前言
利用Python爬取IMDB电影。废话不多说。
让我们愉快地开始吧~
开发工具
Python版本: 3.6.4
相关模块:
requests模块;
random模块;
bs4模块;
以及一些Python自带的模块。
环境搭建
安装Python并添加到环境变量,pip安装需要的相关模块即可。
一来豆瓣作为爬虫入门,各种大牛的深入分析已趋于完美;另一方面随着中国电影工业的发展,我们需要将视角转向国际市场,通过数据分析,了解一下外国人比较感兴趣的电影。
思路分析
IMDB top250主页
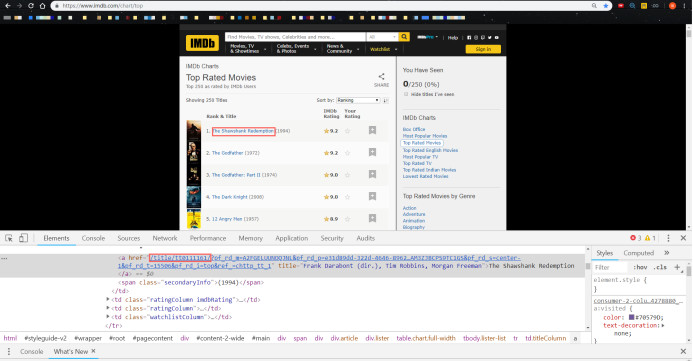
IMDB电影详情页 (1)
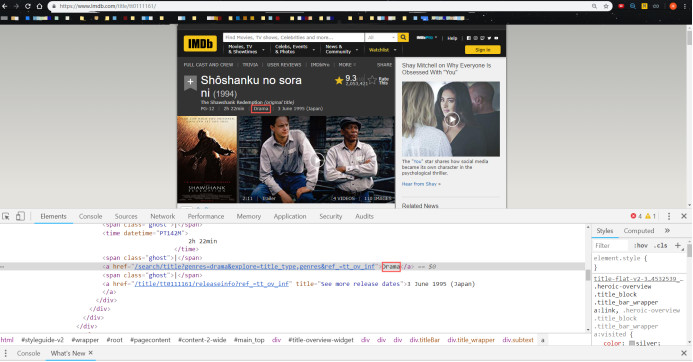
IMDB 电影详情页 (2)
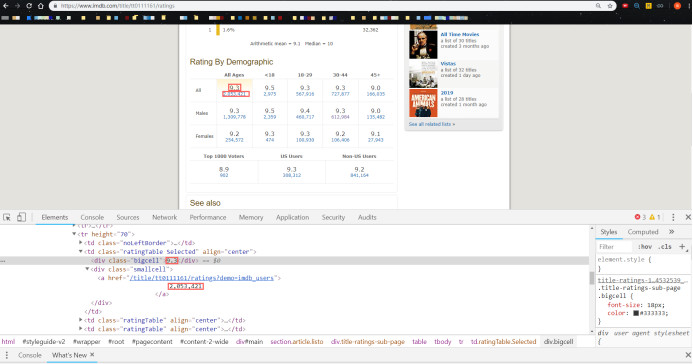
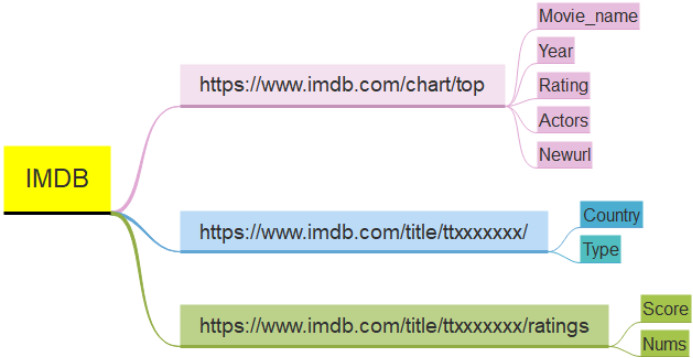
基于以上网页构造,我们发现只需得到每个电影的详情页编码(唯一),通过2次“蛙跳”,实现详情页(1)(2)导出国家&类型,分数&人数的信息的获取。便于理解,爬取思维导图如下:
爬虫代码
IMDB top250主页
#导入库-------------------------------------------
from urllib import request
from chardet import detect
from bs4 import BeautifulSoup
import pandas as pd
import time
import random
#获取网页源码,生成soup对象-------------------------
def getSoup(url):
with request.urlopen(url) as fp:
byt = fp.read()
det = detect(byt)
time.sleep(random.randrange(1,5))
return BeautifulSoup(byt.decode(det['encoding']),'lxml')
#解析数据-------------------------------------------
def getData(soup):
#获取评分
ol = soup.find('tbody', attrs = {'class': 'lister-list'})
score_info = ol.find_all('td',attrs={'class':'imdbRating'})
film_scores = [k.text.replace('\n','') for k in score_info]
#获取评分、电影名、导演?演员、上映年份、详情网页链接
film_info = ol.find_all('td',attrs={'class':'titleColumn'})
film_names = [k.find('a').text for k in film_info]
film_actors = [k.find('a').attrs['title'] for k in film_info]
film_years = [k.find('span').text[1:5] for k in film_info]
next_nurl = [url2 + k.find('a').attrs['href'][0:17] for k in film_info]
data=pd.DataFrame({'name':film_names,'year':film_years,'score':film_scores,'actors':film_actors,'newurl':next_nurl})
return data
IMDB top250电影详情页
#获取详情页数据-------------------------------------------
def nextUrl(detail,detail1):
#获取电影国家
detail_list = detail.find('div',attrs={'id':'titleDetails'}).find_all('div',attrs={'class':'txt-block'})
detail_str = [k.text.replace('\n','') for k in detail_list]
detail_str = [k for k in detail_str if k.find(':')>=0]
detail_dict = {k.split(':')[0] : k.split(':')[1] for k in detail_str}
country = detail_dict['Country']
#获取电影类型
detail_list1 = detail.find('div',attrs={'class':'title_wrapper'}).find_all('div',attrs={'class':'subtext'})
detail_str1 = [k.find('a').text for k in detail_list1]
movie_type=pd.DataFrame({'Type':detail_str1})
#获取以组划分的电影详细评分、人数
div_list = detail1.find_all('td',attrs= {'align': 'center'})
value = [k.find('div',attrs= {'class': 'bigcell'}).text.strip() for k in div_list]
num = [k.find('div', attrs={'class': 'smallcell'}).text.strip() for k in div_list]
scores=pd.DataFrame({'value':value,'num':num})
return country,movie_type,scores
结果展示
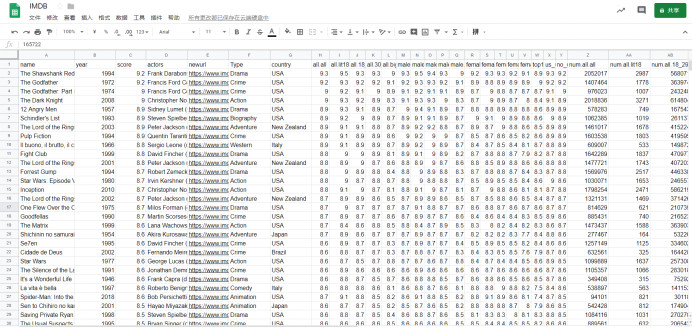
数据分析
影片类型对比
首先来看一下各个类型的影片占比:
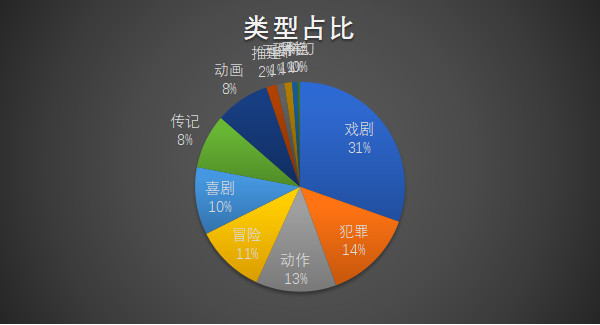
Top250电影的类型占比,前三名分别是喜剧、犯罪与动作。
紧张刺激的情绪、张弛有度的情节,最能带给影迷带来记忆深刻的观影体验。
下面再来看下各个类型的影片的得分对比
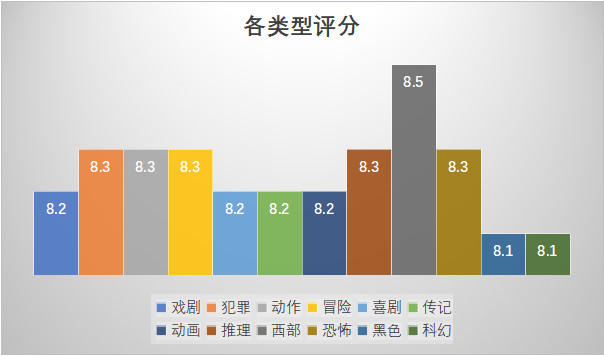
从类型来看,西部片一骑绝尘,究其原因可能与受众人群小、爱好者狂野奔的性格易给高分有关。其次,犯罪、动作、冒险、推理、恐怖题材也易出较高评分
年份对比
首先我们看下TOP250电影的所属年份
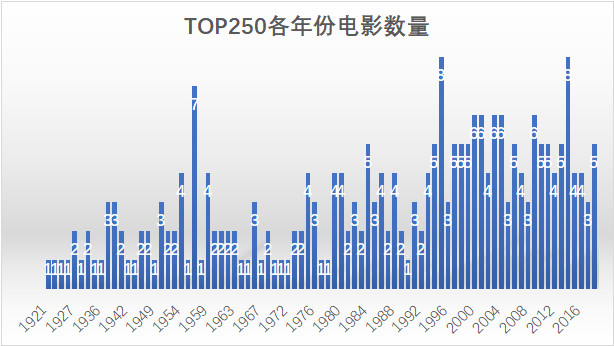
Top250电影中,1957、1995、与2014年电影较多,而1975年后,上榜电影有明显增加的趋势,这可能与电影工业的日趋成熟有关。
至于1995年,熟悉电影的小伙伴可能知道,1995年是世界电影100周年,无数电影天才抱着献礼的想法,在这一年诞生了他们伟大的作品,我们较为熟悉的有《肖申克救赎》、《阿甘正传》、《低俗小说》、《四个婚礼与一个葬礼》、《七宗罪》、《狮子王》等。
同时我们看下各个年份电影的评价分数
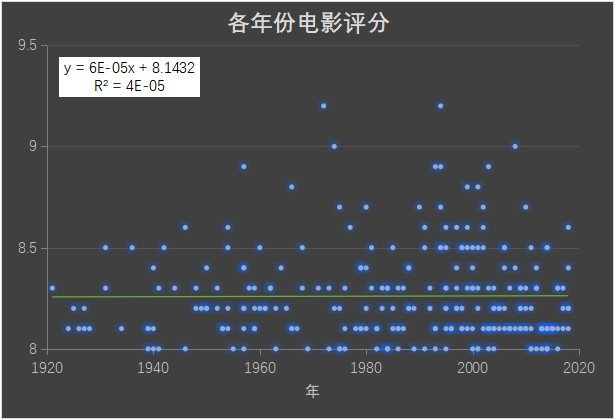
比较电影年代评分,并无发现明显上升或下降趋势,可见电影艺术并不会随时间而失去自身价值。对于电影,技术不是第一位的,感情共鸣的因素占更大权重;哪部电影最好看?答案就在我们每个人心中。
国家对比
我们看下各个国家及地区在TOP250电影中的占比情况
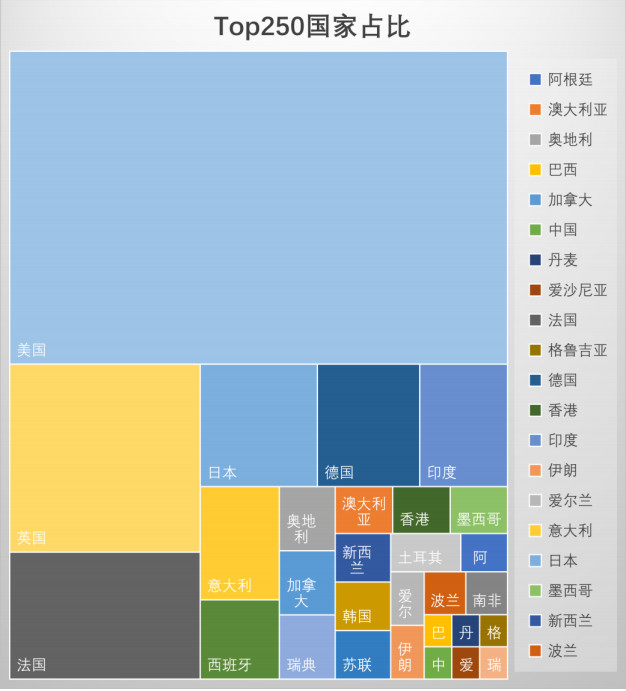
这个数据比较有趣,有点像诺贝尔奖,美国电影占据半壁江山,其余国家瓜分剩下的蛋糕。排名前几位的分别是英国、法国、日本、德国。而中国,唯一上榜的电影只有一部――《花样年华》。
如果是西方主流价值观的原因,同样作为东方文化代表的邻国日本,却有16部电影上榜,可见西方价值观并不能成为中国电影上榜少的主要原因。虽然近几年中国不乏有《大鱼海棠》、以及刚最新上映的《流浪地球》这样高质量的作品上线,但是在国际市场仍反响平平。我相信电影是有共同语言的,也真的有普世价值观这样的东西。如何打造国际化电影工业,给世界人民讲故事,是中国电影人接下来需要探索的课题。
导演对比
我们一起看下那些在TOP250榜单中,最常出现的导演们
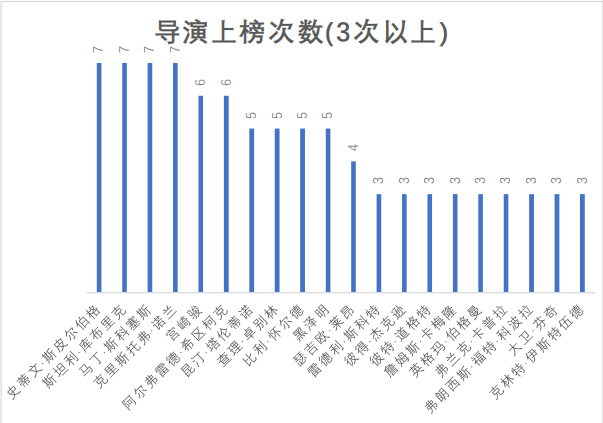
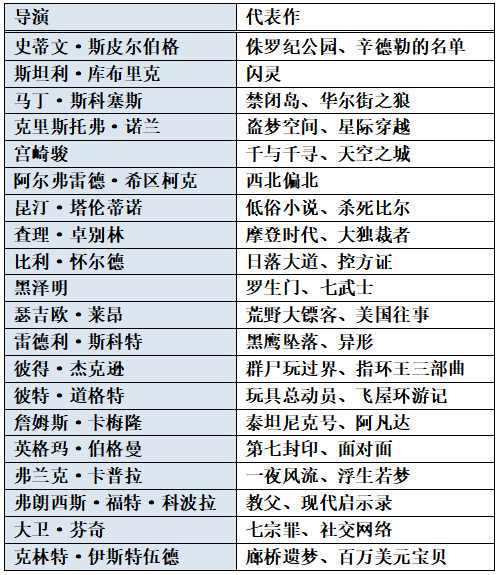
电影界的诺贝尔开奖啦,一起来看看有哪些作者上榜。鉴于大家对外国导演名可能不太熟悉,这里做了一个导演-代表作做对照表,值得注意的是,雷德利?斯科特、詹姆斯?卡梅隆、大卫?芬奇分别执导了电影《异形1》《异形2》《异形3》,一部《异形》出3个上榜导演,可见其系列影响力。
人群对比
首先我们看下不同人群的评分情况
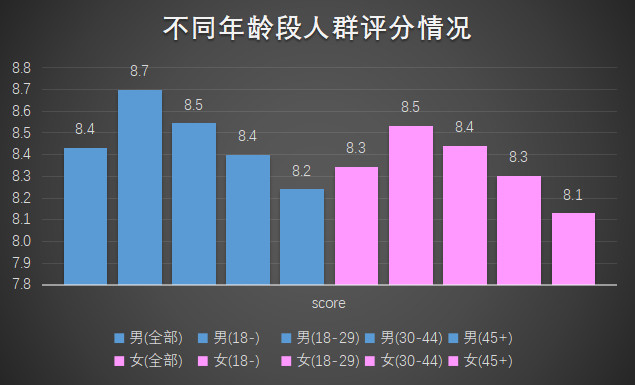
从性别维度来看,男性比女性给容易给出高分。另一方面,从年龄段侧看,无论男女,未成年人员最易给出高分,随着年龄增加,评分愈加犀(è)利(dú),超过45岁的人群,给出的分数是最低的。是否历经沧海,坚硬的心就越难被打动?又或许见多识广,才能公正客观的评价一部电影?也许可以就此问题研究一下,如《电影节评委年龄层的科学配置方法》。
然而知道了评分情况,我们也需要去了解下各类人群的占比情况
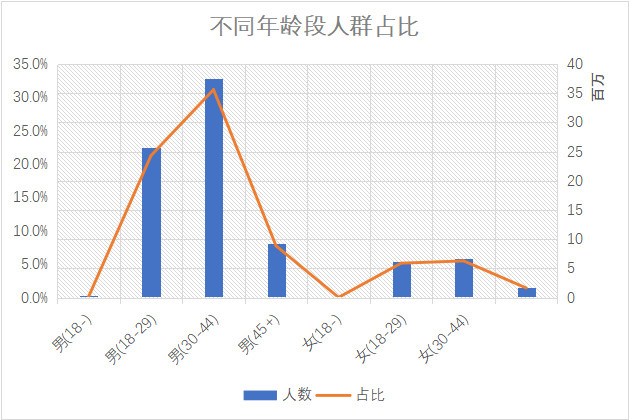
虽然“老叔叔”、”老阿姨”们的评分偏低,但是一部电影的口碑高低不用太担心这类人群。因为数据告诉我们,满足30-44以及18-29这两个年龄段的中青年男性口味,电影口碑肯定差不了。从近些年《战狼》、《红海行动》,这类战争动作片均取得不错的口碑中,对评分机制可略知一二。
类型、年龄与评分的关系
首先我们用热力图来看下各个人群对不同类型电影的评分情况
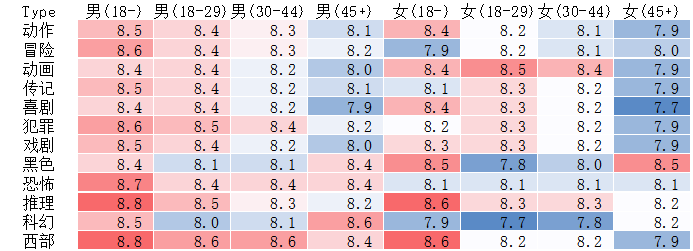
不同年龄群,对电影类型的偏好是不同的。如未成年男性、女性,对推理、西部片表现出浓厚兴趣,而45以上的男性、女性,分别对科幻、黑色电影类型钟爱。
评分的高低也需要结合占比进行综合分析
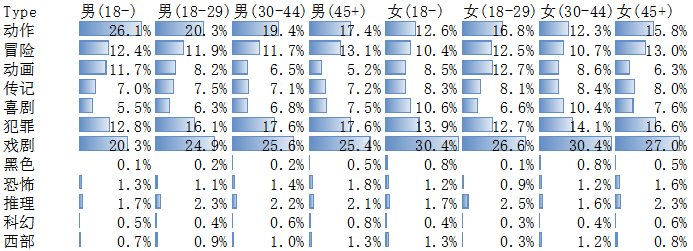
这次我们将数据粒度细化至各年龄层,结合各年龄段评分,以下我们给出各年龄层在TOP250榜中的推荐电影。
电影推荐
未成年男性(<18)

18-29岁男性

30-44岁男性

45+男性

未成年女性(<18)

18-29岁女性

30-44岁女性

45+女性

以上是根据IMDBtop250数据推荐的电影,如果有不符合的情况,在这里说声抱歉。毕竟美国人民的喜好和中国还是有一定区别的。