����̫�����뻹û������,ǡ��������PSO-LSTM��ȷ��û�취��ԭ,������/(��o��)/,�������ݽ���������
�ı���з���
һ����з������
??�����ǶԲ�Ʒ��������֯�����ˡ����⡢�¼������⼰�����ԵĹ۵㡢�� �С����������ۺ�̬�ȵļ����о����ı���з���(Sentiment Analysis)����Ȼ���Դ���(NLP)�����г�����Ӧ��,Ҳ��һ����Ȥ�Ļ�������,�������������ı���������ΪĿ�ĵķ��ࡣ���ǶԴ������ɫ�ʵ��������ı����з��������������ɺ������Ĺ��̡�
??���Ľ�������з����е���м���(����)��������ν��м��Է���,ָ���Ƕ��ı����а��塢���塢���Ե��жϡ��ڴ��Ӧ�ó�����,ֻ��Ϊ���ࡣ������ڡ�ϲ�����͡������������,�����ڲ�ͬ���������
??���Ľ���ϸ������ν����ı�����Ԥ����,��ʹ�����ѧϰģ���е�LSTMģ����ʵ���ı�����з�����
�����ı����ܼ����Ϸ���
??����Ŀ��ij������վ��ij����Ʒ��������Ϊ����(corpus.csv),����������ݼ�,�����ݼ�һ����4310����������,�ı�����з�Ϊ����:�����桱�͡����桱,�����ݼ���ǰ��������:
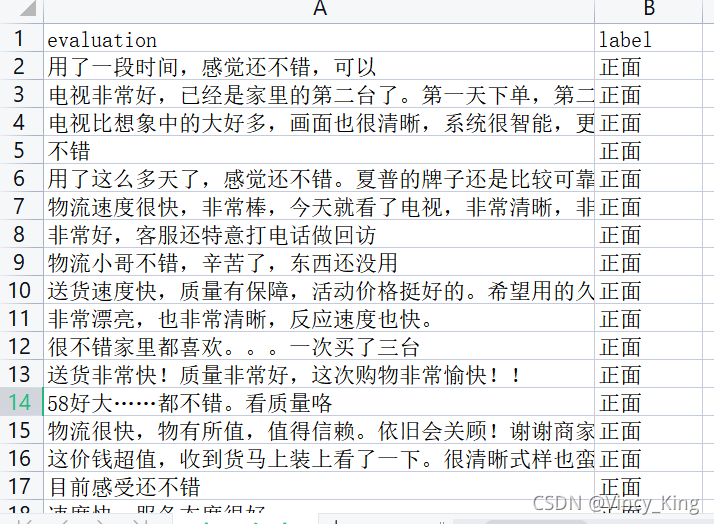
�������ݼ�����
- ���ݼ��е���зֲ�
- ���ݼ��е����۾��ӳ��ȷֲ�
���´���Ϊͳ�����ݼ��е���зֲ��Լ����۾��ӳ��ȷֲ�
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import font_manager
from itertools import accumulate
# ����matplotlib��ͼʱ������
my_font=font_manager.FontProperties(fname="C:\Windows\Fonts\simhei.ttf")
# ͳ�ƾ��ӳ��ȼ����ȳ��ֵ�Ƶ��
df=pd.read_csv('data/data_single.csv')
print(df.groupby('label')['label'].count())
df['length']=df['evaluation'].apply(lambda x:len(x))
len_df=df.groupby('length').count()
sent_length=len_df.index.tolist()
sent_freq=len_df['evaluation'].tolist()
# ���ƾ��ӳ��ȼ�����Ƶ��ͳ��ͼ
plt.bar(sent_length,sent_freq)
plt.title('���ӳ��ȼ�����Ƶ��ͳ��ͼ',fontproperties=my_font)
plt.xlabel('���ӳ���',fontproperties=my_font)
plt.ylabel('���ӳ��ȳ��ֵ�Ƶ��',fontproperties=my_font)
plt.show()
plt.close()
# ���ƾ��ӳ����ۻ��ֲ�����(CDF)
sent_pentage_list=[(count/sum(sent_freq)) for count in accumulate(sent_freq)]
# ����CDF
plt.plot(sent_length,sent_pentage_list)
# Ѱ�ҷ�λ��Ϊquantile�ľ��ӳ���
quantile=0.91
print(list(sent_pentage_list))
for length,per in zip(sent_length,sent_pentage_list):
if round(per,2)==quantile:
index=length
break
print('\n��λ��ά%s�ľ��ӳ���:%d.'%(quantile,index))
plt.show()
plt.close()
# ���ƾ��ӳ����ۻ��ֲ�����ͼ
plt.plot(sent_length,sent_pentage_list)
plt.hlines(quantile,0,index,colors='c',linestyles='dashed')
plt.vlines(index,0,quantile,colors='c',linestyles='dashed')
plt.text(0,quantile,str(quantile))
plt.text(index,0,str(index))
plt.title('���ӳ����ۼƷֲ�����ͼ',fontproperties=my_font)
plt.xlabel('���ӳ���',fontproperties=my_font)
plt.ylabel('���ӳ����ۻ�Ƶ��',fontproperties=my_font)
plt.show()
plt.close()
����������:
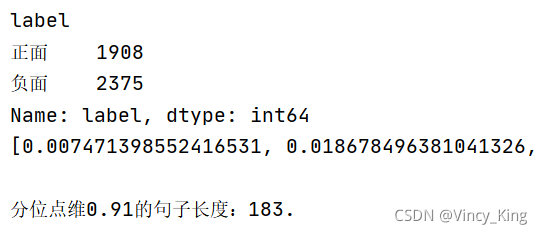
���ӳ��ȼ�����Ƶ��ͳ��ͼ����:
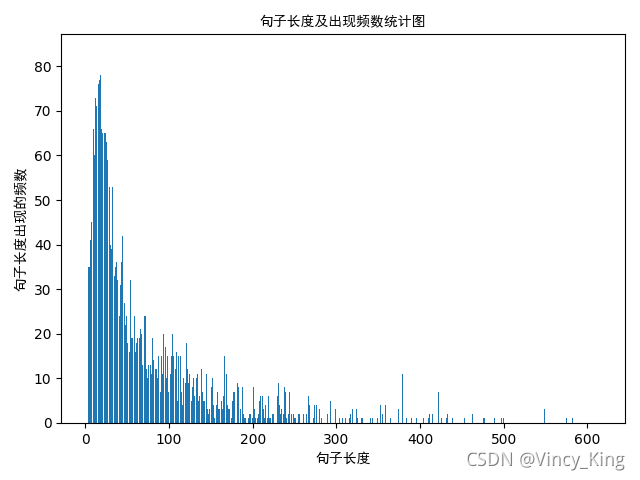
���ӳ����ۻ��ֲ�����ͼ����:

�����ϵ�ͼƬ���Կ���,����������ľ��ӳ��ȼ�����1-200֮��,���ӳ����ۼ�Ƶ��ȡ0.91��λ��,��Ϊ183���ҡ�
�ġ�LSTMģ��
ʵ�ֵ�ģ�Ϳ������:
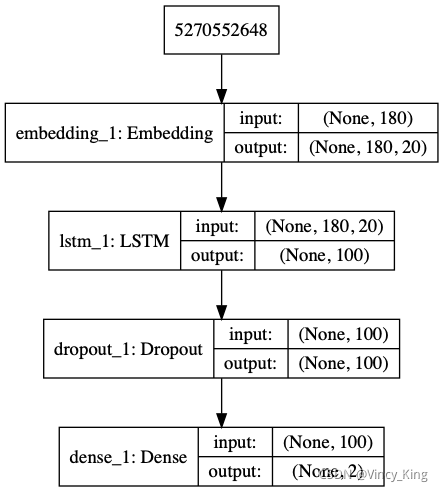
��������:
import pickle
import numpy as np
import pandas as pd
from keras.utils import np_utils
from keras.utils.vis_utils import plot_model
from keras.models import Sequential
from keras.preprocessing.sequence import pad_sequences
from keras.layers import LSTM, Dense, Embedding,Dropout
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# load dataset
# ['evaluation'] is feature, ['label'] is label
def load_data(filepath,input_shape=20):
df=pd.read_csv(filepath)
# ��ǩ���ʻ��
labels,vocabulary=list(df['label'].unique()),list(df['evaluation'].unique())
# �����ַ����������
string=''
for word in vocabulary:
string+=word
vocabulary=set(string)
# �ֵ��б�
word_dictionary={word:i+1 for i,word in enumerate(vocabulary)}
with open('word_dict.pk','wb') as f:
pickle.dump(word_dictionary,f)
inverse_word_dictionary={i+1:word for i,word in enumerate(vocabulary)}
label_dictionary={label:i for i,label in enumerate(labels)}
with open('label_dict.pk','wb') as f:
pickle.dump(label_dictionary,f)
output_dictionary={i:labels for i,labels in enumerate(labels)}
# �ʻ����С
vocab_size=len(word_dictionary.keys())
# ��ǩ�������
label_size=len(label_dictionary.keys())
# �������,��input_shape���,���Ȳ���İ�0����
x=[[word_dictionary[word] for word in sent] for sent in df['evaluation']]
x=pad_sequences(maxlen=input_shape,sequences=x,padding='post',value=0)
y=[[label_dictionary[sent]] for sent in df['label']]
'''
np_utils.to_categorical���ڽ���ǩת��Ϊ����(nb_samples, nb_classes)
�Ķ�ֵ���С�
����num_classes = 10��
�罫[1, 2, 3,����4]ת����:
[[0, 1, 0, 0, 0, 0, 0, 0]
[0, 0, 1, 0, 0, 0, 0, 0]
[0, 0, 0, 1, 0, 0, 0, 0]
����
[0, 0, 0, 0, 1, 0, 0, 0]]
'''
y=[np_utils.to_categorical(label,num_classes=label_size) for label in y]
y=np.array([list(_[0]) for _ in y])
return x,y,output_dictionary,vocab_size,label_size,inverse_word_dictionary
# �������ѧϰģ��,Embedding + LSTM + Softmax
def create_LSTM(n_units,input_shape,output_dim,filepath):
x,y,output_dictionary,vocab_size,label_size,inverse_word_dictionary=load_data(filepath)
model=Sequential()
model.add(Embedding(input_dim=vocab_size+1,output_dim=output_dim,
input_length=input_shape,mask_zero=True))
model.add(LSTM(n_units,input_shape=(x.shape[0],x.shape[1])))
model.add(Dropout(0.2))
model.add(Dense(label_size,activation='softmax'))
model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy'])
'''
error:ImportError: ('You must install pydot (`pip install pydot`) and install graphviz (see instructions at https://graphviz.gitlab.io/download/) ', 'for plot_model/model_to_dot to work.')
�汾����:from keras.utils.vis_utils import plot_model
�����������:https://www.pianshen.com/article/6746984081/
'''
plot_model(model,to_file='./model_lstm.png',show_shapes=True)
# ���ģ����Ϣ
model.summary()
return model
# ģ��ѵ��
def model_train(input_shape,filepath,model_save_path):
# �����ݼ���Ϊѵ�����Ͳ��Լ�,ռ��Ϊ9:1
# input_shape=100
x,y,output_dictionary,vocab_size,label_size,inverse_word_dictionary=load_data(filepath,input_shape)
train_x,test_x,train_y,test_y=train_test_split(x,y,test_size=0.1,random_state=42)
# ģ���������,��Ҫ�����Լ���Ҫ����
n_units=100
batch_size=32
epochs=5
output_dim=20
# ģ��ѵ��
lstm_model=create_LSTM(n_units,input_shape,output_dim,filepath)
lstm_model.fit(train_x,train_y,epochs=epochs,batch_size=batch_size,verbose=1)
# ģ�ͱ���
lstm_model.save(model_save_path)
# ��������
N= test_x.shape[0]
predict=[]
label=[]
for start,end in zip(range(0,N,1),range(1,N+1,1)):
print(f'start:{start}, end:{end}')
sentence=[inverse_word_dictionary[i] for i in test_x[start] if i!=0]
y_predict=lstm_model.predict(test_x[start:end])
print('y_predict:',y_predict)
label_predict=output_dictionary[np.argmax(y_predict[0])]
label_true=output_dictionary[np.argmax(test_y[start:end])]
print(f'label_predict:{label_predict}, label_true:{label_true}')
# ���Ԥ����
print(''.join(sentence),label_true,label_predict)
predict.append(label_predict)
label.append(label_true)
# Ԥ��ȷ��
acc=accuracy_score(predict,label)
print('ģ���ڲ��Լ��ϵ�ȷ��:%s'%acc)
if __name__=='__main__':
filepath='data/data_single.csv'
input_shape=180
model_save_path='data/corpus_model.h5'
model_train(input_shape,filepath,model_save_path)
�塢�ص㺯������
plot_model
�������������from keras.utils import plot_model�����Ļ�,���Ըij�from keras.utils.vis_utils import plot_model��
���Ҹ���֮����Ȼ����:error:ImportError: ('You must install pydot (pip install pydot) and install graphviz (see instructions at https://graphviz.gitlab.io/download/) ', ��for plot_model/model_to_dot to work.��)
�����������:
- (1)pip install pydot_ng
- (2)pip install graphviz,������鲻Ҫֱ��pip install,ȥ��������,�������������°汾

��ѹ������Ӧ��anaconda������site-package��,Ȼ����bin��Ŀ¼�� - (3)��site-packages\pydot_ng_init_.py�еĴ���,��Method3 ����:path = r"D:\App\tech\Anaconda3\envs\nlp\Lib\site-packages\Graphviz\bin" //��·��ָ��ղŸ��Ƶ�·��,��ͼ��ʾ:

np_utils.to_categorical
np_utils.to_categorical���ڽ���ǩת��Ϊ����(nb_samples, nb_classes)
�Ķ�ֵ���С�
����num_classes = 10��
�罫[1, 2, 3,����4]ת����:
[[0, 1, 0, 0, 0, 0, 0, 0]
[0, 0, 1, 0, 0, 0, 0, 0]
[0, 0, 0, 1, 0, 0, 0, 0]
����
[0, 0, 0, 0, 1, 0, 0, 0]]
model.summary()
ͨ��model.summary()���ģ����IJ���״��,��ͼ��ʾ:

�ر��л
�����²ο���ũ����ȭ���c�� �������������ο�����