-1,1]�����ŵ�Ŀ����Ҫ�� (1)��ֹij������������С,�Ӷ���ѵ����������ò�ƽ��; (2)Ϊ�˼����ٶ�,��Ϊ�ں˼�����,���õ��ڻ������exp����,��ƽ������ݿ�����ɼ������ѡ�
�÷�:svm-scale [-l lower] [ -u upper]
[-y y_lower y_upper]
[-s save_filename]
[-r restore_filename] filename
����,
[]�ж��ǿ�ѡ��:
-l:�趨��������;
lower:�趨����������ֵ,ȱʡΪ-1 ;
-u�趨��������;
upper:�趨����������ֵ,ȱʡΪ 1;
-y:�Ƿ��Ŀ��ֵͬʱ��������;y_lowerΪ����ֵ,y_upperΪ����ֵ;
-s save_filename:��ʾ�����ŵĹ���Ϊ�ļ�save_filename;
-r restore_filename:��ʾ�������Ѿ����ڵĹ����ļ�restore_filename��������;
filename:�����ŵ������ļ�,�ļ���ʽ����libSVM��ʽ��Ĭ�������,ֻ��Ҫ����Ҫ���ŵ��ļ����Ϳ�����:����(�Ѿ����ڵ��ļ�Ϊ)heart_scale������:svmscale �Cl 0 �Cu 1 �Cs test.rangeheart_scale out.txt,����-l����������,-u����������,-s�DZ����ļ�,������Ϣ������ļ���Ϊtest.range,��Ҫ���ŵ��ļ�ʱheart_scale,�������ŵĽ���ļ�����Ϊout.txt��
(��)ѵ������svm-train
svm-train��Ҫʵ�ֶ�ѵ�����ݼ���ѵ��,�����Ի��SVMģ�͡��÷�: svm-train [options] training_set_file [model_file],����optionsΪ��������,���õ�ѡ���ʾ�ĺ���������ʾ:
-s ����svm����:
0 �C C-SVC ;1 �C v-SVC ; 2 �C one-class-SVM ; 3 �C ��-SVR ; 4 �C n - SVR
-t ���ú˺�������,Ĭ��ֵΪ2
0 �C ���Ժ�:u��v ; 1 �C ����ʽ��: (gu��v+ coef 0)degree
2 �C RBF ��:exp(-��||u-v||2) 3 �C sigmoid ��:tanh(��*u��*v+ coef 0)
-d degree: ���ö���ʽ����degree��ֵ,Ĭ��Ϊ3
-g��: ���ú˺����Цõ�ֵ,Ĭ��Ϊ1/k,kΪ����(����˵������)��;
-r coef 0:���ú˺����е�coef 0,Ĭ��ֵΪ0;
-c cost:����C-SVC����-SVR��n - SVR�дӳͷ�ϵ��C,Ĭ��ֵΪ1;
-n v :����v-SVC��one-class-SVM ��n - SVR �в���n ,Ĭ��ֵ0.5;
-p �� :����v-SVR����ʧ�����е�e ,Ĭ��ֵΪ0.1;
-m cachesize:����cache�ڴ��С,��MBΪ��λ,Ĭ��ֵΪ40;
-e �� :������ֹ���еĿ�����ƫ��,Ĭ��ֵΪ0.001;
-h shrinking:�Ƿ�ʹ������ʽ,��ѡֵΪ0 ��1,Ĭ��ֵΪ1;
-b ���ʹ���:�Ƿ����SVC��SVR�ĸ��ʹ���,��ѡֵ0 ��1,Ĭ��0;
-wi weight:�Ը��������ijͷ�ϵ��C��Ȩ,Ĭ��ֵΪ1;
-v n:n�۽�����֤ģʽ;
model_file:��ѡ��,ΪҪ����Ľ���ļ�,��Ϊģ���ļ�,�Ա���Ԥ��ʱʹ�á�
ѵ������֮��,���ǾͿ��Զ����ݽ���Ԥ����,����,ѵ��������δ�������Ų���,������Ҫ��һ���Ż���LibSVM�ṩ���Ż�����,����tools�ļ���,���а�����grid.py�ļ���easy.py�ļ�,grid�ļ��������ѵ��������ѡ����Ѳ���ֵ,��easy���ṩ�˶������ļ����ˡ�һ��������,�Ӳ�����ѡ,���ļ�Ԥ�⡣
���� Windows���SVMʵ��
1.���Ƚ�ѹ���߰�,�мǹ��߰���ѹ��Ӣ�ĵ�Ŀ¼,��Ϊ�ܶ�DOS����������;
2.����SVM��ִ�б����в���,���Ա�����DOS������ִ���ļ�,�����������������,�����ȴ�MS-DOS,Win+R;
3. ��λ��SVM�е�windowsĿ¼��,DOS�������¼1,�ҵ�Ŀ¼��:F:\����\libsvm-master\libsvm-master\windows>;
4.����ѵ��,��������:svm-train ��/heart_scale train.model,����heart_scale��ѵ���ı�����LibSVM�Դ��ġ�train.Model��ѵ������� ���ı�,���Ȩϵ������֧��������
5.���к�,������DOS���濴�����½��:

����,#iter��������,nu
����ѡ��ĺ˺������͵IJ���,objΪSVM�ļ�ת��Ϊ�Ķ��ι滮���õ�����Сֵ,rhoΪ�о�������ƫ����b,nSV
Ϊ��֧����������(0<a<c),nBSVΪ�߽��ϵ�֧����������(a=c),Total
nSVΪ֧�������ܸ���(����������˵,��Ϊֻ��һ������ģ��Total nSV = nSV,���Ƕ��ڶ���,����Ǹ�������ģ�͵�nSV֮��)��
�����β������ͼ�����
1.��LibSVM·�����ҵ�windowsĿ¼�µ�svm-toy.exe
2.���Ƶ�
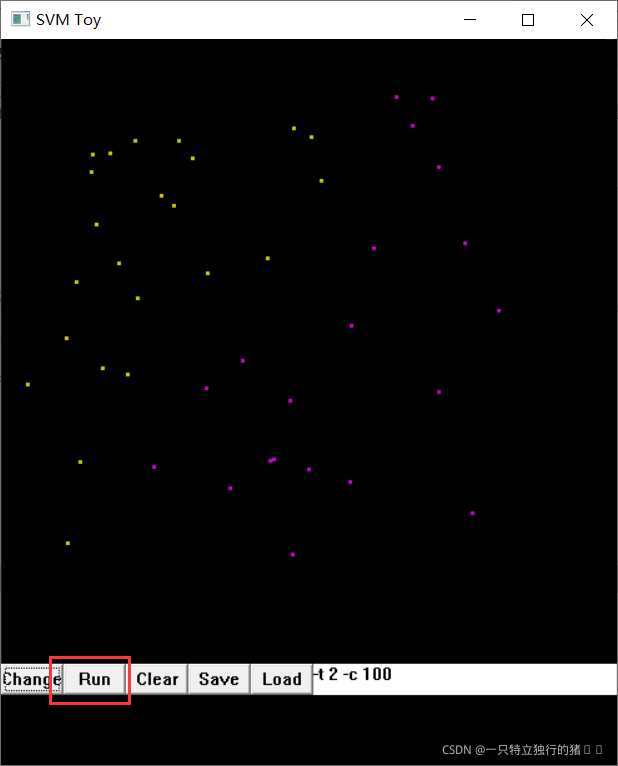
3.�������

�ġ�Sklearn+matlab����SVM���ߺ���
(һ)������
1.��libsvm�ļ��µ�windows�ļ������svm-toy����
2.�ڳ����н����ֹ��������ݲ���������
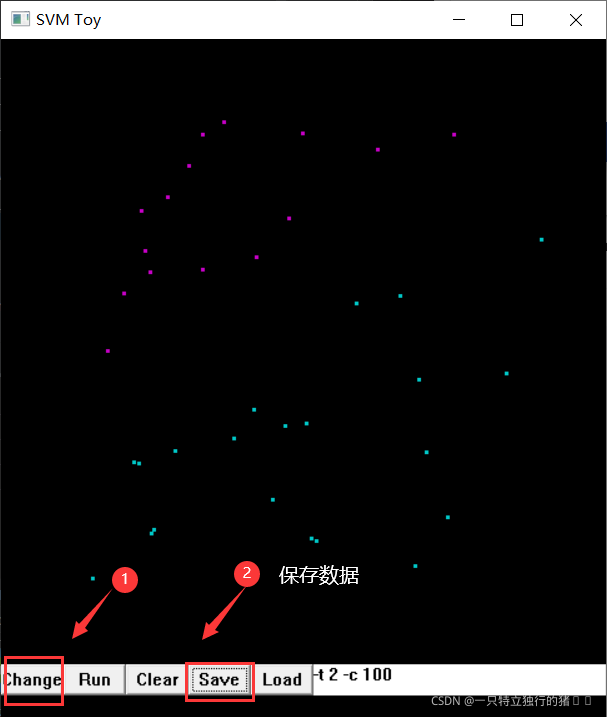
(��)����ʵ��
1.��IDEA,�����ļ�����
2.�½���Test������ѵ��
��������
package test;
import java.io.IOException;
import java.sql.SQLOutput;
import test.svm_train;
public class Test {
public static void main(String args[]) throws IOException {
//��������Լ�����ģ���ļ�·��
String filepath = "F:\\IDEAproject\\test\\";
/**
* -s ����svm����:Ĭ��ֵΪ0
* 0�C C-SVC
* 1 �C v-SVC
* 2 �C one-class-SVM
* 3 �C��-SVR
* 4 �C n - SVR
*
* -t ���ú˺�������,Ĭ��ֵΪ2
* 0 --���Ժ�
* 1 --����ʽ��
* 2 -- RBF��
* 3 -- sigmoid��
*
* -d degree:���ö���ʽ����degree��ֵ,Ĭ��Ϊ3
*
* -c cost:����C-SVC����-SVR��n - SVR�дӳͷ�ϵ��C,Ĭ��ֵΪ1;
*/
String[] arg = {"-s","0","-c","10","-t","0",filepath+"my.txt",filepath+"line.txt"};
System.out.println("----------------����-----------------");
//ѵ������
svm_train.main(arg);
arg[5]="1";
arg[7]=filepath+"poly.txt";//����ļ�·��
System.out.println("---------------����ʽ-----------------");
svm_train.main(arg);
arg[5]="2";
arg[7]=filepath+"RBF.txt";
System.out.println("---------------��˹��-----------------");
svm_train.main(arg);
}
}
(��)��������
1.��������
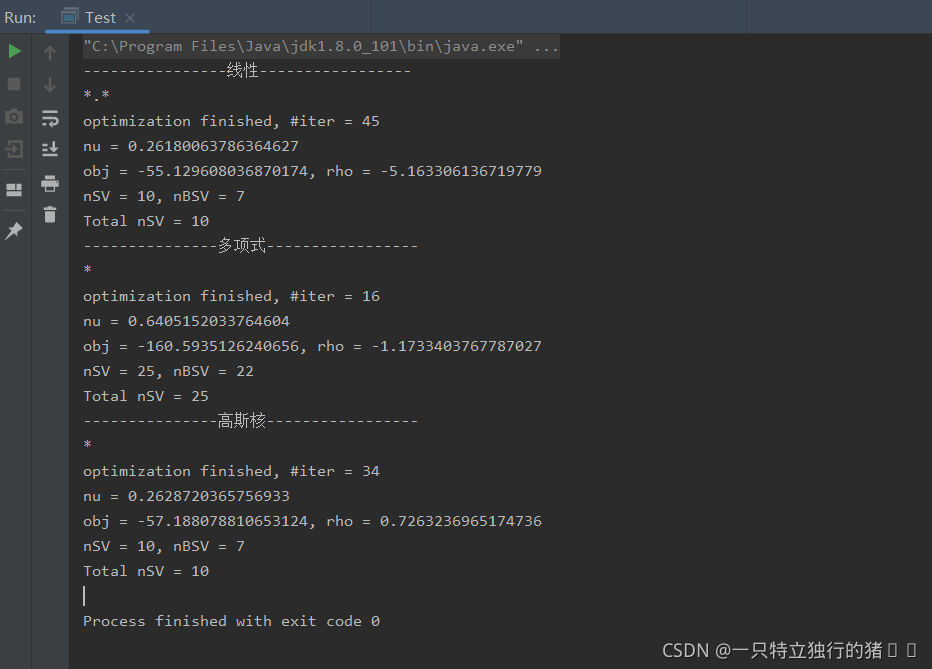
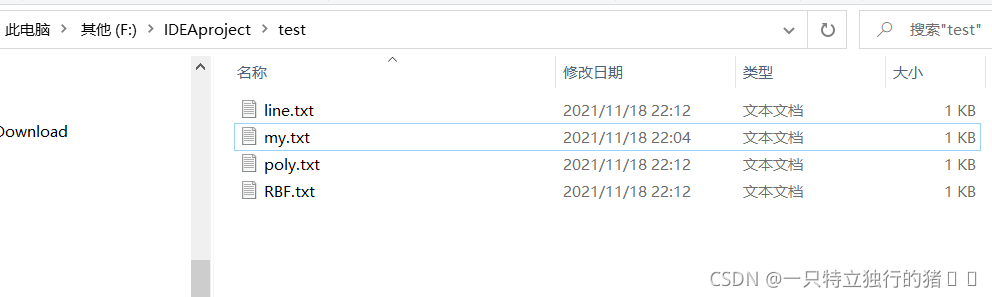
2.����ļ�
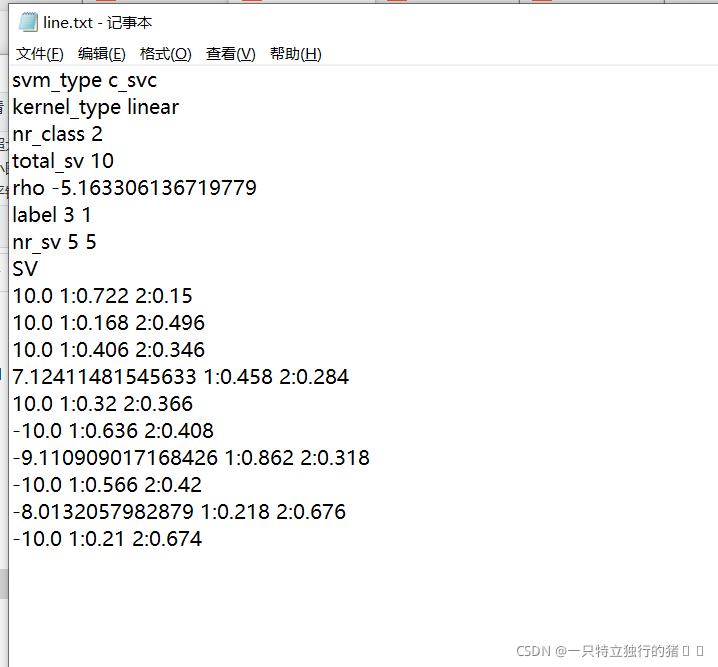
- my.txtѵ������
- line.txt����ģ��
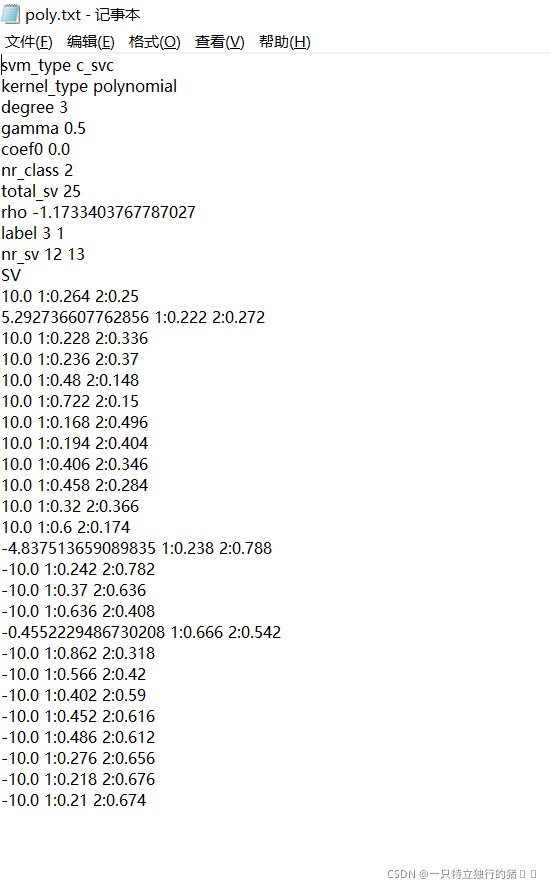
- poly����ʽģ��
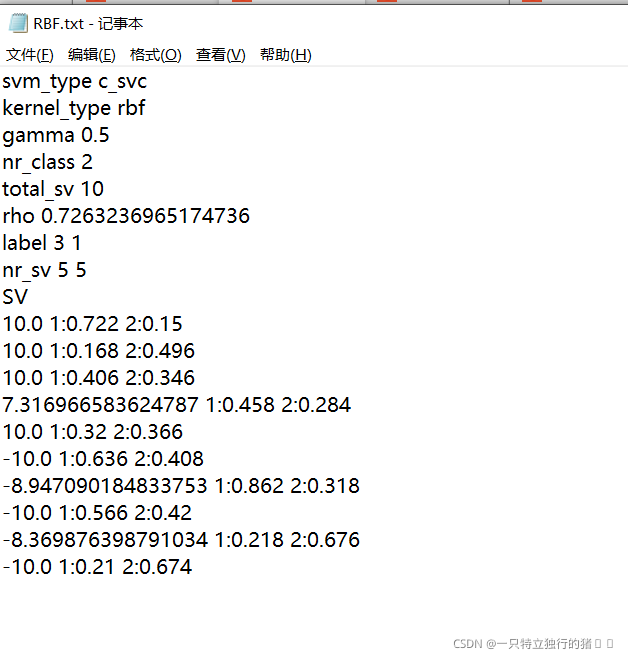
- RBF��˹��ģ��
3.���ģ��
����ģ��
����ʽģ��
��˹��ģ��
(��)���ߺ���
���ݹ�ʽf(x)=wT*x+b�Լ�ģ�����ݿ���������յľ��ߺ�����
- wTΪ������ת�þ���,��Ϊģ�������е�SV
- bΪƫ�ó���,��Ϊ����ģ���е�rho
�塢�ܽ�
����ʵ���˽��� libSVM�ı�����ԭ����ѵ���ı��ĸ�ʽ��,�����libsvm�����β�����ݼ�ͼ��,�Լ�libSVM����ͼ��ľ��巽����