什么是聚类?
让我们直接进入它,看看这个散点图来解释。您可能会注意到,数据点似乎集中在不同的组中(图 1)。

图 1. 示例数据的散点图
为了使这一点显而易见,我们显示了相同的数据,但现在数据点是彩色的(图 2)。这些点集中在不同的组或集群中,因为它们的坐标彼此接近。在这个例子中,空间坐标表示两个数值特征,它们的空间接近度可以解释为它们在特征方面的相似程度。实际上,我们的数据集中可能有很多特征,但即使在更高维度的空间中,接近性(=相似性)的想法仍然适用。此外,在真实数据中观察集群并不罕见,代表具有相似特征的不同数据点组。

图 2. 示例数据的散点图,不同的聚类用不同的颜色表示
聚类是指在未标记数据中发现此类聚类的算法。属于同一簇的数据点表现出相似的特征,而来自不同簇的数据点彼此不同。此类集群的识别导致将数据点分割为多个不同的组。由于组是从数据本身识别的,而不是已知的目标类别,因此聚类被视为无监督学习。
正如您已经看到的,聚类可以识别数据中的(以前未知的)组。属于同一集群的相对同质的数据点可以由单个集群代表进行汇总,这使得数据缩减成为可能。聚类还可用于识别与其他聚类不同的异常观察结果,例如异常值和噪声。
不同聚类方法形成的聚类可能具有不同的特征(图3)。簇可能具有不同的形状、大小和密度。集群可以形成一个层次结构(例如,集群 C 是通过合并集群 A 和 B 形成的)。集群可能不相交、相互接触或重叠。现在让我们看看不同的聚类算法是如何产生具有不同属性的聚类的。特别地,我们概述了三种聚类方法:k-Means 聚类、层次聚类和 DBSCAN。
什么是聚类以及它是如何工作的?

图 3. 具有不同特征的集群。
聚类如何工作?
k-均值聚类
k-Means 聚类可能是最流行的聚类算法。它是一种将数据空间划分为 K 个不同簇的分区方法。它从随机选择的 K 个聚类中心开始(图 4,左),并将所有数据点分配到最近的聚类中心(图 4,右)。然后将簇中心重新计算为新形成的簇的质心。数据点被重新分配到我们刚刚重新计算的最近的聚类中心。将数据点分配给聚类中心并重新计算聚类中心的过程会重复进行,直到聚类中心停止移动(图 5)。

图 4. 随机选择的 K 个聚类中心(左)和结果聚类(右)。
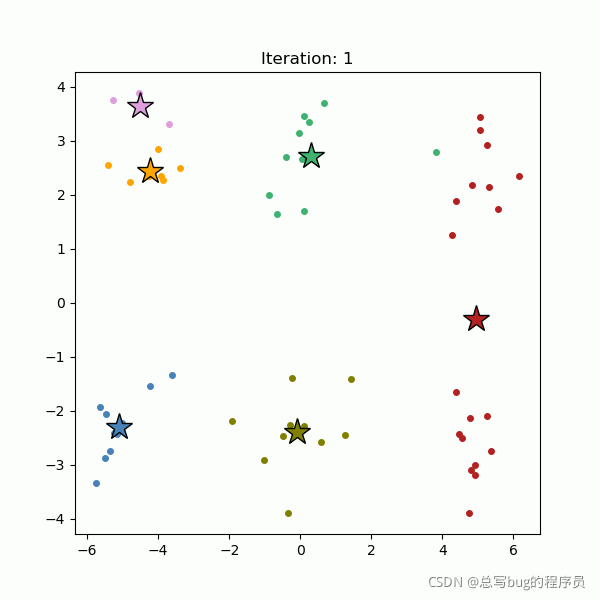
图 5. 聚类中心被迭代重新计算,直到它们停止移动 (gif)。
k-Means 聚类形成的聚类在大小上趋于相似。此外,簇是凸形的。k-Means 聚类以其对异常值的敏感性而闻名。此外,聚类结果可能会受到初始聚类中心选择的高度影响。
层次聚类
分层聚类算法通过迭代连接最近的数据点以形成聚类来工作。最初,所有数据点都相互断开;每个数据点都被视为自己的集群。然后,将最近的两个数据点连接起来,形成一个簇。接下来,两个下一个最近的数据点(或集群)连接起来形成一个更大的集群。等等。重复该过程以形成逐渐变大的集群,并一直持续到所有数据点都连接成一个集群(图 6)。
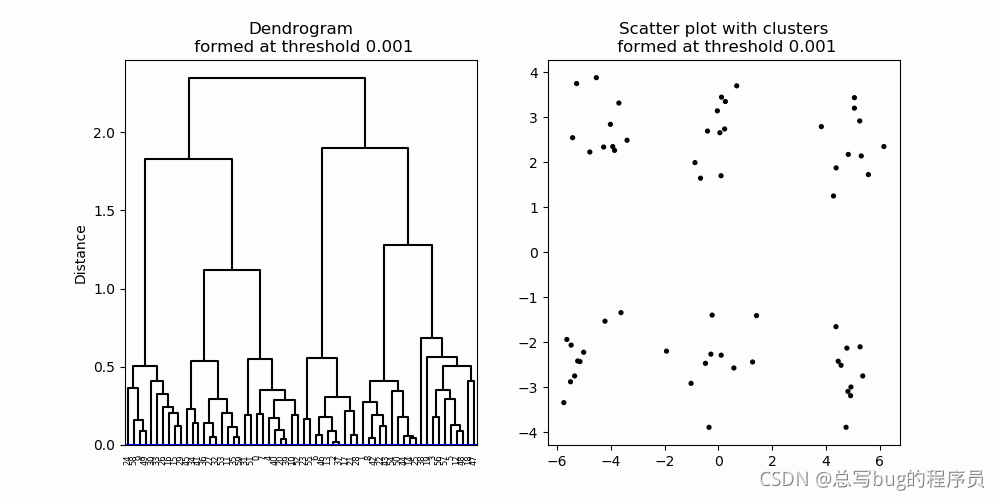
图 6. 由层次聚类产生的树状图(左)。随着距离截止值的提高,会形成
更大的簇。聚类在散点图(右)和树状图中用不同颜色表示。
层次聚类形成了聚类的层次结构,在称为树状图的图表中进行了描述(图 6,左)。树状图描述了哪些数据点/集群以多远的距离连接,从底部的单个数据点一直到顶部的单个大集群。要获得具有特定簇数的簇分区,可以简单地在树状图上的特定距离处应用截止阈值,从而产生所需的簇数(图 7)。
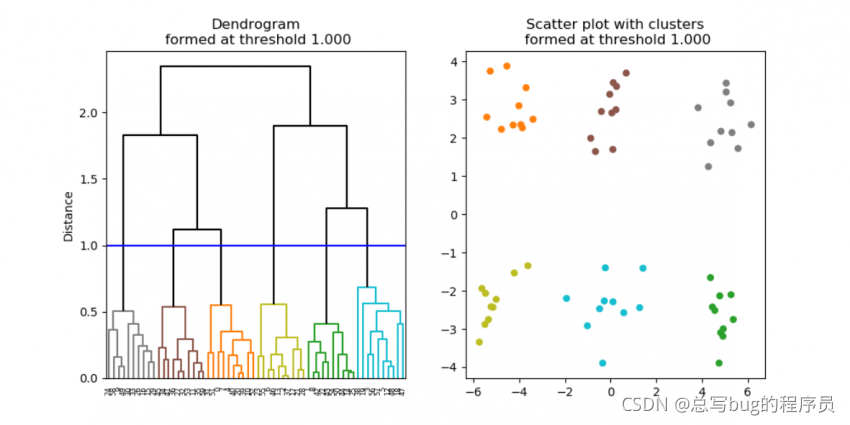
图 7. 在截止阈值为 1.0 时形成了六个簇。
由层次聚类形成的簇的形状取决于簇之间的距离是如何计算的。在单链接方法中,簇间距离是通过两个簇之间最近的两个点来测量的(图 8,左)。这种方法往往会产生分离良好的集群(图 8,中间和右边)。另一方面,在完全链接方法中,距离计算为两个集群之间的最远点(图 9,左)。由此产生的簇在大小上往往很紧凑,但不一定很好地分离(图 9,中间和右边)。在平均联动法中,簇间距离被计算为两个簇之间重心之间的距离。这种方法是单一和完整链接方法之间的折衷。
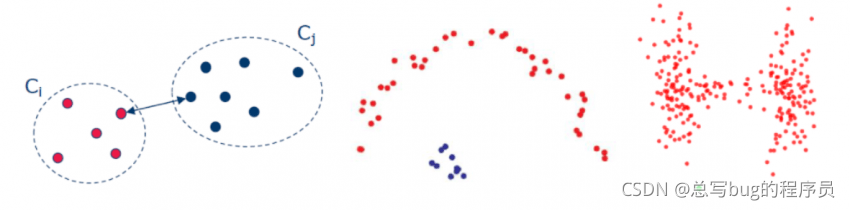
图 8 单联方式的距离计算(左)。这种方法产生分离良好的簇(中间和右边)。

图 9. 完整联动方法中的距离计算(左)。这种方法产生紧凑的簇(中间和右边)。
数据库扫描
DBSCAN 代表具有噪声的基于密度的应用程序空间聚类。它是一种基于密度的聚类方法,将密集的数据点云分组为簇。任何孤立的点都不会被视为集群的一部分,并被视为噪声。DBSCAN 算法从随机选择一个起点开始。如果该点周围的邻域内有足够多的点,则这些点将被视为与起点相同的集群的一部分。然后检查新添加点的邻域。如果这些邻域内有数据点,那么这些点也会被添加到集群中。重复这个过程,直到没有更多的点可以添加到这个特定的集群。然后随机选择另一个点作为另一个簇的起点,并且重复聚类形成过程,直到没有更多数据点可分配给聚类(图 10)。如果数据点不在任何其他数据点的邻域内,则此类数据点将被视为噪声。DBSCAN 算法可以形成任何形状的簇(图 11)。

图 10. DBSCAN 算法的簇形成过程。
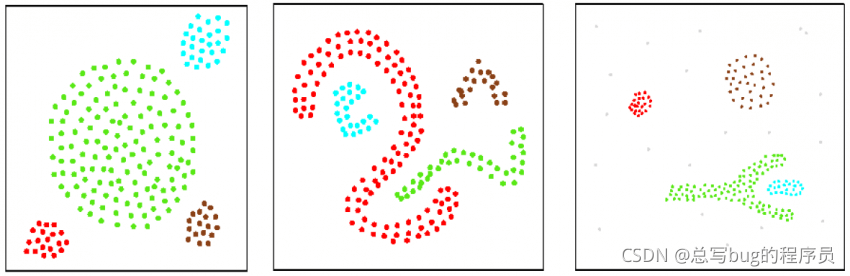
图 11. DBSCAN 形成的集群示例。
KNIME 分析平台中的集群节点
上述三种聚类算法,k-Means、层次聚类和 DBSCAN,分别作为 k-Means、层次聚类和 DBSCAN 节点在 KNIME 分析平台中可用。这些节点运行聚类算法并将聚类标签分配给数据点。以下是使用这些聚类方法对模拟聚类数据进行聚类的示例工作流(图 12)。您可以从 KNIME Hub 下载此工作流程以进行自己的尝试。
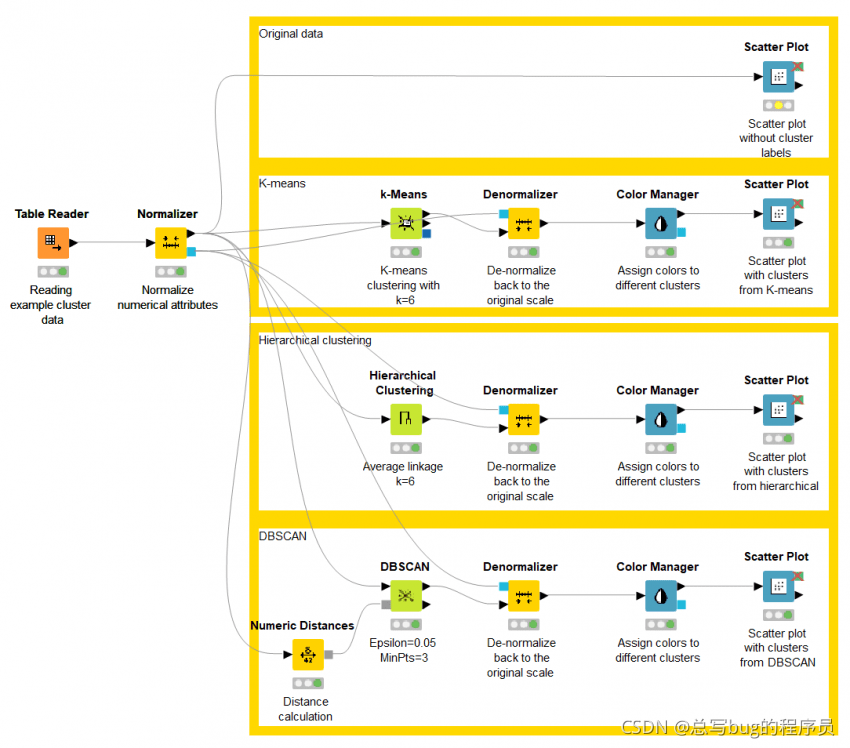
图 12. 示例工作流程 - 在模拟集群数据上进行集群 - 实现三种集群算法。
例如,使用三种聚类算法分析一开始的模拟聚类数据集(图 1)。结果集群如图 13 所示。由于集群算法处理未标记的数据,集群标签是任意分配的。应该注意的是,我们在 k-Means 和层次聚类中设置了聚类数 K=6,尽管在现实场景中这样的信息是不可用的。正如你在这个例子中看到的,这三种方法产生了非常相似的集群。
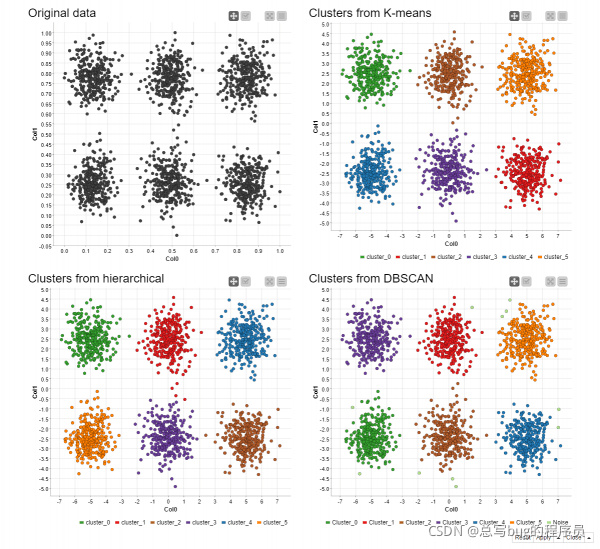
图 13. 通过 k-Means 聚类(右上)、层次聚类(左下)和 DBSCAN(右下)在模拟数据中发现的聚类。原始数据(左上角)也显示为参考。
然而,在真实数据集中,并非所有聚类算法都执行相同的操作。在下一个示例中,虹膜数据(由 3 类虹膜和 4 个数值特征组成)使用相同的算法进行分析。工作流,虹膜数据聚类,可在 KNIME Hub 上获得,网址为https://kni.me/w/zZheoPIKtcJ8rTJb. 该数据集中有两个主要的数据点,它们之间有明显的差距(图 14,左上角)。我称它们为上云和下云。由于 k-Means 聚类倾向于产生大小相似的凸聚类,因此它大致在中间分离了上层云(图 14,右上角)。至于层次聚类,我们使用平均链接方法,有利于紧凑和分离良好的聚类。由于上层云没有明显的间隙,它被分成一个紧凑的星团和一个更大的星团(图 14,左下角)。k-Means 和层次聚类的结果是由我们在两种方法中都设置 K=3 的事实驱动的。对于 DBSCAN 方法,上层云被识别为单个集群(图 14,右下角)。
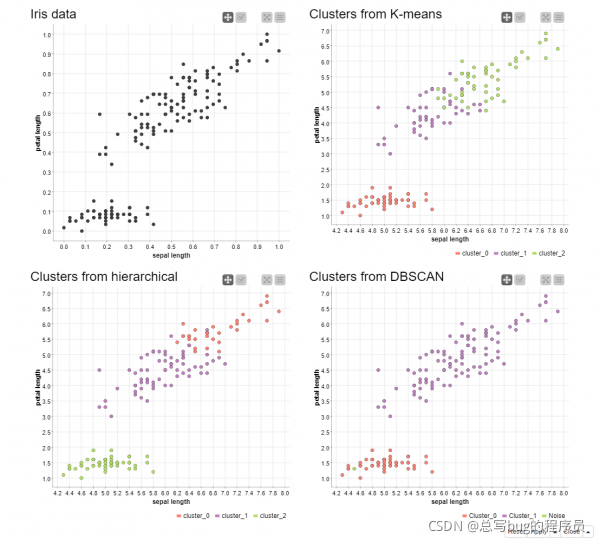
图 14. 通过 k-Means 聚类(右上)、层次聚类(左下)和 DBSCAN(右下)在虹膜数据中发现的聚类。原始数据(左上角)也显示为参考。
结论
这里介绍的方法只是聚类算法的几个例子。还有许多其他的聚类算法。正如您目前所见,不同的聚类算法会产生不同类型的聚类。与许多机器学习算法一样,没有单一的聚类算法可以在所有场景中识别任何形状、大小或密度的聚类,这些聚类可能不相交、接触或重叠。因此,选择一种算法来找到您在数据中寻找的聚类类型非常重要。