shuffleNet-V1论文阅读及代码实现
前言
shufflenetV1是卷积神经网络向轻量化发展的又一方向,是继Mobilenet的轻量化网络。
一、论文阅读总结
论文地址
Tricks: Group Convolution在1*1卷积上的应用;channel shuffle提高通道之间的信息传递;
1.Channel Shuffle
在ResNeXt中只考虑了33卷积的群卷积模式,使大部分运算量集中于11卷积(pointwise conv)。因此本文对1*1卷积也采用群卷积,保证每个卷积操作只作用于少量通道,保证通道连接稀疏性,减少计算量。
什么是群卷积(group convolution)?
假设上一层的输出feature map有N个,即通道数channel=N,也就是说上一层有N个卷积核。再假设群卷积的群数目M。那么该群卷积层的操作就是,先将channel分成M份。每一个group对应N/M个channel,与之独立连接。然后各个group卷积完成后将输出叠在一起(concatenate),作为这一层的输出channel。
2.Group Conv
若在全网络采用群卷积的方法,其对应每一个通道输出的特征图只与少数几个输入通道的特征图有关,造成了信息的阻塞。因此需要将N个(通道数)输入特征图分为多个子组,在子组中选出不同的特征图组成新的子组送往下一个群卷积,其示意图如图1所示。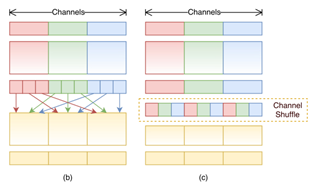
3.消融实验
1)群卷积的通道数(g=1,2,3,4,8)
在1*1卷积上采用群卷积比不采用要强,在某些模型(如ShuffleNet 0.5×),当组数变大(如g= 8)时,分类评分达到饱和甚至下降。随着组数的增加(因此更宽的特征映射),每个卷积滤波器的输入通道变得更少,这可能会损害表示能力。对于较小的模型,如ShuffleNet 0.25×,群组号码往往会得到更好的结果,这表明更大的特征地图为较小的模型带来更多的好处。
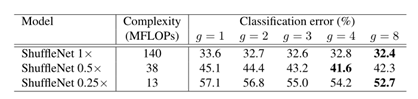
2)比较shuffle和no shuffle:
通道shuffle在不同的设置下都能提高分类分数。特别是当组数较大时(如g= 8),采用信道随机的模型表现明显优于同类模型,这说明了跨组信息交换的重要性。

二、代码实现
1.shuffle实现
代码如下:
class shuffle(nn.Module):
def __init__(self,group=2):
super(shuffle, self).__init__()
self.group=group
def forward(self,x):
"""shuffle操作:[N,C,H,W] -> [N,g,C/g,H,W] -> [N,C/g,g,H,w] -> [N,C,H,W]"""
num,channel,height,width=x.size()
x=x.view(num,self.group,channel//self.group,height,width)
x=x.permute(0,2,1,3,4)
x=x.reshape(num,channel,height,width)
return x
2.瓶颈模块实现
代码如下:
class bottleblock(nn.Module):
def __init__(self,in_channel,out_channel,stride,group):
super(bottleblock, self).__init__()
self.stride=stride
if in_channel==24:
group=1
else:
group=group
self.conv1_with_group=nn.Sequential(nn.Conv2d(in_channels=in_channel,out_channels=out_channel//4,kernel_size=1,stride=1,groups=group,bias=False),
nn.BatchNorm2d(out_channel//4),
nn.ReLU(inplace=True))
self.shuffle=shuffle(group)
self.conv2_with_depth=nn.Sequential(nn.Conv2d(in_channels=out_channel//4,out_channels=out_channel//4,stride=stride,kernel_size=3,groups=out_channel//4,padding=1,bias=False),
nn.BatchNorm2d(out_channel//4))
self.conv3_with_group=nn.Sequential(nn.Conv2d(in_channels=out_channel//4,out_channels=out_channel,kernel_size=1,stride=1,groups=group),
nn.BatchNorm2d(out_channel))
if stride==2:
self.shortcut=nn.AvgPool2d(stride=stride,kernel_size=3,padding=1)
else:
self.shortcut=nn.Sequential()
def forward(self,a):
x=self.conv1_with_group(a)
x=self.shuffle(x)
x=self.conv2_with_depth(x)
x=self.conv3_with_group(x)
residual=self.shortcut(a)
if self.stride==2:
return F.relu(torch.cat([x,residual],1))
else:
return F.relu(residual+x)
3.shufflenet网络实现
代码如下:
class shufflenet(nn.Module):
def __init__(self,num_class,group):
super(shufflenet, self).__init__()
self.num_class=num_class
self.inchannel=24
if group==8:
stage_dict={'bolck_num':[4,8,4],
'outchannel':[384,768,1536],
'group':group}
elif group==4:
stage_dict = {'bolck_num': [4, 8, 4],
'outchannel': [272, 544, 1088],
'group': group}
elif group==3:
stage_dict = {'bolck_num': [4, 8, 4],
'outchannel': [240, 480, 960],
'group': group}
elif group==2:
stage_dict = {'bolck_num': [4, 8, 4],
'outchannel': [200, 400, 800],
'group': group}
elif group==1:
stage_dict = {'bolck_num': [4, 8, 4],
'outchannel': [144, 288, 576],
'group': group}
block_num=stage_dict['bolck_num']
outchannel=stage_dict['outchannel']
group=stage_dict['group']
self.initial=nn.Sequential(nn.Conv2d(kernel_size=3,padding=1,in_channels=3,out_channels=24,stride=2),
nn.BatchNorm2d(24),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3,stride=2,padding=1))
self.layer1 = self.make_layer(block_num[0],outchannel[0],group)
self.layer2 = self.make_layer(block_num[1], outchannel[1], group)
self.layer3 = self.make_layer(block_num[2], outchannel[2], group)
self.pool=nn.AdaptiveAvgPool2d(1)
self.fc=nn.Linear(outchannel[2],num_class)
def make_layer(self,block_num,outchannel,group):
layer_list=[]
for i in range(block_num):
if i==0:
stride=2
catchannel=self.inchannel
else:
stride=1
catchannel=0
layer_list.append(bottleblock(self.inchannel,outchannel-catchannel,stride,group))
self.inchannel=outchannel
return nn.Sequential(*layer_list)
def forward(self,x):
x=self.initial(x)
x=self.layer1(x)
x=self.layer2(x)
x=self.layer3(x)
x=self.pool(x)
x=x.view(x.size(0),-1)
x=self.fc(x)
return F.softmax(x,dim=1)
总结
本文介绍了shuffleNetV1的核心思想及其代码实现,以供大家交流讨论!
往期回顾:
(1)CBAM论文解读+CBAM-ResNeXt的Pytorch实现
(2)SENet论文解读及代码实例
下期预告:
shuffleNet-V2论文阅读及代码实现