记录一下个人遇到的问题。代码在本地运行不爆显存,到了服务器反而爆显存。
刚开始和往常一样调小batch_size值,但是随着batch_size的减小,每次cuda报oom错误时,后面具体细节里空闲的显存越少,pytorch占用的显存越来越多。如图:

 ?
?
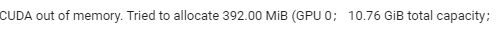 ?
?
?折磨了几天,重装了几次环境,后来偶然输出了一下model,发现input_dim获得的参数居然有一千多万,更改了获取的参数,之后即可运行。
? ? ? ? ? ? ? ?记录一下,如果遇到显存溢出找不到问题,就输出一下模型检查一下。
另外记录几条细节:
1.os.environ['CUDA_VISIBLE_DEVICES'] = '0'
将可用gpu按照0,1,2,3的顺序排序,按照序号调用,0就是第一块;0,1就是前两块。
如果只有一块gpu,则1似乎是指定用cpu运行。
2.在每一个epoch之前加入torch.cuda.empty_cache(),可在运行此epoch之前清空缓存。
3.在训练和测试阶段函数内使用with torch.no_grad(),可用阻止loss值的计算和反向传播减轻显存压力。参考格式如下:
? ? ? ? ? ? ??
同时可在训练和测试阶段的loss之后加.item(),同样可以减小显存压力。
?