1. 导入必要的库函数
import os
import json
import torch
from PIL import Image
from torchvision import transforms
# 导入自己的模型
from model_v3 import mobilenet_v3_small2. 文件存储格式
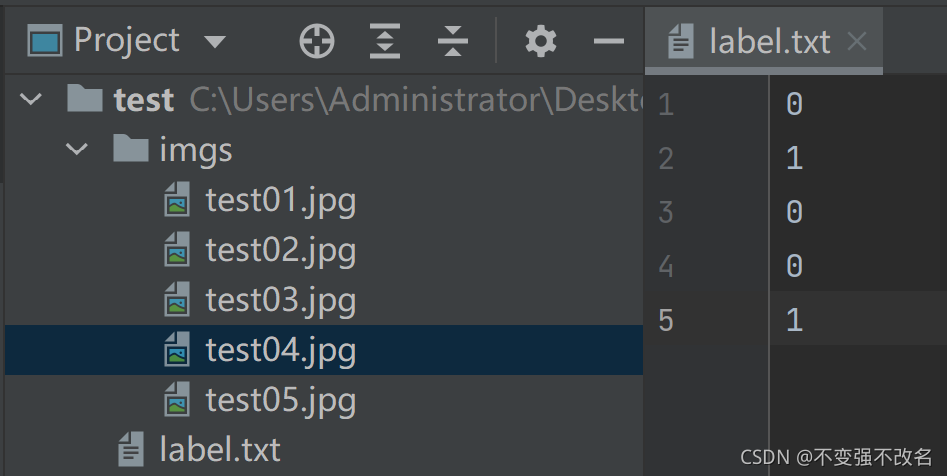
imgs文件下下是需要预测的图像
label.txt为每幅图对应的标签
### 这个无所谓,能正常读取就行
?3. 标签读取辅助函数
targets_path = "test/label.txt"
with open(targets_path, 'r') as file:
targets = file.readlines()?4.?精度、召回率、F1值、准确率计算函数
# 获取标签
target = int(targets[i])
# 输出结果
output = torch.squeeze(model(img.to(device))).cpu()
# 取出最大值的索引
predict = torch.softmax(output, dim=0)
# 得到数值
predict_cla = torch.argmax(predict).item()
# 0为正类, 1为负类
if predict_cla == 0 and target == 0:
TP += 1
if predict_cla == 1 and target == 1:
TN += 1
if predict_cla == 0 and target == 1:
FP += 1
print(str(imgs_path) + " " + str(file) + " is predicted wrong")
if predict_cla == 1 and target == 0:
FN += 1
print(str(imgs_path) + " " + str(file) + " is predicted wrong")
# 根据公式写的,如果有问题欢迎大家支持,一起学习
P = TP / (TP + FP + esp)
R = TP / (TP + FN + esp)
F1 = 2 * P * R / (P + R + esp)
acc = (TP + TN) / (TP + TN + FP + FN + esp)5. 完整实现,修改路径可以用于自己的模型
import os
import json
import torch
from PIL import Image
from torchvision import transforms
from model_v3 import mobilenet_v3_small
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
data_transform = transforms.Compose(
[transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
imgs_path = "I:/ZTC950V763_211118/CV/imgs/"
targets_path = "I:/ZTC950V763_211118/CV/y_CV.txt"
with open(targets_path, 'r') as file:
targets = file.readlines()
TP, TN, FP, FN = 0, 0, 0, 0
esp = 1e-6
i = 0
for _, __, files in os.walk(imgs_path):
for file in files:
img = Image.open(imgs_path + str(file))
target = int(targets[i])
# plt.imshow(img)
# [N, C, H, W]
img = data_transform(img)
# expand batch dimension
img = torch.unsqueeze(img, dim=0)
# read class_indict
json_path = 'class_indices.json'
assert os.path.exists(json_path), "file: '{}' dose not exist.".format(json_path)
json_file = open(json_path, "r")
class_indict = json.load(json_file)
# create model
model = mobilenet_v3_small(num_classes=2).to(device)
# load model weights
model_weight_path = "C:/Users/00769111/PycharmProjects/mobilenet_juanyang/weights/No_freeze_MobileNetV3.pth"
model.load_state_dict(torch.load(model_weight_path, map_location=device))
model.eval()
with torch.no_grad():
# predict class
output = torch.squeeze(model(img.to(device))).cpu()
predict = torch.softmax(output, dim=0)
predict_cla = torch.argmax(predict).item()
if predict_cla == 0 and target == 0:
TP += 1
if predict_cla == 1 and target == 1:
TN += 1
if predict_cla == 0 and target == 1:
FP += 1
print(str(imgs_path) + " " + str(file) + " is predicted wrong")
if predict_cla == 1 and target == 0:
FN += 1
print(str(imgs_path) + " " + str(file) + " is predicted wrong")
i += 1
if i % 200 == 0:
P = TP / (TP + FP + esp)
R = TP / (TP + FN + esp)
F1 = 2 * P * R / (P + R + esp)
acc = (TP + TN) / (TP + TN + FP + FN + esp)
print(f"精度为: {P}\n")
print(f"召回率为: {R}\n")
print(f"F1值为: {F1}\n")
print(f"准确率为: {acc}")
P = TP / (TP + FP + esp)
R = TP / (TP + FN + esp)
F1 = 2 * P * R / (P + R + esp)
acc = (TP + TN) / (TP + TN + FP + FN + esp)
print("结果汇总\n")
print(f"精度为: {P}\n")
print(f"召回率为: {R}\n")
print(f"F1值为: {F1}\n")
print(f"准确率为: {acc}")
if __name__ == '__main__':
main()