Python之机器学习第一弹。
Python被称为最简单好上手的语言之一,基于其极强的关联性,对各种库的引用,和资源的关联,使其实现功能非常容易。一些底层逻辑不需过多过深的理解。
机器学习是Python发展中应用广泛的一个领域。
本篇将简要介绍:
1.机器学习概念
2.sklearn库初步介绍(标准数据集及基本功能)
3.一些相关书籍及课程推荐
一、机器学习的目标
1.机器学习简介及其分类
(1)机器学习是实现人工智能的手段,其主要研究内容是如何利用数据或经验进行学习,改善具体算法的性能。
(2)特点
①多领域交叉,涉及概率论、统计学,算法复杂度理论等多门学科
②广泛应用于网络搜索、垃圾邮件过滤、推荐系统、广告投放、信用评价、欺诈检测、股票交易和医疗诊断等应用
(3)分类
①监督学习(Supervised Learning)
②无监督学习(Unsupervised Learning)
③强化学习(Reinforcement Learning,增强学习)
④半监督学习(Semi-supervised Learning )
⑤深度学习(Deep Learning)
2.Python Scikit-learn(一组简单有效的机器学习工具集)
①依赖Python的NumPy,SciPy和matplotlib库
②开源、可复用
③常用函数

3.相关书籍及课程推荐
①图书-《机器学习》-周志华(西瓜书)
出版社:清华大学出版社
主页:http://t.cn/RXvpCKB
②图书-《PRML》- Bishop
出版社:Springer
主页:http://t.cn/RXv0YVz
此书为机器学习贝叶斯学派的经典书籍,广度深度,可读性及可用性兼顾
③课程-《Machine Learning 》 - Andrew Ng
Coursera版:前百度首席科学家斯坦福教授吴恩达老师(Coursera创始人)录制的在线课程
课程主页:http://t.cn/RJZQbV2Stanford手书版
在线观看:http://t.cn/RwUWKMS
课程主页:http://cs229.stanford.edu/
此课程讲解机器学习的原理和算法知识
④课程-《CS231n》 - Fei-Fei Li(斯坦福大学)
课程主页:http://cs231n.stanford.edu/
在线观看:http://t.cn/RqRNasR
主要介绍深度学习在计算机视觉领域的应用
⑤课程-《Reinforcement Learning》- David Silver
课程主页;http://t.cn/Rw0rwtU
在线观看:http://t.cn/RIAfRUt
由AlphaGo的主要开发者团队讲解的,有关强化学习和深度强化学习原理及其应用技术
二、Sklearn库的安装
1.sklearn库
①sklearn是scikit-learn的简称,是一个基于Python的第三方模块。
②sklearn库集成了一些常用的机器学习方法,在进行机器学习任务时,并不需要实现算法,只需要简单的调用sklearn库中提供的模块就能完成大多数的机器学习任务。
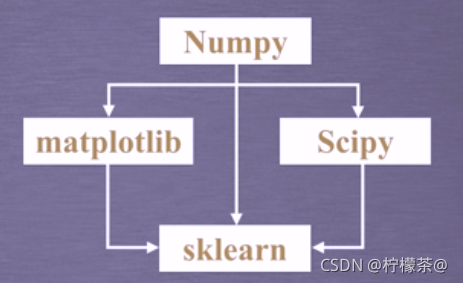
③sklearn库是在Numpy、Scipy和matplotlib的基础上开发而成的,因此在介绍sklearn的安装前,需要先安装这些依赖库。
2.sklearn库的基础库
①Numpy (Numerical Python的缩写)是一个开源的Python科学计算库。
②Scipy库是sklearn库的基础,它是基于Numpy的一个集成了多种数学算法和函数的Python模块。
③matplotlib是基于Numpy的一套Python工具包,它提供了大量的数据绘图工具。
3.安装顺序
三、sklearn库中的标准数据集及基本功能
1.数据集总览
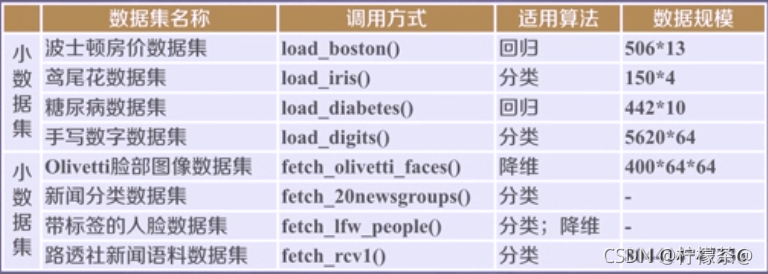
注:小数据集可以直接使用,大数据集要在调用时程序自动下载(一次即可)
这里举几个例子
2.波士顿房价数据集
①波士顿房价数据集包含506组数据,每条数据包含房屋以及房屋周围的详细信息。
②其中包括城镇犯罪率、一氧化氮浓度、住宅平均房间数、到中心区域的加权距离以及自住房平均房价等。
③因此,波士顿房价数据集能够应用到回归问题上。
④部分数据

⑤使用sklearn.datasets.load boston即可加载相关数据集
⑥重要参数:
return_X_y:表示是否返回target(即价格),默认为False,只返回data(即属性)。
3.鸢尾花数据集
①鸢尾花数据集采集的是鸢尾花的测量数据以及其所属的类别。
②测量数据包括:尊片长度、尊片宽度、花瓣长度、花瓣宽度。
③类别共分为三类:Iris Setosa,Iris Versicolour,Iris Virginica。可用于多分类问题。
④使用sklearn.datasets.load iris即可加载相关数据集
⑤参数:
return_X_y:若为True,则以(data,target)形式返回数据;默认为False,表示以字典形式返回数据全部信息(包括data和target)。
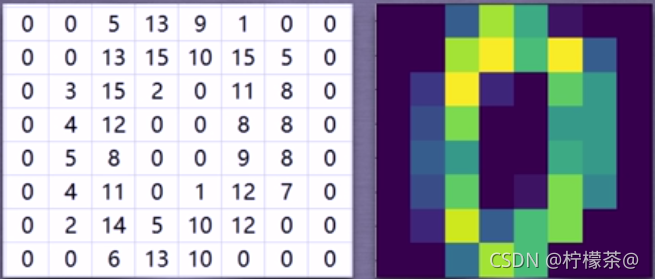
4.手写数字数据集
①手写数字数据集包括1797个0-9的手写数字数据,每个数字由8*8大小的矩阵构成,矩阵中值的范围是0-16,代表颜色的深度。
②数字0的样本
③使用sklearn.datasets.load digits即可加载相关数据集
④参数
return_X_y:若为True,则以(data, target)形式返回数据;默认为False,表示以字典形式返回数据全部信息(包括data和target)。
⑤n_ class(特别的属性):表示返回数据的类别数,如:n_class=5,则返回0到4的数据样本。
5.sklearn库的基本功能
①sklearn库的共分为6大部分,分别用于完成分类任务、回归任务、聚类任务、降维任务、模型选择以及数据的预处理。
②分类任务

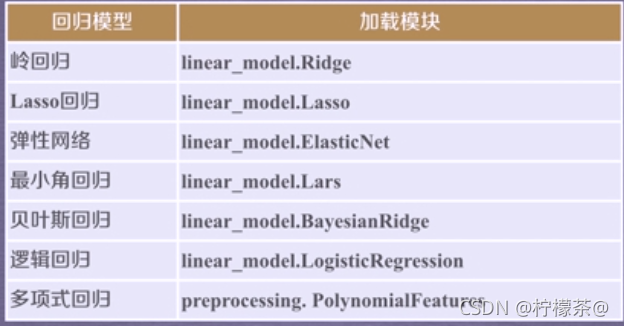
③回归任务
④聚类任务
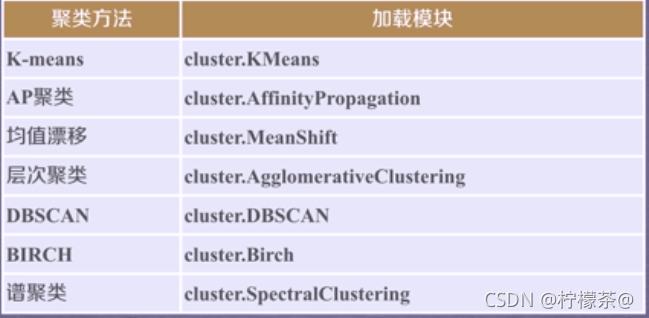
⑤降维任务
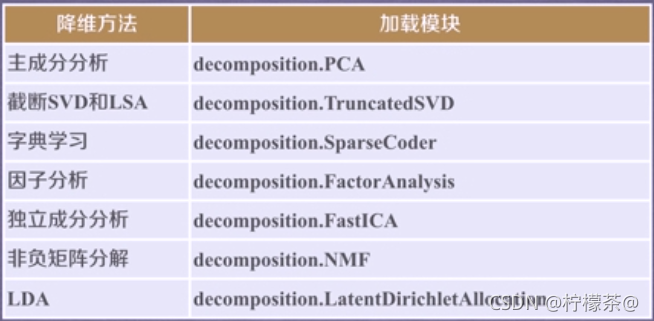
总结
本篇干货不多,这里只是简单概述,之后会以实例对这些算法的使用方式进行具体介绍。
将分为无监督学习,有监督学习,强化学习进行具体介绍
下一篇介绍:机器学习之无监督学习,将结合实例及代码详述聚类、降维、基于聚类的整图分割实例
。
如有错误,欢迎指正!