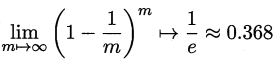?在机器学习模型训练中,往往希望训练得到得模型具有很好的泛化能力,得到一个在训练集上表现很好的模型。为了达到这个目的,应该从训练样本中尽可能学出适用于所有潜在样本的“普遍规律”。然而,学得“太好”很可能出现过拟合现象。提高泛化能力的方法有很多,其中一种可以增加样本数量。但是当带标签的样本数量有限时,该如何处理?
如果只有一个包含m个样例的数据集D={(x1,y1),(x2,y2)...(xm,ym)},既要训练又要测试,怎样才能做到呢?通过对D进行适当的处理,从中产生训练集S和测试集T。
1.留出法
? ? ? “留出法”直接将数据集D划分成两个互斥的集合,其中一个作为训练集S,一个作为测试集T。在S上训练出模型后,用T来评估其测试误差,作为对泛化误差的估计。
? ? ? 以二分类为例,假定D包含1000个样本,将其划分为S包含700个样本,T包含300个样本,用S进行训练后,如果模型在T上有90个样本分类错误,那么错误率为(90/300)=0.3,相应的有210个样本分类正确,精度为1-0.3=0.7。
? ? ? 但是,在对D进行划分时,应该尽可能地保持数据分布的一致性,避免因数据划分过程引入偏差对最终结果产生影响,例如在分类任务中至少要保持样本的类别比例相似。如果从采样的角度看数据集的划分过程,则保留类别比例的采样方式成为“分层采样”。例如:按照7:3的比例划分训练集S和测试集T,若D中包含500个正例和500个反例,则分层采样得到的S应该包含350个正例和350个反例;如果S、T中样本类别比例差别很大,则误差估计将由于训练/测试数据分布的差异而产生偏差。
? ? ?然而,在遵循了样本类别的比例后,还存在多种划分方式对D进行划分。在上面的例子中,将D中的样本进行排序,可以将前350个正例样本放入训练集S中,也可以将后350个正例样本放入S中,...这些不同的划分将导致不同的训练/测试集,相应地模型评估结果也会有偏差。因此,单次使用留出法得到的结果往往不够稳定可靠,在使用留出法时往往采用若干次随机分配,重复进行实验后取平均值作为评估结果。
2.交叉验证法
? ? “交叉验证法”先将数据集D划分为k个大小相似的互斥子集D={D1∪D2∪...∪Dk}。每个子集不相交且每个子集Di都尽可能保持数据分布的一致性,即从D中分层采样得到。然后每次用 k-1个子集的并集作为训练集,余下的子集作为测试集;这样可以得到k组训练/测试集,从而进行k次训练和测试,最终返回这k个测试结果的均值。显然,交叉验证法评估结果的稳定性和保真性在很大程度上取决于k,又叫“k折交叉验证”。在下图2.1中,取k=10,给出10折交叉验证的示意图:

图 2.1 ??
? ? ? 与留出法相似,将数据集D划分为k个不同的子集同样存在多种划分方式。为了减少因样本划分不同而引入的误差,k折交叉验证通常要随机使用不同的划分重复p次,最终的评估结果是这p次k折交叉验证结果的均值。
? ? ?k交叉验证存在一种特例:若D中包含m个样本,令k=m,则得到“留一法”。显然,留一法不受随机样本划分方式的影响,因为m个样本中只有唯一的方法划分为m个子集――每个子集包含一个样本。留一法使用的训练集与初始数据集相比只少了一个样本,这就使得在绝大多数情况下,留一法中实际训练的模型与期望得到的用D训练出来的模型很相似。因此结果往往比较准确。然而,当数据量较大时,训练m个模型的计算开销可能难以承受。另外,”没有免费的午餐“定理表明,留一法的估计结果也未必更好。
3.自助法
? ? ? ? 在留出法和交叉验证法中,由于保留了一部分样本用于测试,因此实际评估的模型所使用的训练集比D小,这必然引入一些因训练样本规模不同而导致的误差。留一法虽然受训练样本规模变化的影响小,但是计算成本过大,这时”自助法“是一个比较好的解决方案。
? ? ? “自助法”直接以自助采样法为基础。给定包含m个样本的数据集D,对他进行采样产生的数据集D':每次随机从D中挑选一个样本,将其复制到D'中,然后再将样本放回D中,使得该样本在下次采样的时候仍有可能被采集到。该过程重复执行m次后,得到包含m个样本的数据集D'。显然,有一部分样本会重复出现,而有一部分样本不会出现。在m次采样中始终不被采集到的概率为(1+1/m)^m,取极限为:
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?
? ?即通过自助采样,D中有大约36.8%的样本未出现在D'中。将D'作为训练集,D/D'作为测试集。这样,实际训练的模型与期望训练得到的模型都使用m个训练样本?,而有约1/3的、没在训练集中出现的样本用于测试,这样的测试结果称为"外包估计"。
? 自助法在数据集较小、难以有效划分训练/测试集时很有用。此外,自助法能从D中产生多个不同的训练集S,这对集成学习等方法有很大的好处。然而,自助法产生的数据集改变了初始数据集的分布,这会引入估计误差。因此,在初始数据量足够时,留出法和交叉验证法更常用。