多模态情感分析――文本分类入门理论
环境:Python3.8
此项目为2021年软件杯赛题,挂个赛题链接(http://www.cnsoftbei.com/plus/view.php?aid=599)可以查看具体题目要求。
因为当时是个菜鸡,bert参数传不进去怎么也跑不动,所以最后用的贝叶斯进行的文本分类,效果也还算不错,能跑到90以上,但是因为最后忘记一个其他分类,无缘决赛。(主要原因还是菜)
但是正是当时的思路比较简单,也非常适合自然语言处理中文本分类的入门。
自然语言处理基本流程
第一步:语料库的获取
常用方法为爬虫和白嫖开放数据集和语料库,购买是不推荐的,因为可以白嫖。这里因为软件杯公布了一部分数据(大约8000条),我们自己又从新浪爬了一部分,凑了大约10万+的新闻文本语料库
第二步:语料预处理
1.语料库的清洗
爬取数据后,首先我们要对语料库进行必要的清洗,因为很多时候我们通过爬虫爬取到的语料库有很多脏数据,比如空文本(读取异常),异常值(把网页广告爬进来了),重复值(不同网站重复爬取了一条新闻)等等。
数据清洗要做的就是把这部分脏数据去掉。常用方法为:Python的第三方库,pandas,里面有封装好的数据清洗方法,非常好用。
当然上面的数据是已经清洗过的了,如果不放心,或者有洁癖的话可以自己再清洗一遍。
2.语料分词
对于大段的句子文本,我们会先把他分词然后再进一步的处理。原因就是为了方便后续词向量的构建,以及进一步的向量空间的搭建。
常用方法为:python的jieba库,和hanlp库,前者非常常见耐用,后者精度高一点,但是需要java虚拟机的支持,这里为了方便理解,直接采用结巴库。
简单举个例子。有这样一段话“我有一个苹果”
那么用jieba分词后的结果会如何呢。
import jieba
string='我有一个苹果。'
result=jieba.cut(string)
for i in result:
print(i)
输出结果为:

当然因为返回的是一个列表,需要循环输出,但是这样的输出并不符合我们的阅读习惯,所以需要用到join方法将列表转为字符串,一次输出:(join方法为用join前的字段如空格‘ ’,插入到列表不同元素之间,然后输出为字符串)
import jieba
string='我有一个苹果。'
result=jieba.cut(string)
print(' '.join(result))

但是对于一篇文章来讲,它不可能仅仅只有一段话。那么对于文章中不可或缺的换行符‘\n’,‘\r’,还有为了保证文章格式存在的首段缩进空格‘ ’,他们对于我们的文本处理过程是没有溢出的,所以直接可以采用replace方法将他们去除。(replace方法为用后面的字段,替代前面的字段,这里后面的字段为空)(strip()为删除首行尾行空格或换行符的函数)
string = string.replace('\r\n', '').strip() # 删除换行
string = string.replace(' ', '').strip() # 删除空行、多余的空格
例如有这样一篇文章:

如果直接分词的话,会把换行符和空格加进去,相当于增加了冗余。如果用到我们上面的方法进行处理,结果如下

3.去停用词
在上面的分词的流程中,我们去除了换行符和空格等无用字符,但是除了它们,还有在上面分词之后的文章中还有很多没用的字符,比如一些标点符号(如逗号,句号,冒号,括号,书名号等)以及一些助词、副词、连词(如‘的’,‘是’等等),它们对于文本处理也是用处不大的。对于这些我们统称为停用词。
停用词一般指对文本特征没有任何贡献作用的字词,比如标点符号、语气、人称等一些词。所以在一般性的文本处理中,分词之后,接下来一步就是去停用词。但是对于中文来说,去停用词操作不是一成不变的,停用词词典是根据具体场景来决定的,比如在情感分析中,语气词、感叹号是应该保留的,因为他们对表示语气程度、感情色彩有一定的贡献和意义。
网络上有很可以白嫖的已经整理好的停用词表,比较知名的有百度的哈工大的,但是百度的有很多英文词汇,个人感觉哈工大的比较好用。
因为在python构建实例空间向量中已经封装好了去停用词的方法,不用自己去除,所以简单举个例子。
import jieba
string='《Apex英雄》开发商重生工作室成为首个获得奥斯卡提名的游戏工作室,该公司出品的24分钟的纪录短片《柯莱特(Colette)》,' \
'获得了奥斯卡最佳记录短片提名。' \
' 《柯莱特》取材自重生工作室VR射击游戏《荣誉勋章:超越巅峰》,本片由重生工作室和Oculus联合制作,是该游戏的众多真人短片之一。' \
'重生工作室创始人Vince Zampella为联合执行制片人。重生工作室的作曲者对此表示:“很多电影公司成立了十年都没有获得过奥斯卡提名,' \
'而大多数人从来都没有获得过。恭喜重生工作室成为第一家获得奥斯卡提名的游戏工作室!”'
string = string.replace('\r\n', '').strip() # 删除换行
string = string.replace(' ', '').strip() # 删除空行、多余的空格
string_seged=jieba.cut(string)
stopwords =[line.strip() for line in open('../hit_stopwords.txt', 'r', encoding='utf-8').readlines()] # 这里加载停用词的路径
outstr = ''
for word in string_seged:#遍历分词结果
if word not in stopwords:#如果该词不在停用词表中则输出
if word != '\t':
outstr += word
outstr += " "
print(outstr)
因为print()输出结果太长,我处理了一下,结果如下:
"Apex 英雄 开发商 重生 工作室 成为 首个 获得 奥斯卡 提名 游戏 工作室 公司出品 24 分钟 纪录 短片 柯 莱特 Colette 获得 奥斯卡 " \
"最佳 记录 短片 提名 柯 莱特 取材自 重生 工作室 VR 射击 游戏 荣誉 勋章 超越 巅峰 本片 重生 工作室 Oculus 联合 制作 该游戏 众多 " \
"真人 短片 重生 工作室 创始人 VinceZampella 联合 执行 制片人 重生 工作室 作曲者 对此 表示 很多 电影 公司 成立 十年 都 没有 获得 " \
"奥斯卡 提名 大多数 人 从来 都 没有 获得 恭喜 重生 工作室 成为 第一家 获得 奥斯卡 提名 游戏 工作室"
第三步:特征工程
特征工程这个词不好理解,但是他的目的很好理解。
即做完语料预处理之后,接下来需要考虑如何把分词之后的字和词语表示成计算机能够计算的类型,也就是说将文本的特征转换成计算机能够处理的特征。
显然,如果要计算我们至少需要把中文分词的字符串转换成数字,确切的说应该是数学中的向量。因为单纯的数字只有大小一个维度,而向量具有方向性,维度更高能够更好的表示复杂的文本。
特征工程有两种常用的表示模型分别是词袋模型和词向量。
1.词袋模型(Bag of Word, BOW),即不考虑词语原本在句子中的顺序,直接将每一个词语或者符号统一放置在一个集合(如 list),然后按照计数的方式对出现的次数进行统计。统计词频这只是最基本的方式,TF-IDF 是词袋模型的一个经典用法,我们用的就是TF-IDF 文本加权词袋法。
注:这个是我们最容易想到的方法,也是比较容易理解的。例如在不同分类的新闻中,他们文本中的词和词出现的频率都是不一样的。只要我们收集足够多的样本,就能统计不同分类的新闻文本中的特征词及其词频。
然后分类任务就是将代分类的新闻文本分词和训练样本比对,找到最贴近的类别即可完成分类.
例如在游戏新闻中出现频率非常高的词‘’王者荣耀’,那么如果我们待分类的新闻文本中高频词汇中包含了王者荣耀,那么我们可以判定其有一定概率为游戏新闻。当然我们为了提高准确率防止误分类,我们要把所有的词汇都考虑进去,找到概率最大的新闻分类。
2.词向量法:词向量将字、词语转换成向量矩阵的计算模型。目前为止最常用的词表示方法是 One-hot,这种方法把每个词表示为一个很长的向量。这个向量的维度是词表大小,其中绝大多数元素为 0,只有一个维度的值为 1,这个维度就代表了当前的词。还有 Google 团队的 Word2Vec,其主要包含两个模型:跳字模型(Skip-Gram)和连续词袋模型(Continuous Bag of Words,简称 CBOW),以及两种高效训练的方法:负采样(Negative Sampling)和层序 Softmax(Hierarchical Softmax)。**值得一提的是,Word2Vec 词向量可以较好地表达不同词之间的相似和类比关系。**除此之外,还有一些词向量的表示方式,如 Doc2Vec、WordRank 和 FastText 等。
注:看起来介绍很繁琐,专业词汇比较多,理解比较困难,但是你只要记住一句话就行了,词向量比词袋要好,他能从多维度理解文本,而不是像词袋模型仅仅是统计词汇频率。
在这里为了更好的理解One-hot,简单举个例子。
假设,语料库中所有词汇只有
【小明,小红,有,没有,苹果,橘子】
那么‘小明有苹果这句话’对应的向量为
【1,0,1,0,1,0】
但是上面介绍的方法都不如bert,bert加入了上下文机制和注意力机制能够更好的理解不同文本的语义。总的来说一句话,bert永远的神!
第四步:特征选择
接上特征工程,我们将所有词的词频或者词向量构建完成,如何从中选择最具有代表性的词汇呢。
以词袋模型来举例,仅仅是简简单单的排个序选择其中出现最高频次的词向量来代表这个类别的文章吗?
举个极端的例子,在财经类新闻中,‘经济’‘公司’‘股票’这几个词出现的频次极高,但是只要一篇新闻中出现较高频次的‘经济’‘公司’‘股票’我们就认定他就是财经类新闻吗?
当然不是,是的话我就不在这哔哔了。
我们对房产类新闻文本进行词频统计,发现房产类新闻中‘经济’,‘公司’,‘股票’占比也非常高,而且不下于财经类新闻。(可能因为房产类新闻的主编都是财经类主编兼职的吧。)当然,科技类新闻,‘公司’出现的频率也非常高。
那么对于这样的情况,TF-IDF这个算法就非常善于处理这种在此类文本中占比极高,但是在总体语料库中占比也比较高的词汇。
TF是词频(Term Frequency)
词频(TF)表示词条(关键字)在文本中出现的频率。

IDF是逆向文件频率(Inverse Document Frequency)
逆向文件频率 (IDF) :某一特定词语的IDF,可以由总文件数目除以包含该词语的文件的数目,再将得到的商取对数得到。

分母加1是为了防止分母为0的情况出现。
如果包含词条w的文档越少, IDF越大,则说明词条具有越强的代表性。
TF-IDF实际上是:TF * IDF
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
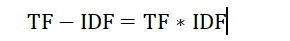
注: TF-IDF算法非常容易理解,并且很容易实现,但是其简单结构并没有考虑词语的语义信息,无法处理一词多义与一义多词的情况。
第五步:模型训练
在特征向量选择好之后,接下来要做的事情当然就是训练模型,对于不同的应用需求,我们使用不同的模型,传统的有监督和无监督等机器学习模型, 如 KNN、SVM、Naive Bayes、决策树、GBDT、K-means 等模型;深度学习模型比如 CNN、RNN、LSTM、 Seq2Seq、FastText、TextCNN 等。
我们这里选择的是贝叶斯(Naive Bayes)。
贝叶斯的原理也比较容易理解。
举个简单的例子。统计财经类和游戏类几篇文章中包含的词汇,有为1,没有为0
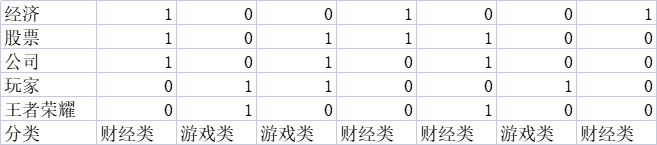
假设一篇文章中有‘经济,公司,玩家’那么这个文本为财经类的概率为多少
分类中一共7个样本,4个为财经类:
则先验概率:P(财经类)=4/7
有财经类文本中,有经济的有3个,
则条件概率:P(有“经济”|财经类)=3/4
同理
条件概率:P(无“股票”|财经类)=1/4
条件概率:P(有“公司”|财经类)=2/4
条件概率:P(有“玩家”|财经类)=0/4=0
条件概率:P(无“王者荣耀”|财经类)=3/4
然后让上述所有概率相乘,可以得出,在有经济,无股票,有公司,有玩家,无王者荣耀的条件下,文本为财经类的概率值
注意在这里有一个条件概率为0。
当某个类别下某个特征项划分没有出现时,就是产生这种现象,这会令分类器质量大大降低。为了解决这个问题,我们引入Laplace校准,它的思想非常简单,就是对每个类别下所有划分的计数加1,这样如果训练样本集数量充分大时,并不会对结果产生影响,并且解决了上述频率为0的尴尬局面。所以,
条件概率:P(有“玩家”|财经类)=(0+1)/(4+1)=1/5,当然不止这个条件概率为0的,所有条件概率都需要分号上下加1。
所以
条件概率:P(有“经济”|财经类)=4/5
条件概率:P(无“股票”|财经类)=2/5
条件概率:P(有“公司”|财经类)=3/5
条件概率:P(有“玩家”|财经类)=1/5
条件概率:P(无“王者荣耀”|财经类)=4/5
则,在有经济,无股票,有公司,有玩家,无王者荣耀的条件下,文本为财经类的概率值为
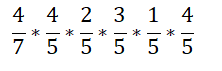
最后计算结果为0.17554
同理计算这篇有‘经济,公司,玩家’的文章为游戏类的概率为多少,
最后计算结果为0.03013
显然,这篇有‘经济,公司,玩家’的文章为财经类的概率比游戏类的要大,所以确定这篇文章属于财经类。
这个只是一个简单举例,在实际处理过程中,文章词汇会更多,而且也会将我们TF-IDF作为权重加入处理过程。