CVPR-2018- DensSiam: End-to-End Densely-Siamese Network with Self-Attention Model for Object Tracking 阅读笔记
论文地址:
https://arxiv.org/abs/1809.02714
主要创新点:
加入Self-Attention模块(第一个具有自我注意模块的孪生网络跟踪算法)。
一、 动机
为了在保持泛化能力、高精度和速度的情况下,减少参数数量,并克服同一时间下只处理一个局部领域而造成的外观模型局限和对外观变化不鲁棒的问题。
二、 主要贡献
① 提出了一种新的端到端深度孪生网络结构用于目标跟踪。新的体系结构可以捕获对外观变化鲁棒的非本地特性。此外,与目前最先进的跟踪器中常用的其他基于孪生网络的现有架构相比,在构建更深层次的网络时,它减少了层之间共享参数的数量。
② 基于Self-Attention模块的有效响应图,提高DensSiam跟踪器的性能。响应映射具有非本地特性,并捕获关于目标对象的语义信息。
③ 提出的体系结构解决了渐变消失问题,利用了特征重用,提高了泛化能力。
三、 主要内容
该算法设计的核心思想是利用过渡层分隔的密集块建立孪生网络,采用自注意模型捕捉非局部特征。
网络架构:

目标分支结构:input-ConvNet-DenseBlock-TransitionLayer-DenseBlock-TransitionLayer-DenseBlock-DenseBlock-SelfAttention
Dense block:
Dense block包括批量归一化(bn) ,校正线性单位(relu) ,池化和卷积层,所有维度如下表1所示。Dense block中的每一层将前面所有的特征映射作为输入,并将它们连接起来。这些连接确保网络将保留所有前面的特征映射所需的信息,并改善层之间的信息流,从而提高如下图2所示的泛化能力。在传统的暹罗语中,第l层的输出被作为输入输入到第(l+1)层,我们将第l层的输出表示为 xl。为了描述Dense block中各层之间的信息流,假设输入张量为 x0∈R C× N × D,因此第l层的输出特征映射为:
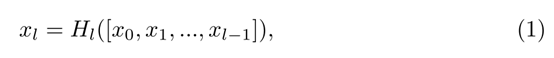
Hl是BN、ReLU和3x3卷积三个连续操作,[ x0,x1,… ,xl-1]是一个特征映射连接。


Transition layer:
Transition layer包括卷积、池化和dropout操作。通过添加dropout到Dense block和Transition layer中去降低DensSiam对负样本过拟合的风险。由于Denssiam 是完全卷积的,不使用 padding 操作,所以Dense block中特征映射的大小是不同的,不能串联起来。因此,必须使用Transition layer来匹配Dense block的大小并正确地连接它们。
Self-Attention Model:
DensSiam 将Self-Attention 模块加入到目标分支,并以目标分支的输出特征图(x∈R C× N × D)作为输入。自我注意模型通过1x1卷积将特征图分成三个映射来获取注意,f (x)、 g (x) 和h(x)计算如下:

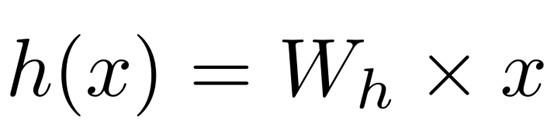
Wf,Wg,Wh是离线学习参数。

注意力特征 图权重参数通过以下计算得到:

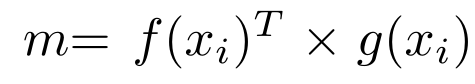
φ是注意图的权重。
自我注意特征图计算如下:

其中 h (x) = Wh × x,Wh是离线学习参数。我们使用Dense block和自注意力模块的逻辑损失通过随机梯度下降(SGD)来计算单个损失如下:
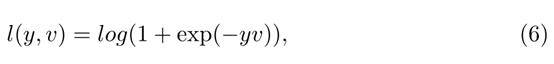
其中 v 是候选目标对的单分值,y ∈[-1, 1]是它的ground truth label。为了计算特征映射的损失函数,我们使用整个映射的损失平均值:
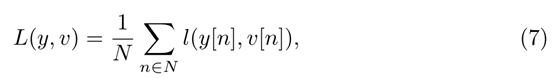
最后,搜索分支与目标分支具有相同的体系结构,只是搜索分支没有自我注意模块。将自注意图的输出和搜索分支的输出反馈到相关层,学习相似度函数。
四、 实验结果
训练数据集:ILSVRC15
评测数据集:VOT2015 VOT2016 VOT2017
网络结构:input?ConvN et?DenseBlock1?TransitionLayer?DenseBlock2?TransitionLayer?DenseBlock3?DenseBlock4?Self Attention
testing speed:60 fps
The input target image size is 127 × 127 and the search image size is 255 × 255.


