知识抽取
从不同来源、不同结构的数据中进行知识提取,形成知识(结构化数据)存入到知识图谱
1. 命名实体识别
- 检测: 北京是忙碌的城市。 [北京]: 实体
- 分类:北京是忙碌的城市。 [北京]: 地名
2.术语抽取:从语料中发现多个单词组成的相关术语。
3.关系抽取:王思聪是万达集团董事长王健林的独子。→?→??[王健林] <父子关系> [王思聪]
4.事件抽取:例如从一篇新闻报道中抽取出事件发生是触发词、时间、地点等信息

?
5.共指消解:弄清楚在一句话中的代词的指代对象

?
面向非结构化数据的知识抽取
1.实体抽取
实体抽取抽取文本中的原子信息元素,通常包含任命、组织/机构名、地理位置、时间/日期、字符值等标签,具体的标签定义可根据任务不同而调整。如:

?2.实体识别与链接
- 实体识别即识别出句子或文本中的实体
- 链接就是将该实体与知识库中的对应实体进行链接
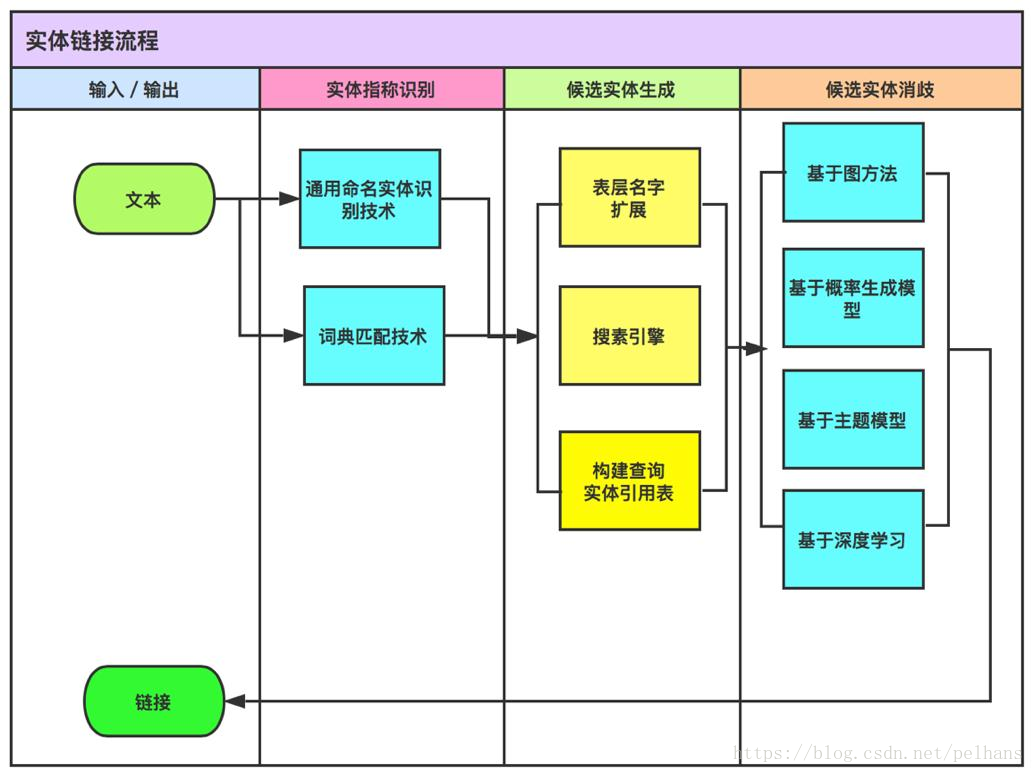
- ?输入非结构化的文本数据,经过通用命名实体识别技术或词典匹配技术进行实体指称识别
- 上一步识别出来的实体可能是实体的部分表示或另类表示,需要进行表层名字扩展、搜索引擎、构建查询实体引用表等技术来进行候选实体生成。
- 上一步实体可能生成多个候选项,所以这一步进行候选实体消歧,方法有:基于图的方法、基于概率生成模型、基于主题模型和基于深度学习的方法。
- 候选实体消歧后就可以与知识库中的实体进行链接。
例子: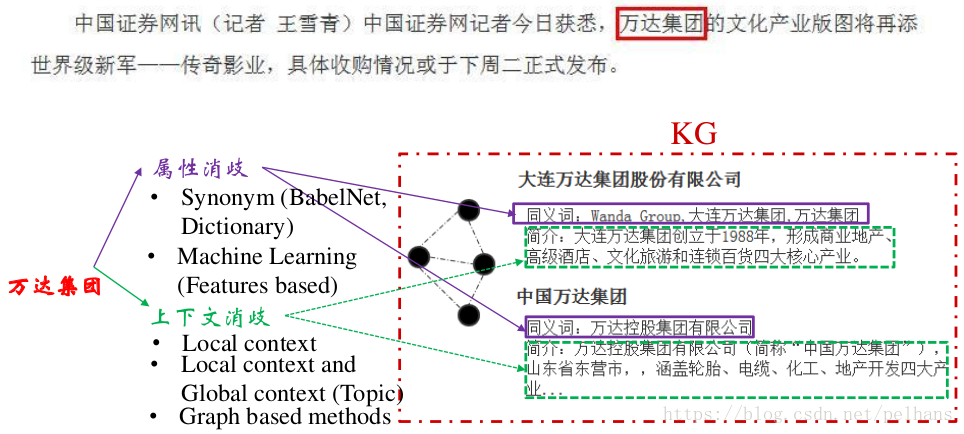 ?
?
3.关系抽取
?:从文本中抽取出两个或多个实体之间的语义关系
分类:
- 基于模板的方法(触发词的Pattern, 依存句法分析的Pattern)
- 基于监督学习的方法(机器学习方法)
- 弱监督学习的方法(远程监督、Bootstrapping)?
基于模板的方法 -?小规模数据集上容易实现且构建简单,缺点为难以维护、可移植性差、模板有可能需要专家构建。
- 基于触发词的pattern:
首先定义一套种子模板,其中的触发词为老婆、妻子、配偶等。根据这些触发词找出夫妻关系这种关系,同时通过命名实体识别给出关系的参与方。
-
基于依存分析的pattern:
以动词为起点,构建规则,对节点上的词性和边上的依存关系进行限定。一般情况下是形容词+名字或动宾短语等情况,因此相当于以动词为中心结构做的Pattern。其执行流程为:
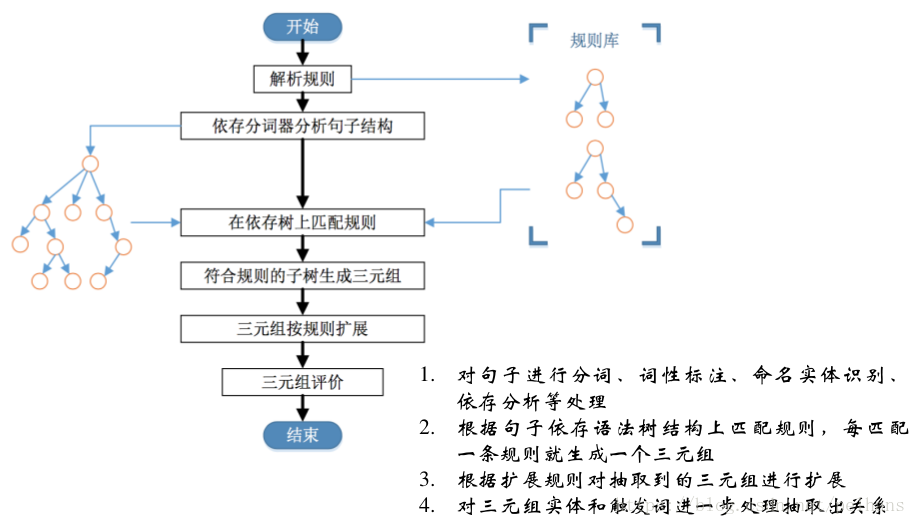
基于监督学习的方法 -??在给定实体对的情况下,根据句子上下文对实体关系进行预测,执行流程为:
- 预先定义好关系的类别。
- 人工标注一些数据。
- 设计特征表示。
- 选择一个分类方法。(SVM、NN、朴素贝叶斯)
- 评估方法。
其优点为准确率高,标注的数据越多越准确。缺点为标注数据的成本太高,不能扩展新的关系。
弱监督学习的方法 -?如果在知识库中存在某种关系,则包含该两个实体的非结构化句子均能表示出这种关系。
远程监督流程为:
- 从知识库中抽取存在关系的实体对。
- 从非结构化文本中抽取含有实体对的句子作为训练样例。
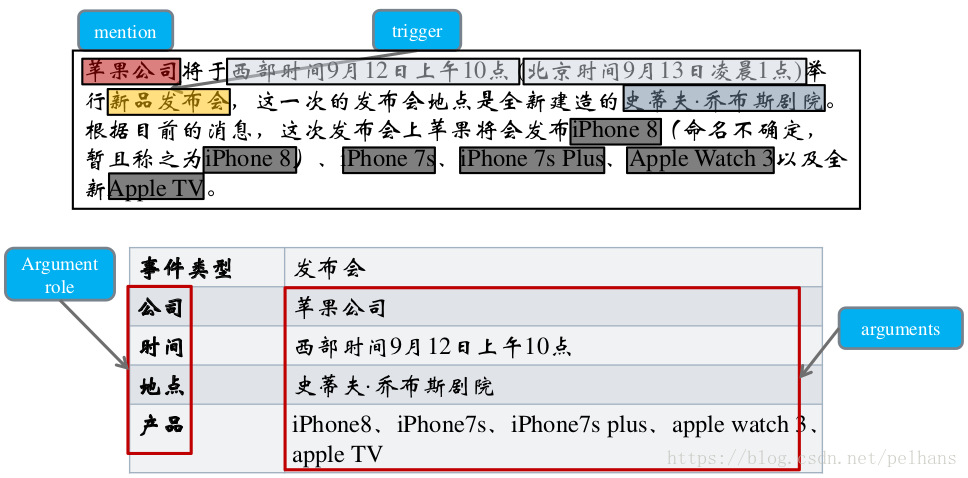
4.事件抽取
?从自然语言中抽取出用户感兴趣的事件信息,并以结构化的形式呈现出来,例如事件发生的时间、地点、发生原因、参与者等
事件抽取任务最基础的部分包括:
- 识别事件触发词及事件类型
- 抽取事件元素同时判断其角色
- 抽出描述事件的词组或句子
此外,事件抽取任务还包括:
- 事件属性标注
- 事件共指消解
面向半结构化数据的知识抽取
半结构化数据是指类似于百科、商品列表等那种本身存在一定结构但需要进一步提取整理的数据。
百科类知识抽取
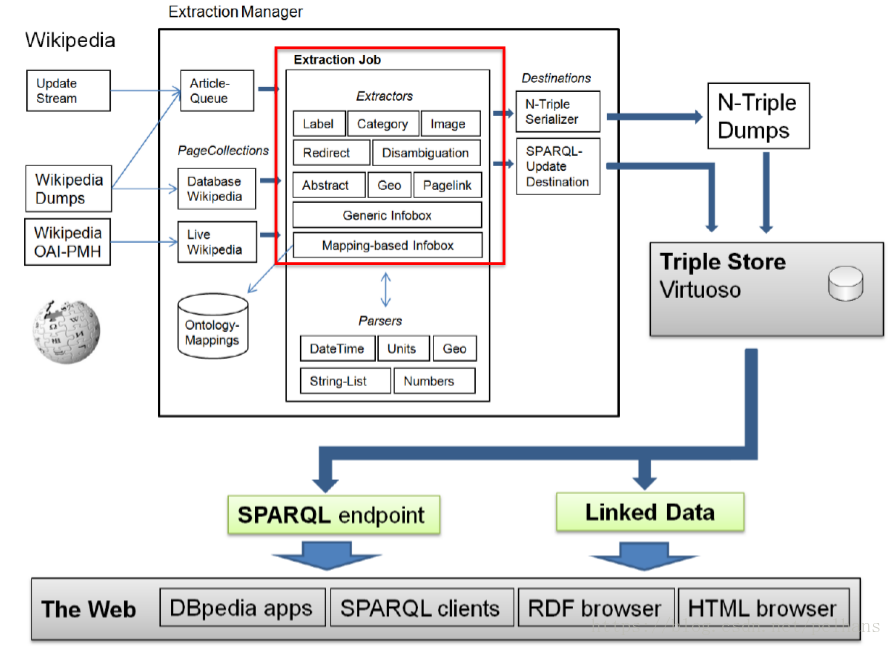
上图给出从百科里抽取知识的流程介绍。
Web网页数据抽取:包装器生成
包装器是一个能够将数据从HTML网页中抽取出来,并且将它们还原为结构化的数据的软件程序。
使用它提取信息流程为:
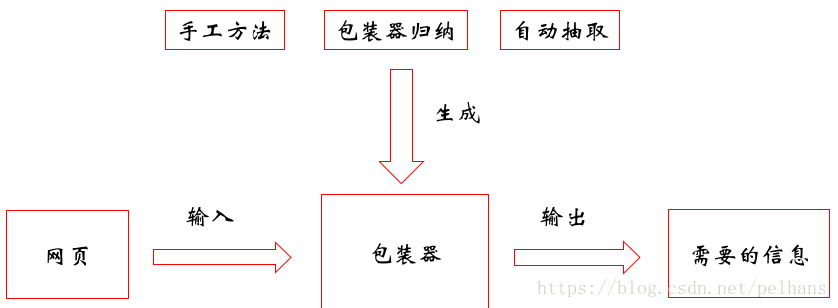
包装器归纳
通过包装器归纳这种基于有监督学习的方法,自动的从标注好的训练样例集合中学习数据抽取规则,用于从其他相同标记或相同网页模板抽取目标数据。其运行流程为:

自动抽取
网站中的数据通常是用很少的一些模板来编码的,通过挖掘多个数据记录中的重复模式来寻找这些模板是可能的。自动抽取的流程如图所示:
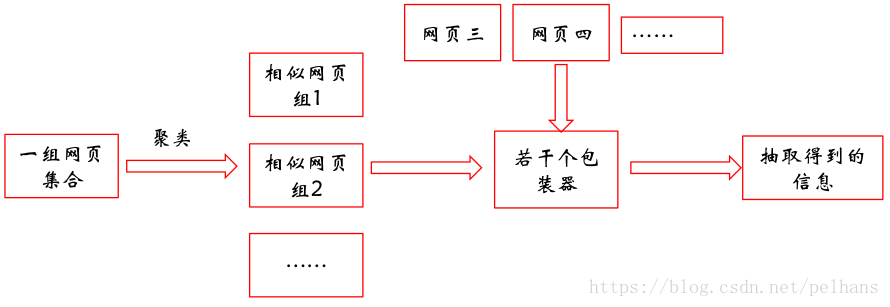
?
?面向结构化数据的知识抽取
结构化数据就是指类似于关系库中表格那种形式的数据,他们往往各项之间存在明确的关系名称和对应关系。
?
一种常用的W3C推荐的映射语言是R2RML(RDB2RDF)。一种映射结果如下图所示:

?参考: