�������е����Լ�����,�е��Dzο������˵Ĵ�,�Ͼ���������,��ȫʹ�õķ���ԭ�����IJ���,�����Լ�����ѧϰʹ�á�����ð������Ȩ,���˻����̽���ɾ��,��л��Щ���������Ĵ���
6.1
��֤�������ռ�����һ��
x
x
x����ƽ��
(
w
,
b
)
(w,b)
(w,b)�ľ���Ϊʽ6.2
r
=
�O
w
T
x
+
b
�O
�O
�O
w
�O
�O
(
6.2
)
r=\frac{|w^Tx+b|}{||w||} (6.2)
r=�O�Ow�O�O�OwTx+b�O?(6.2)
��:
���賬ƽ��Ϊ
w
T
+
b
=
0
w^T+b=0
wT+b=0,�䷨����Ϊ
w
w
w,��ռ���һ��Ϊ
x
1
x_1
x1?,��ƽ���ϴ���һ��
x
2
x_2
x2?,ʹ��
(
x
2
?
x
1
)
(x_2-x_1)
(x2??x1?)�볬ƽ�洹ֱ��
��һ����ʵ��������һ����ֱ�������ƽ��ķ�������
������
(
x
2
?
x
1
)
=
��
w
(
��
��
��
��
R
)
;
(
1
)
(x_2-x_1)=\eta w(����\eta \in R);(1)
(x2??x1?)=��w(��������R);(1)
��
��
x
1
��
��
ƽ
��
��
��
��
Ϊ
:
��x_1����ƽ��ľ���Ϊ:
��x1?����ƽ��������Ϊ:
r
=
�O
(
x
2
?
x
1
)
T
(
x
2
?
x
1
)
�O
1
2
=
�O
��
�O
?
�O
�O
w
�O
�O
2
;
(
2
)
r=|(x_2-x_1)^T(x_2-x_1)|^\frac{1}{2} = |\eta|*||w||_2;(2)
r=�O(x2??x1?)T(x2??x1?)�O21?=�O���O?�O�Ow�O�O2?;(2)
���ݵ�
x
2
x_2
x2?�ڳ�ƽ����,����
w
T
x
2
+
b
=
0
(
3
)
w^Tx_2+b=0(3)
wTx2?+b=0(3),��(1)����(3)��ȥ
x
2
x_2
x2?��:
w
T
x
1
+
b
=
?
��
�O
�O
w
�O
�O
2
2
w^Tx_1+b = -\eta ||w||^2_2
wTx1?+b=?���O�Ow�O�O22?,����ȡ����ֵ��,
�O
w
T
x
1
+
b
�O
=
�O
��
�O
?
�O
�O
w
�O
�O
2
2
(
4
)
|w^Tx_1+b| = |\eta|*||w||^2_2(4)
�OwTx1?+b�O=�O���O?�O�Ow�O�O22?(4)
��
�O
��
�O
=
�O
w
T
x
1
+
b
�O
�O
�O
w
�O
�O
2
2
|\eta|=\frac{|w^Tx_1+b|}{||w||^2_2}
�O���O=�O�Ow�O�O22?�OwTx1?+b�O?
�ܽ�(4)����(2)��:
r
=
�O
w
T
x
+
b
�O
�O
�O
w
�O
�O
r=\frac{|w^Tx+b|}{||w||}
r=�O�Ow�O�O�OwTx+b�O?֤��
6.2
��ʹ��LIBSVM���������ݼ�3.0
��
\alpha
���Ϸֱ�ʹ�����Ժ˺�˹��ѵ��һ��SVM,���Ƚ���֧�������IJ��
ԭ����������������¿κ�ϰ����һ��ʼ�ͽ����ر���ϸ,̫���ˡ�
��������:
from sklearn import svm
from sklearn.model_selection import cross_val_score
X=[
[1. , 2. , 1. , 0. , 2. , 1. , 0.697, 0.46 ],
[2. , 2. , 0. , 0. , 2. , 1. , 0.774, 0.376],
[2. , 2. , 1. , 0. , 2. , 1. , 0.634, 0.264],
[1. , 2. , 0. , 0. , 2. , 1. , 0.608, 0.318],
[0. , 2. , 1. , 0. , 2. , 1. , 0.556, 0.215],
[1. , 1. , 1. , 0. , 1. , 0. , 0.403, 0.237],
[2. , 1. , 1. , 1. , 1. , 0. , 0.481, 0.149],
[2. , 1. , 1. , 0. , 1. , 1. , 0.437, 0.211],
[2. , 1. , 0. , 1. , 1. , 1. , 0.666, 0.091],
[1. , 0. , 2. , 0. , 0. , 0. , 0.243, 0.267],
[0. , 0. , 2. , 2. , 0. , 1. , 0.245, 0.057],
[0. , 2. , 1. , 2. , 0. , 0. , 0.343, 0.099],
[1. , 1. , 1. , 1. , 2. , 1. , 0.639, 0.161],
[0. , 1. , 0. , 1. , 2. , 1. , 0.657, 0.198],
[2. , 1. , 1. , 0. , 1. , 0. , 0.36 , 0.37 ],
[0. , 2. , 1. , 2. , 0. , 1. , 0.593, 0.042],
[1. , 2. , 0. , 1. , 1. , 1. , 0.719, 0.103]
]
y=[1,1,1,1,1,1,1,1,0,0,0,0,0,0,0,0,0]
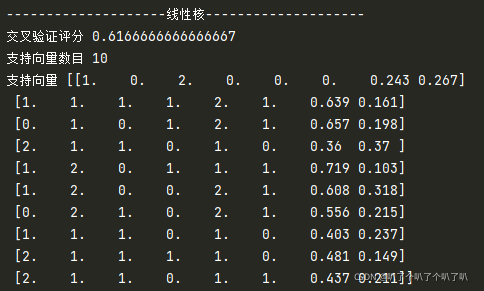
print("-"*20+"���Ժ�"+"-"*20)
clf1=svm.SVC(C=1,kernel='linear')
print("������֤����",cross_val_score(clf1,X,y,cv=5,scoring='accuracy').mean())
clf1.fit(X,y)
print("֧��������Ŀ",clf1.n_support_.sum())
print("֧������",clf1.support_vectors_)
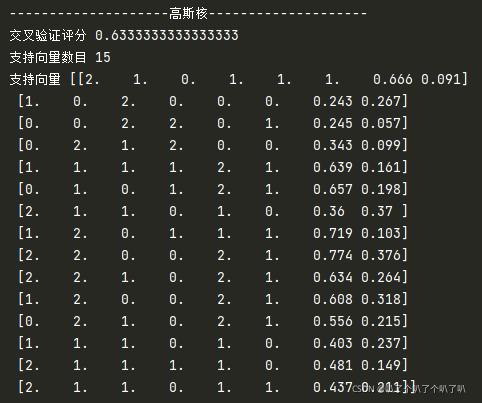
print("-"*20+"��˹��"+"-"*20)
clf2=svm.SVC(C=1,kernel='rbf')
print("������֤����",cross_val_score(clf2,X,y,cv=5,scoring='accuracy').mean())
clf2.fit(X,y)
print("֧��������Ŀ",clf2.n_support_.sum())
print("֧������",clf2.support_vectors_)
�����˼ҵ��Լ�Ҳ�ø㶮
clf1=svm.SVC(C=1,kernel='linear')//�����ҵ��������ǽ�����һ��svm����������,kernel���������������ʲô���ĺ˺���,����������Ժ�
clf1.fit(x,y)//��ѵ��������Ϸ�����ģ��
//���漸������print�������
���õ����ֲ�һ���ķ������,��C��ͬ�������,���Կ�����˹�˵�������Ҫ�������Ժ˵�,��ģ���Ӷ���,��˹�˵�֧��������ĿҲ�Ƚ϶�,����Ӧ���Ǹ�˹�˱Ƚϸ��ӡ����ﱾ����������ݿ��ӻ�,�������ԭ����ʾ������ͼֻ�Ǹ��������ó�����,һ�Լ�����ɵ����,����������ع�ͷȥ�ٰ����ݿ��ӻ�ѧϰһ�¡�
6.3
��û����������������,�ǿ��ź��ƻ���ʦ�Ŀ���ѧ���Ȿ��,����ѧ�����ٻ���������⡣