����Ŀ¼
ժҪ
�����Ķ�
һ. A deep learning algorithm for multi-source data fusion to predict water quality of urban sewer networks
(��Դ�����ں�Ԥ�������ˮ����ˮ�ʵ����ѧϰ�㷨)
����:Yiqi Jiang, Chaolin Li,, Lu Sun, Dong Guo, Yituo Zhang, Wenhui Wang
��λ:�й����ڹ�������ҵ��ѧ��ľ�뻷������ѧԺ
�й���������ҵ��ѧ����ˮ��Դ�뻷�������ص�ʵ����

����ժҪ
������ˮ������Դ��Ⱦ��һ�����Լ��Ϳ��Ƶ����⡣Ϊ�˽����һ����,����ˮ��ˮ�����ۺ�Ԥ���б�����ٹؼ�ˮ��ָ�ꡣȻ��,����һЩ��Ҫ�Ļ�ѧָ��(������������(BOD5)����ѧ������(COD)������(NH4-N)���ܵ�(TN)������(TP))��Ҫ������ʱ��;������в���,�⽫����ˮ�����е�Ԥ���������Ӱ�졣���е�ͳ�Ʒ����ͻ���ѧϰ�㷨������Ч�ؽ�����ʱ��������ṩ���ľ��ȡ�����,��Щ������ȱ�����ǵĸ������ص���Ԥ�����ܲ��������⡣�������о����dz��ж�Դ���ݶ���ˮ������ˮ��Ԥ���Ӱ��,ͬʱ��չͳ�Ʒ��������ѧϰ�㷨��Ϊ�˽���������,���������һ�ֻ��ڶ�Դ�����ںϵ����ѧϰ�������÷����ۺϿ�������ָ�����ˮˮ�ʽ��з�����Ԥ��:����ָ��(�������ֱ��);���ָ��(���˿�);ˮ��ָ��(������ˮ��Ӧ����ˮ������ˮ���ٶȺ�Һλ);�Լ����ڼ�ص�ˮ�ʱ�ָ��(��pHֵ���¶Ⱥ͵絼��)��Ϊ����֤���ַ�������Ч��,�������й��Ϸ���һ�����н�����һ�������о���ͨ�������Է���(��Ԫ���Իع�,MLR)�ʹ�ͳѧϰ�㷨(����֪,MLP)�ıȽ�,���ְ����ݹ�������(RNN)������ʱ����(LSTM)��ѡͨ�ݹ鵥Ԫ(GRU)�����ѧϰ�㷨�������õ�Ԥ������,����GRU��ˮ�ʻ�ѧָ���Ԥ��������ǿ,ѧϰ���߽Ͽ졣�������,GRU �� R2 �� RNN �� LSTM �� 0.82%�C5.07%,R2 �ȴ�ͳ����ѧϰ�㷨�� 9.13%�C15.03%,R2 �����Է����� 37.26%�C43.38%��
��������
- ��ˮ����ˮ�ʵ�������Ԥ�������ٹؼ�ˮ��ָ��,��pHֵ���絼�ʡ��¶ȡ�����������(BOD5)����ѧ������(COD)������ӵ�(NH4-N)���ܵ�(TN)������(TP)�ȡ�����һЩָ��,��pHֵ�͵絼��,����ͨ��������豸ʵʱ��⡣Ȼ��,�ռ��Ͳ�����ˮ�����һЩ�ؼ�ˮ��ָ��,��BOD5��COD��NH4-N��TN��TP,��Ҫ������ʱ��;����������Ͳ�����ص�ʱ�����������ˮ������ˮ��Ԥ������Dz����ġ�
- ���ѧϰ��ˮ��ѧ�����кܶ�Ӧ��,���ڳ�����ˮ����ˮ��Ԥ���е�Ӧ�÷dz����ޡ�����,���ǵ��������Ӱ�������ˮ����ˮ�ʵ�����,���˿ڡ���ˮ�����������������������ϰ�ߡ��ܾ���С�ͳ�������ˮ��Ӧ,Ԥ�⸴�ӳ�����ˮ������ˮ����һ��dz�������ս�Ե�����
- �����һ�ֻ��ڶ�Դ�����ںϵ����ѧϰ�㷨�Գ�����ˮ����ˮ�ʽ���Ԥ�⡣
���о���Ŀ��:
1.���ж�Դ�����������ˮ����ˮ��ָ������֮���������Ҫ��ӳ���ϵ��
2.�����Է����ʹ�ͳ�Ļ���ѧϰ�㷨���,�������ѧϰ�ķ���Ϊ������ˮ�����ṩ�˸�ȷ��ˮ��Ԥ������
ģ�����
�ܳ������о����:

����,�ռ���Դ���ݡ�Ȼ���������Ԥ����,��Ҫ���ڽ�ԭʼ����ת��Ϊ�ɼ����ʽ�����ݴ�����,���ݼ���4:1�ı�����Ϊѵ�����Ͳ��Լ���������������,���Է���(��Ԫ���Իع�,MLR)����ͳ����ѧϰģ��(����֪��,MLP)���������ѧϰģ��,�����ݹ�������(RNN)������ʱ����(LSTM)��ѡͨ�ݹ鵥Ԫ(GRU),����Ԥ����ˮ��������ˮ�ʡ�ͬʱ,��ģ�͵����ܽ��������ۡ�
ģ������
���о���������������:��Ծ��������(RMSE)�����ϵ��(R^2)��

ʵ������
1.����35���ˮ������,����6��ˮ�ʼ��վ��,��һ��������,һ������ʱ��β�����
2.���ݼ����� ����ָ��:�������(LA)����ˮ��ֱ��(D),���ָ��(�˿�)��ˮ��ָ��4��(����ˮ��Ӧ(DWS)����ˮ����������(V)��Һλ)��ˮ��ָ��9��(pH���¶�(T)���絼�ʡ���������(SS)��BOD5��COD��NH4-N��TN��TP)�����ǵ�����ռ��˼���Ļ��������ָ��,������ˮ������ˮ�ʺ�ˮ�����ݽ����˲����Ͳ���,����16��ָ�ꡣ

- ��ǰ28�쵱��ѵ�����ݼ�,��7��ֳɲ������ݼ���
�����ֲ�ͬ���͵�ģ��(MLR��MLP��RNN��LSTM��GRU)��
����:11�����ڲ����ͻ�ȡ��ָ��,��LA��D���˿ڡ�DWS��������V��Һλ��pH��T���絼�ʺ�SS,;
���:5��ָ��,��BOD5��COD��NH4-N��TN��TP��

����n ��ָ����,m��ÿ��ָ������ԡ�
����������ֻ���ѧϰģ��(MLP��RNN��LSTM��GRU)����ͬʱԤ����ָ��,��11�������������ͬʱʵ��5������������� ��Щģ�ͻ��ܵ���ͬ��������ĸ��ַ�Χ��Ӱ�졣 ���,MLPģ�͵������������Xi(��ʽ(6))��RNNģ�͵������������Xt(��ʽ(8)��(10)��(15))����Ϊ[v�� 1, v��2, ��, v��11] ��V��n��m,����������Ϊ[v��12, v��13, v��14, v��15, v��16] ��V 'n��m��
���µ�
- ���ѧϰ��ˮ��ѧ����Ӧ�÷dz��㷺,���ڳ��й�����ˮԤ�ⷽ��ȴӦ�����ޡ����Ա��о� ּ�ڷ��� ��Դ�����������ˮ����ˮ��ָ������֮���������Ҫ��ӳ���ϵ��
- ��Դ������ָ����ָ��,���ָ��,ˮ��ָ��,�����ˮ��ָ�ꡣ
- ���dz��������߲�õ�ǰ11��ָ�����ֵ,��Ϊ��������ֵ;�������ײ��Եĺ����BOD5��COD��NH4-N��TN��TPֵ,��Ϊ���ֵ����Ԥ�ⷽ���ܹ�ͨ�����ڻ�ȡ�Ͳ�����ָ��,��Ч�����ٵ�Ԥ��ˮ�ʡ������Խ������Ʒ�ɼ��ͻ�ѧ������صĴ���ʱ�䳤�ͳɱ��ߵ����⡣
- ��MLR��MLP,RNN,LSTM,GRU�ֱ�ѵ��ģ��,�ֱ���������Ա�,�ó�GRU����������õġ�
- ʵ������ӵ�н�Ϊ�㷺�����ݼ�,�������˲�ͬģ�ͶԱ�,ʹ���о�����һ���Ŀɿ��ԡ�
˼����
- ���ѧϰģ�͵�ˮ��Ԥ�����ܿ��ܲ���ȡ����ģ�ͱ��������ݼ�������,��ȡ���ڴ�����ѵ��ѧϰģ�͵����ݼ���ѡ�������ָ�ꡣ���ڱ��о���û������,��Ҫ̽��ÿ������ָ���ģ��Ԥ��Ĺ���ֵ(ע��������),���������ܻή��Ԥ��ɱ���
- �ڳ��к���ˮ����,��ˮ��Ԥ��ָ��ʱ,���ǿɲ����Խ���ỷ��,���ָ��,ˮ��ָ��,���������,����ѵ��������,������ѵ����������,���Ԥ��ľ��ȡ�
- ���о�ֻ��������ԭʼ���������ѧϰģ��,���ǿ��Խ�һ���Ľ��Ż���Щģ��,����Ч���Dz��ǻ���á�
��. ����ѧ���ѧϰʵ���C��������
2.1 �����������ݼ�
## ����
import os
import torch
from d2l import torch as d2l
1. ���غ�Ԥ�������ݼ�
������������ݼ�����Դ���Ժ�Ŀ�����Ե��ı����ж���ɵġ�
����,����һ����Tatoeba��Ŀ��˫����Ӷ���ɵġ�Ӣ-�������ݼ�,���ݼ��е�ÿһ�ж����Ʊ����ָ��ı����ж�,���ж���Ӣ���ı����кͷ����ķ����ı�������ɡ���ע��,ÿ���ı����п�����һ������,Ҳ�����ǰ���������ӵ�һ�����䡣�������Ӣ���ɷ���Ļ�������������,Ӣ���� Դ����(source language),������ Ŀ������(target language)��
#@save
## ������ȡ���ݼ�,ѧ��python
d2l.DATA_HUB['fra-eng'] = (d2l.DATA_URL + 'fra-eng.zip',
'94646ad1522d915e7b0f9296181140edcf86a4f5')
#@save
def read_data_nmt():
# ���롰Ӣ��-������ݼ���
data_dir = d2l.download_extract('fra-eng')
with open(os.path.join(data_dir, 'fra.txt'), 'r', encoding='UTF-8') as f:
return f.read()
raw_text = read_data_nmt()
print(raw_text[:75])
Downloading ..\data\fra-eng.zip from http://d2l-data.s3-accelerate.amazonaws.com/fra-eng.zip...
Go. Va !
Hi. Salut !
Run! Cours?!
Run! Courez?!
Who? Qui ?
Wow! ?a alors?!
2. �ı�Ԥ����
�������ݼ���,���Ƕ�ԭʼ���ı����ݽ��д�����Ҫ��������Ԥ�������衣
1.�ÿո���� ����Ͽո�(non-breaking space)
2.ʹ��Сд��ĸ�滻��д��ĸ
3.�ڵ��ʺͱ�����֮�����ո�
def preprocess_nmt(text):
"""Ԥ����"""
# ʹ�ÿո��滻����Ͽո�,(\xa0��������չ�ַ�������ַ�,�������Dz���Ͽհ�)
# ʹ��Сд��ĸ�滻��д��ĸ
text = text.replace('\u202f', ' ').replace('\xa0', ' ').lower()
# �ڵ��ʺͱ�����֮�����ո�
out = ''
for i,char in enumerate(text):
if i>0 and char in (',','!','.','?') and text[i-1] !=' ':
out += ' '
out +=char
# �����������ԭ����,��д������ĸо��ȽϺ�����
# def no_space(char,prev_char):
# return char in set(',.!?') and prev_char != ' '
# out = [
# ' ' + char if i > 0 and no_space(char, text[i - 1]) else char
# for i, char in enumerate(text)]
return ''.join(out)
text = preprocess_nmt(raw_text)
print(text[:80])
go . va !
hi . salut !
run ! cours !
run ! courez !
who ? qui ?
wow ! ?a alors !
3. ��Ԫ�� tokenization
������/���仮�ֳ�һ����������ɵ������������ǰ�һ��📏������̶��зֿ����ˡ�
def tokenize_nmt(text,num_examples=None):
"""�����ݼ���Ԫ��"""
source,target = [],[]
for i,line in enumerate(text.split('\n')):
if num_examples and i>num_examples:
break
parts = line.split('\t')
if len(parts)==2:
source.append(parts[0].split(' '))
target.append(parts[1].split(' '))
return source,target
source, target = tokenize_nmt(text)
source[:6], target[:6]
([['go', '.'],
['hi', '.'],
['run', '!'],
['run', '!'],
['who', '?'],
['wow', '!']],
[['va', '!'],
['salut', '!'],
['cours', '!'],
['courez', '!'],
['qui', '?'],
['?a', 'alors', '!']])
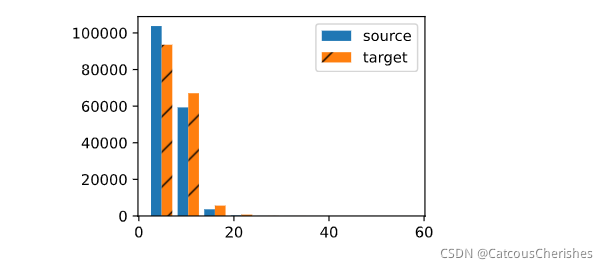
# ����ÿ���ı����а����ı��������ֱ��ͼ
# ���ӵij��ȶ�����,ͨ��С��20
d2l.set_figsize()
_, _, patches = d2l.plt.hist([[len(l) for l in source],
[len(l) for l in target]],
label=['source', 'target'])
for patch in patches[1].patches:
patch.set_hatch('/')
d2l.plt.legend(loc='upper right');
4. �ʻ��( word embedding)
���ڻ����������ݼ������Զ����,������ǿ��Էֱ�ΪԴ���Ժ�Ŀ�����Թ��������ʻ����ʹ�õ��ʼ���ǻ�ʱ,�ʻ��������Դ���ʹ���ַ�����ǻ�ʱ�Ĵʻ�����Ϊ�˻�����һ����,�������ǽ����ִ�������2�εĵ�Ƶ�ʱ����Ϊ��ͬ��δ֪(��< u n k unk unk>��)��ǡ�����֮��,���ǻ�ָ���˶�����ض����,������С����ʱ���ڽ�������䵽��ͬ���ȵ������(��< p a d pad pad>��),�Լ����еĿ�ʼ���(��< b o s bos bos>��)�ͽ������(��< e o s eos eos>��)����Щ����������Ȼ���Դ��������бȽϳ��á�
src_vocab = d2l.Vocab(source, min_freq=2,
reserved_tokens=['<pad>', '<bos>', '<eos>'])
len(src_vocab),list(src_vocab.token_to_idx.items())[:10]
(10012,
[('<unk>', 0),
('<pad>', 1),
('<bos>', 2),
('<eos>', 3),
('.', 4),
('i', 5),
('you', 6),
('to', 7),
('the', 8),
('?', 9)])
2. 2. �������ݼ�
������ģ���е�������������һ���̶��ij���,�������������һ�����ӵ�һ���ֻ��ǿ�Խ�˶�����ӵ�һ��Ƭ�ϡ�����̶���������ʱ�䲽��������������ָ���ġ��ڻ���������,ÿ������������Դ��Ŀ����ɵ��ı����ж�,���е�ÿ���ı����п��ܾ��в�ͬ�ij��ȡ�
Ϊ�������Ч��,������Ȼ����ͨ�� �ض�(truncation)�� ���(padding)��ʽʵ��һ��ֻ����һ��С�������ı����� ������ͬһ��С�����е�ÿ�����ж�Ӧ�þ�����ͬ�ij���n,��ô����ı����еı����Ŀ�����������nʱ,���ǽ���������ĩβ�����ض��ġ�< p a d pad pad>�����,ֱ���䳤�ȴﵽͳһ����;��֮,���ǽ��ض��ı�����,ֻȡ��ǰn�����,���Ҷ���ʣ��ı�ǡ�����,ÿ���ı����н�������ͬ�ij���,�Ա�����ͬ��״��С�������м��ء�
def truncate_pad(line,num_steps,padding_token):
"""�ضϻ�������ı�����"""
if len(line)>num_steps:
return line[:num_steps] # �ض϶����
return line + [padding_token]*(num_steps -len(line)) # ���ȱ�ٵ�
# ����num_stepΪ10,������Ϊ<pad>,��ÿһ�����
truncate_pad(src_vocab[source[0]], 10, src_vocab['<pad>'])
[47, 4, 1, 1, 1, 1, 1, 1, 1, 1]
�������Ƕ���һ������,���Խ��ı�����ת����С�������ݼ�����ѵ�������ǽ��ض��ġ�< e o s eos eos>��������ӵ��������е�ĩβ,���ڱ�ʾ���еĽ�������ģ��ͨ��һ����ǽ�һ����ǵ��������н���Ԥ��ʱ,�����ˡ�< e o s eos eos>�����˵������������������������,���ǻ���¼��ÿ���ı����еij���,ͳ�Ƴ���ʱ�ų��������,���Ժ�Ҫ���ܵ�һЩģ�ͻ���Ҫ���������Ϣ��
def build_array_nmt(lines,vocab,num_steps):
"""������������ı�����ת����С����"""
lines = [vocab[l] for l in lines]
lines = [l+[vocab['<eos>']] for l in lines] # ����һ���������
array = torch.tensor([
truncate_pad(l,num_steps,vocab['<pad>']) for l in lines])
valid_len = (array != vocab['<pad>']).type(torch.int32).sum(1) # �������ij���
return array,valid_len
# ע��eos��3
array,valid_len = build_array_nmt(source,src_vocab ,10)
array[1],valid_len[1]
(tensor([113, 4, 3, 1, 1, 1, 1, 1, 1, 1]), tensor(3))
ѵ��ģ��
# �������ݼ��غʹ���
def load_data_nmt(batch_size,num_steps,num_examples=600):
"""���ط������ݼ��ĵ������ʹʻ��"""
text = preprocess_nmt(read_data_nmt()) # Ԥ����
source, target = tokenize_nmt(text, num_examples) # ��Ԫ��
src_vocab = d2l.Vocab(source, min_freq=2,
reserved_tokens=['<pad>', '<bos>', '<eos>'])
tgt_vocab = d2l.Vocab(target, min_freq=2,
reserved_tokens=['<pad>', '<bos>', '<eos>']) #�����ʻ��
src_array, src_valid_len = build_array_nmt(source, src_vocab, num_steps)
tgt_array, tgt_valid_len = build_array_nmt(target, tgt_vocab, num_steps)
data_arrays = (src_array, src_valid_len, tgt_array, tgt_valid_len)
data_iter = d2l.load_array(data_arrays, batch_size)
return data_iter, src_vocab, tgt_vocab
train_iter, src_vocab, tgt_vocab = load_data_nmt(batch_size=2, num_steps=8)
for X, X_valid_len, Y, Y_valid_len in train_iter:
print('X:', X.type(torch.int32))
print('valid lengths for X:', X_valid_len)
print('Y:', Y.type(torch.int32))
print('valid lengths for Y:', Y_valid_len)
break
X: tensor([[16, 51, 4, 3, 1, 1, 1, 1],
[ 6, 0, 4, 3, 1, 1, 1, 1]], dtype=torch.int32)
valid lengths for X: tensor([4, 4])
Y: tensor([[ 35, 37, 11, 5, 3, 1, 1, 1],
[ 21, 51, 134, 4, 3, 1, 1, 1]], dtype=torch.int32)
valid lengths for Y: tensor([5, 5])
2.3 ��
- ��������ָ���ǽ��ı����д�һ�������Զ��������һ�����ԡ�
- ʹ�õ��ʼ���ǻ�ʱ�Ĵʻ���,�����Դ���ʹ���ַ�����ǻ�ʱ�Ĵʻ�����Ϊ�˻�����һ����,���ǿ��Խ���Ƶ�����Ϊ��ͬ��δ֪��ǡ�
- ͨ���ضϺ�����ı�����,���Ա�֤���е��ı����ж�������ͬ�ij���,�Ա���С�����ķ�ʽ���ء�