问题1:在包含 N 个文档的语料库中,随机选择一个文档。该文件总共包含 T 个词,词条「数据」出现 K 次。如果词条「数据」出现在文件总数的数量接近三分之一,则 TF(词频)和 IDF(逆文档频率)的乘积的正确值是多少?
A、KT * Log(3)
B、K * Log(3) / T
C、T * Log(3) / K
D、Log(3) / KT
答案:B
解析:TF 的公式是 K/T,IDF 的公式是 log = log(1 / (?)) = log (3) 因此正确答案是 Klog(3)/T

文末免费送电子书:七月在线干货组最新 升级的《名企AI面试100题》免费送!
问题2:参阅以下的文档词矩阵 下面哪个文档包含相同数量的词条,并且在整个语料库中其中一个文档的词数量不等同于其他任何文档的最低词数量。
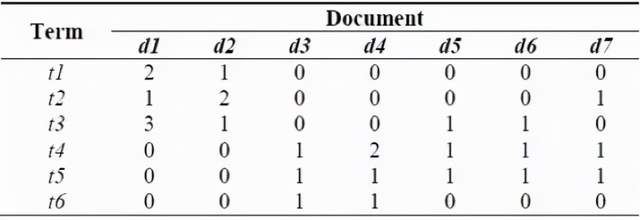
A、d1 和 d4
B、d6 和 d7
C、d2 和 d4
D、d5 和 d6
答案:C
解析:文档 d2 和 d4 包含 4 个词条并且不是词条最低数量 3。

问题3:?参阅以下的文档词矩阵 语料库中最常见和最稀少的词条分别是什么?
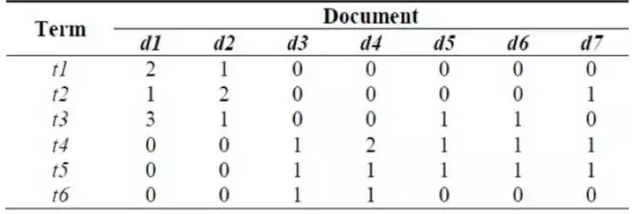
A、t4、t6
B、t3、t5
C、t5、t1
D、t5、t6
答案:A
解析:t4和t5出现的文档数最多,二者相比之下,t4出现的总次数较多,故最常见的词条是t4;t6只在 d3 和 d4 中出现,在语料库中出现的次数也最少,故最稀少的词条是t6。

问题4:参阅以下的文档词矩阵 在整个语料库中使用最大次数的词和它的词频分别是?

A、t6,2/5
B、t3,3/6
C、t4,2/6
D、t1,2/6
答案:B
解析:t3 在整个语料库中的使用的最大次数是 3,t3 的词频是 3/(2+1+3)=3/6

问题5:?下列哪种方法不是灵活文本匹配的一部分?
A、字符串语音表示(Soundex)
B、语音发声散列(Metaphone)
C、编辑距离算法(Edit Distance)
D、关键词哈希算法(Keyword Hashing)
答案:D
解析:除了关键词哈希算法,其它所有方法都用于灵活字串匹配

问题6:?Word2vec 模型是一种用于给文本目标创建矢量标记的机器学习模型。对于Word2vec,它包含多个深度神经网络,这么说对么?
A、对
B、错
答案:B
解析:Word2vec 也包含预处理模型(preprocessing mode),它不属于深度神经网络。

问题7:?关于无语境依赖关系图(context-free dependency graph),句子里有多少子决策树(sub-trees)?

A、3
B、4
C、5
D、6
答案:D
解析:依赖关系图中的子决策树可以被看做是拥有外部连接的节点,例如:Media, networking, play, role, billions, 和 lives 是子决策树的根。

问题8:文本分类模型组成部分的正确顺序是:
1. 文本清理(Text cleaning) 2. 文本标注(Text annotation) 3. 梯度下降(Gradient descent) 4. 模型调优(Model tuning) 5. 文本到预测器(Text to predictors)
A、12345
B、13425
C、12534
D、13452
答案:C
解析:正确的文本分类模型包含――文本清理以去除噪声,文本标注以创建更多特征,将基于文本的特征转换为预测器,使用梯度下降学习一个模型,并且最终进行模型调优。

问题9:下列那种模型可以被用于文本相似度(document similarity)问题?
A、在语料中训练一个由词到向量(word 2 vector)的模型来对文本中呈现的上下文语境进行学习
B、训练一个词包模型(a bag of words model)来对文本中的词的发生率(occurrence)进行学习
C、创建一个文献检索词矩阵(document-term matrix)并且对每一个文本应用余弦相似性
D、上述所有方法均可
答案:D
解析:word2vec 模型可在基于上下文语境的情况下用于测量文本相似度。词包模型(Bag Of Words)和文献检索词矩阵(document term matrix)可以在基于词条的情况下用来测量相似度。

问题10:下列哪些是语料库的可能性特征?
1. 文本中词的总数 2. 布尔特征――文本中词的出现 3. 词的向量标注 4. 语音标注部分 5. 基本依赖性语法 6. 整个文本作为一个特征
A、1
B、12
C、123
D、1234
E、12345
F、123456
答案:E
解析:除了全部文本作为特征这个选项,其余均可被用作文本分类特征,从而来对模型进行学习。
帮助数千人成功上岸的《名企AI面试100题》书,电子版,限时免费送,评论区回复“100题”领取!
本书涵盖计算机语?基础、算法和?数据、机器学习、深度学习、应??向 (CV、NLP、推荐 、?融风控)等五?章节,每?段代码、每?道题?的解析都经过了反复审查或review,但不排除可能仍有部分题?存在问题,如您发现,敬请通过官?/APP七月在线 - 国内领先的AI职业教育平台 (julyedu.com)对应的题?页?留?指出。
为了照顾?家去官?对应的题?页?参与讨论,故本?册各个章节的题?顺序和官?/APP题库内的题?展?顺序 保持?致。 只有100题,但实际笔试?试不?定局限于本100题,故更多烦请?家移步七?在线官?或 七?在线APP,上?还有近4000道名企AI笔试?试题等着?家,刷题愉快。
