Task02机器学习基础
机器学习
- 机器学习可以分为有监督、无监督 和 强化学习
- 常见数据集
MNIST、CIFAR10、CIFAR100等
常用数据集可以使用pytorch、tensorflow等导入。
比如使用CIFAR10数据聚集
import torchvision.transforms as transforms
import torchvision
train_dataset = torchvision.datasets.CIFAR10(root=r'./data/',
train=True,
transform=transforms.ToTensor(),
download = True)
但是昨天发现直接下载有点难,可以提前下载好,然后再从本地地址下载。找到的解决方案是看的这位大佬的文章:下载CIFAR10数据集
误差分析
只记录几个我容易混淆的概念
- 测试误差:模型在测试集上的误差
- 泛化误差:模型在总体样本上的误差
泛化误差分析
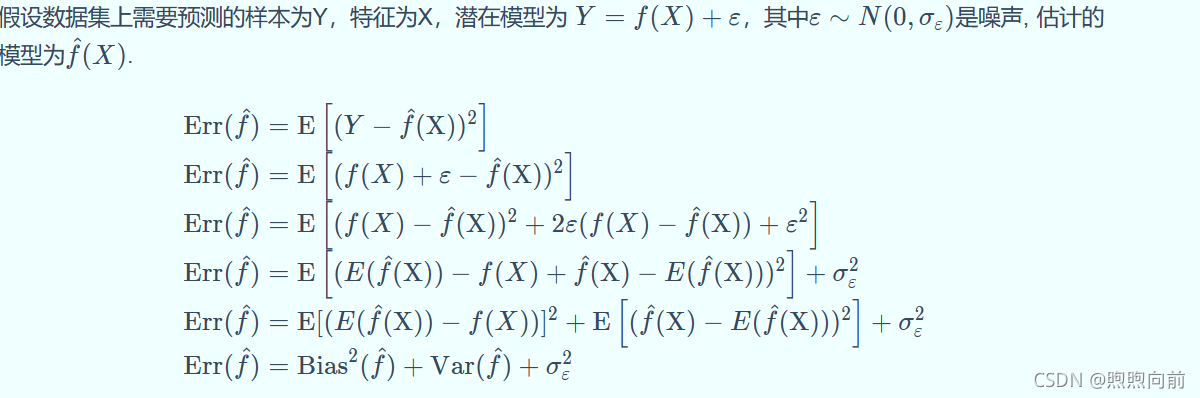
泛化误差可以分解为偏差、方差和噪声之和。
-
偏差:反映模型在 样本上的期望输出与真实标记之间的差距,即模型本身的精准度,反映的是模型本身的拟合能力。 偏差大,对应着模型的拟合较差。
-
方差:反映了模型在不同训练数据集下学得的函数的输出与期望输出之间的误差,即模型的稳定性,反映的是模型的波动情况。
周志华老师西瓜书上说:方差度量了同样大小的训练集的变动所导致的学习性能的变化,刻画了数据扰动所造成的影响。
所以方差大,模型就容易受到数据扰动,数据发生的轻微扰动都会导致学习器发生显著变化。 -
欠拟合:高偏差,低方差
解决方案:
- 寻找更好的特征;
- 增加特征数量;
- 选择更加复杂的模型;
- 过拟合:低偏差,高方差
解决方案:
- 增加训练样本数量;【这一条我不理解。参考这个文章,因为数据量小很容易导致过拟合,所以反过来如果过拟合了,可以考虑增加样本数量】;
- 减少特征维数;
- 加入正则化项
交叉验证
分成10折或者5折比较多,留一法适合数据量小的情况。
可以直接用sklearn中的KFold进行交叉验证。
import numpy as np
from sklearn.model_selection import KFold
import pandas as pd
# 假设数据X_train,y_train
y_train = np.array([1,0,1,1,0])
X_train = pd.DataFrame([[1,2],[3,4],[5,6],[7,8],[9,10]])
# 五折交叉验证
K = 5 # 折数改这里
folds = KFold(n_splits= K, shuffle = True, random_state= 0) # 设置random_state,是为了每次都可以重复
# 这是把全部的训练数据拆分成了K份,K-1 份测试,1份验证
for trn_idx, val_idx in folds.split(X_train,y_train):
train_df, train_label = X_train.iloc[trn_idx,:],y_train[trn_idx]
valid_df, valid_label = X_train.iloc[val_idx,:],y_train[val_idx]
#X_train可以使用iloc, 注意y_train必须使用np.array()转化一下才能使用列表作为索引
接着在这个for循环里就可以将训练集和验证集分别用于训练和验证了
有监督学习
- 线性回归
- 逻辑回归
- 支持向量机
- 决策树
- 随机森林
无监督学习
- 聚类
- 降维
参考:1. Datawhale31期的机器学习基础 。 蓝色截图也来源于该教程。
2. 这个文章回答了我对于过拟合为什么要增加数据集的问题
3.这个文章解决了我pytorch下载CIFAR10的问题
4. 周志华《机器学习》