1. ����
�����ʵ��(��������)�Ĺ����з���,����ѵ������ƽ����������ʧ(Average Cross Entropy,ACE)����,��֤��ACE����ʱ,����ģ�͵�ȷ��(Accuracy,ACC)Ҳ��������ߵ������
��ջ�����Ҳ������ͬ�����Ƶ�����

2. ��������
2.1 ȷ��
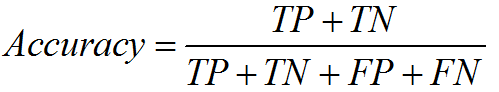
ȷ��:�ڷ���������,ȷ�ʵĶ���ֱ�,���ǿ�Ԥ�������Ƿ����ʵ�����һ�¡��ڷ���������,����һ��N������,�������һ��Nά������,����ÿһ��λ�þʹ�����һ�����,��Ӧλ�õ�ֵ�ʹ���Ԥ���Ŀ�����ڸ���ĸ���,����è���ķ���,�������Ϊ[0.3, 0.7],�ͱ�ʾ�����ͼ����è�ĸ���Ϊ0.3,���ڹ���Ϊ0.7�������Ԥ����ʱ,������ȡ����������������Ӧ�ĵı�ǩ��Ϊ����Ԥ��Ľ����ǩ,�������ϸ�������,Ԥ�����:�����ͼ�����Ϊ����
2.2 ��������ʧ
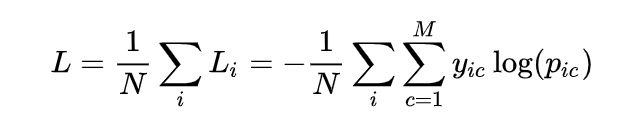

���Կ�����������ʧֻ���Ķ���ȷ����Ԥ����ʡ�(������Ϊ������,���Ǽ���һ��������ֻҪһ����ǩ,����0-1���������⡣)
3. ����֮��ı仯��ϵ
֪��:��Ұ��ɮ���Ļش�
��������һ�㿴validation
accuracy,����accuracy�����Ǹ����ɵ��ķ���,����ý�������Ϊ��ʧ�������Ż������������ǹ��ĵĻ���ȷ�ȡ�
��������(����)ģ�������ȷ��ǩ����Ȼ�ȶ�������ȷ����һ����ϵ,�������ص�ȡֵ��Χ�ܴ��п�����ʧ����ȷ��Ҳ����,�Ͼ�ȷ��ֻ�ǿ�Ԥ�������ߵ��Ǹ���ǩ��ȷ�Ⱥͽ����ػ�����������:
��������ʧ��һ��ƽ���ĺ���,��ȷ���Ƿ�ƽ����,ȷ��ֻ������������ʵ�argmax��
�� �����ȷ��ǩ�ĸ��ʽ���,�������ǩ��Ȼ�Ǹ�����ߵ�,�������ʧ���ӵ�ȷ�Ȳ���Ľ����
�� ������ݼ��ı�ǩ�ܲ�ƽ��,����90%�����A,��ôģ��һζ����Ԥ��A�ı���,���ܻ���ȷ������,��loss����Ҳ���Ը����������(cross entropy�ķ��ȿ��Ժܴ�)
�� ���ģ�ͷdz�����,�������ȷ��ǩ�ĸ��ʶ��ӽ�1,���������һ������,ȷ�ʿ���ֻ�ή�ͺ���,�������ؿ��ܻ�dz��ߡ�
������Ϊ��������ij������ӹ�ע��֤����ȷ��,����������Accuracy Ϊ��,��������ʧֻ��Ϊ���Ż�ģ�Ͳ��������õ�һ������������ʧ������
�����ѵ���г��ֽ����غ�ȷ��ͬʱ�����߽��͵�����,����������ԭ��:
- ��Ⱥֵ(outliers):�������� 10 ����ȫ��ͬ��ͼ��,���� 9 ������ A ��,һ������ B �ࡣ�����������,ģ���������ڸ�������ΪA�ࡣ����,�쳣��ͼ��(�����������DZ�ǩ��������)���ܻ��ƻ�ģ�͵��ȶ��Բ�ʹȷ�Խ��͡��������Ͻ�,һ��ģ��Ӧ��90%����Ԥ��Ϊ A ��,�������ܻ�������� epoch�����ȶ���
- ����취:Ϊ�˴�������������,�ҽ�����ʹ���ݶȲü�(���ݶȱ�����һ����Χ��,������ҵIJ���,��ӳ����ʧ�����Ͼ��ǽ�����ʧ�����ľ��ұ仯)������������������Ƿ��� - ���Լ��������ʧ�ֲ�(ѵ�����е���ʾ������ʧ)��Ѱ���쳣ֵ��
- ƫ��(bias):��������һ��,����10��һģһ����ͼƬ,������5�ŷ�����A��,5�ŷ�����B�ࡣ�����������,һ��ģ�ͽ�����������������Ϸ����Լ50%-50%�ķֲ������ڨC���ģ�������������Դﵽ50%��ȷ�ԨC��������Ч�������ѡ��һ����
- ����취:����ģ������,��Էdz����Ƶ�ѵ������,���ӿ������������ֵ�ͼ���ǩ�ı��﷽ʽ;�����Ҫ�鿴�Ƿ����������,���ijһ�������ڲ�ͬEpoch�е�loss�ֲ�,�������loss���ͬʱע�ⲻҪ���ֹ���ϵ������
If you want to check if such phenomenon occurs - check the distribution of losses of individual examples. If a distribution would be skewed toward higher values - you are probably suffering from bias.
- ���ʧ��(Class inbalance):���90%������������ͬһ���,��ѵ�������ڽ�ģ�ͼ����Ὣ���е�����Ԥ��Ϊ��һ��,�������ɷdz������ʧ����,����ʹԤ��ķֲ����Ӳ��ȶ�
- �������:1.�ݶȲü���2.��ģ��ѵ�������epoch,ģ�ͻ��ڽ�һ����ѵ����ѧϰ��ϸ�IJ��3. �������ƽ��ķ���,���Է���
sample_weights����class_weights���鿴���ֲ���
- �������:1.�ݶȲü���2.��ģ��ѵ�������epoch,ģ�ͻ��ڽ�һ����ѵ����ѧϰ��ϸ�IJ��3. �������ƽ��ķ���,���Է���
- ��ǿ������(Too strong regularization):��������˹����ϸ������Լ��,��ʹ����ѵ���Ĺ����и��ӹ�ע�ڼ�СȨ����������ȥѧϰһЩ��Ҫ��������
- �������:����һ�� categorical_crossentropy ��Ϊ�������۲����Ƿ�Ҳ�ڼ��١�������� - ��ô����ζ���������ϸ� - ���Է�����ٵ�Ȩ�سͷ���
- ����ģ�����:������Ϊ�������ɴ����ģ���������ġ��м��ֺõ��������������Ľ�����ģ��:
- Batch Normalization
- Gradient clipping ʹ����ģ��ѵ�������ȶ���Ч��
- Reduce bottleneck effect https://arxiv.org/abs/1512.00567
- Add auxiliary classifiers
4. ����
- https://stackoverflow.com/questions/48025267/relationship-between-loss-and-accuracy
- https://blog.csdn.net/xxy0118/article/details/80529676
- https://blog.csdn.net/u014421797/article/details/104689384
- https://www.zhihu.com/question/264892967