���ʲ�����
�����ʲ�����֮�ա��Ľ���
����������һֱ�ǽ���ѧ����Ӱ�����������������CAPMģ��,ֻ������ϵͳ�Է���,��Ϊ��ƱԤ��������ֻ���г���������йء�ֱ��1972��,Jensen,Black��Scholes�Դ�ͳ����ѧ��������˲�ͬ�Ŀ���,��Ϊ��ϵͳ�Է������Ʊ�������Ǵ���һ������ع�ϵ,���״���������ʲ����ʵĸ��Merton���ӹ���ĽǶ�������������֮��Ĺ�ϵ,��ΪͶ�����ϵͳ���պͷ�ϵͳ���ն�Ҫ�����һ���ķ��ղ���,����һ����Ҳ����ҹ㷺�ؽ������Ͽɡ�
һ������,���Ƕ���Ϊ����������Ӧ���������,������Խ��,������Խ�ߡ�����2006��,Ang����ȴ�ó��˲�һ���Ľ���,���ǽ���Fama-French������ģ��ȴ�������ʲ�������Ԥ��������֮��Ĺ�ϵ��Ϊ����ع�ϵ��Ŀǰ��δ�й��ϵ����ۿ��Խ�����������,��������˾��ҵ�����,����һ����Ҳ����Ϊ�����ʲ�����֮�ա���
���ʲ����ʵĶ�������
�����ʲ����ʵĶ�������,������Fama-French������ģ�ͽ��м���
(�й�������ģ�͵Ľ����������֮ǰ��������������,�����ǿɼ���ĩ����)
����,ͨ��������ģ��,�õ�ÿ�յIJв�,����

Ȼ��,����в�IJ�����,�����²в������Ե����ܽ���������

�����͵õ�������Ҫ�����ʲ������ˡ�
Python����
Pythonʵ�ֵĹ�����,����ֻ��Ҫʹ��pandas��statsmodels.formula.api�������������:
import pandas as pd
import statsmodels.formula.api as smf
����,��ȡ����,�Ҵ���˼���ݿ���,�����˴�ҵ����2015-2019�����й�Ʊÿ�������ʡ������������Լ���ҵ��ÿ�յ�������:
Factors = pd.read_excel("F:\\���ں�\\ͼ���ز�\\���ʲ�����\\Data.xlsx", sheetname = 0, header = 0)
Return = pd.read_excel("F:\\���ں�\\ͼ���ز�\\���ʲ�����\\Data.xlsx", sheetname = 1, header = 0)
NoRisk = pd.read_excel("F:\\���ں�\\ͼ���ز�\\���ʲ�����\\Data.xlsx", sheetname = 2, header = 0)
Ϊ�˺���ɸѡ���ڷ���,������Ҫ�������ڡ�������������Ϊ������:
Factors['Date'] = pd.to_datetime(Factors['Date'])
Return['Date'] = pd.to_datetime(Return['Date'])
NoRisk['Date'] = pd.to_datetime(NoRisk['Date'])
ͨ��pd.merge()�����ݽ��кϲ�:
Data = pd.merge(pd.merge(Factors, Return, on = 'Date'), NoRisk, on = 'Date')
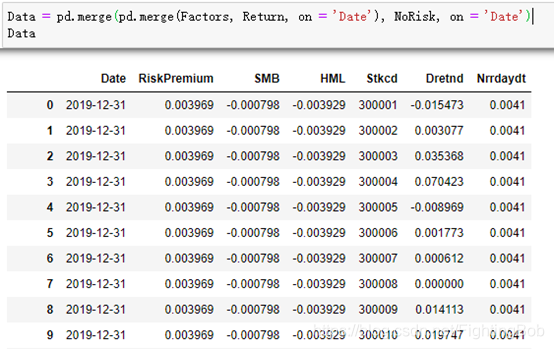
����˵��:
pd.merge(left, right, how=��inner��, on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=True,
suffixes=(��_x��, ��_y��), copy=True, indicator=False,
validate=None)
1��left: ƴ�ӵ����DataFrame����
2��right: ƴ�ӵ��Ҳ�DataFrame����
3��on: Ҫ������л������������ơ� �����������Ҳ�DataFrame�������ҵ��� ���δ������left_index��right_indexΪFalse,��DataFrame�е��еĽ��������ƶ�Ϊ���Ӽ���
4��left_on:���DataFrame�е��л����������������� ����������,����������,Ҳ�����dz��ȵ���DataFrame���ȵ����顣
5��right_on: ���DataFrame�е��л����������������� ����������,����������,Ҳ�����dz��ȵ���DataFrame���ȵ����顣
6��left_index: ���ΪTrue,��ʹ�����DataFrame�е�����(�б�ǩ)��Ϊ�����Ӽ��� ���ھ���MultiIndex(�ֲ�)��DataFrame,�������������Ҳ�DataFrame�е����Ӽ�����ƥ�䡣
7��right_index: ��left_index�������ơ�
8��how: One of ��left��, ��right��, ��outer��, ��inner��. Ĭ��inner��inner��ȡ����,outerȡ����������left:[��A��,��B��,��C��];right[��'A,��C��,��D��];innerȡ�����Ļ�,left�г��ֵ�A���right�г��ֵ���һ��A����ƥ��ƴ��,���û����B,��right��û��ƥ�䵽,��ᶪʧ��'outer��ȡ����,���ֵ�A�����һһƥ��,û��ͬʱ���ֵĻὫȱʧ�IJ�������ȱʧֵ��
9��sort: ���ֵ�˳��ͨ�����Ӽ��Խ��DataFrame�������� Ĭ��ΪTrue,����ΪFalse���ںܶ����������������ܡ�
10��suffixes: �����ص��е��ַ�����Ԫ�顣 Ĭ��Ϊ(��x��,�� y��)��
11��copy: ʼ�մӴ��ݵ�DataFrame����������(Ĭ��ΪTrue),��ʹ����Ҫ�ؽ�����Ҳ����ˡ�
12��indicator: ��һ�����ӵ���Ϊ_merge�����DataFrame,���а����й�ÿ��Դ����Ϣ�� _merge�Ƿ�������,���Ҷ�����ϲ����������ڡ���DataFrame�еĹ۲�ֵ,ȡ��ֵΪleft_only,������ϲ����������ڡ��ҡ�DataFrame�еĹ۲�ֵΪright_only,��������������ж��ҵ��۲��ĺϲ���,��Ϊleft_only��
Ȼ�����������ȡ��ݺ��·�:
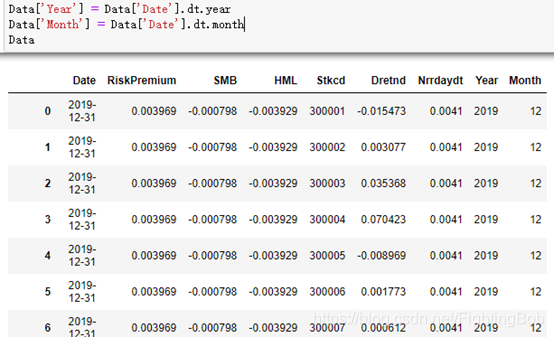
Data[��Year��] = Data[��Date��].dt.year
Data[��Month��] = Data[��Date��].dt.month
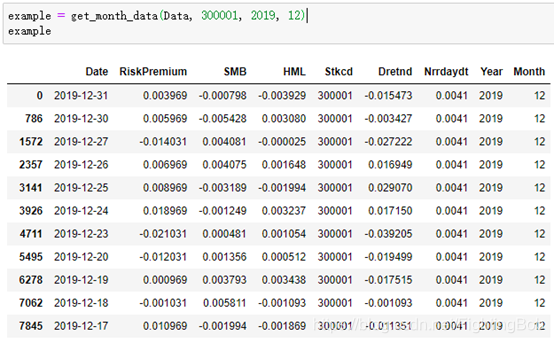
���Ǵ���һ������,������ȡijֻ��Ʊij���µ�����:
def get_month_data(data, code, year, month):
month_data = data[(data.Stkcd == code) & (data.Year == year) & (data.Month == month)]
return month_data
������,���Ǽ���һ��300001��ֻ��Ʊ��2019��12�·ݵ����ʲ����ʡ�
����,���ǻ����ֻ��Ʊ���µ�����:
example = get_month_data(Data, 300001, 2019, 12)
ͳ�Ƶ��½���������:
N = len(example)

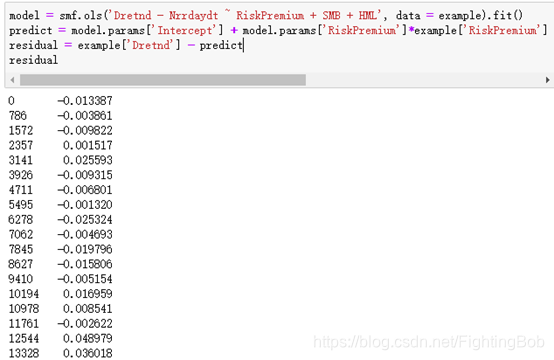
�����ع�ģ��,������в�:
model = smf.ols('Dretnd - Nrrdaydt ~ RiskPremium + SMB + HML', data = example).fit()
predict = model.params['Intercept'] + model.params['RiskPremium']*example['RiskPremium'] + model.params['SMB']*example['SMB'] + model.params['HML']*example['HML']
residual = example['Dretnd'] �C predict
����,����ó����ʲ�����:
IV = residual.std(ddof=1) * N

����˵��:
pd.std(ddof = 1)
�ú�����pandas�����ı�����㷽��,Ĭ�ϰ�����ƫ���ƽ��м���,��ddof = 1,��n-ddof��
���,���ǿ�����ѭ�������б�������,������һ��DataFrame���д���͵���:
