期末课程设计(葡萄酒的分类)
代码:
#蓝桥社区的课程实验代码
import matplotlib.pyplot as plt
import pandas as pd
import tensorflow as tf
from sklearn.utils import shuffle
from sklearn import preprocessing
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
# %matplotlib inline
#数据预处理(为数据减去偏差)
df=pd.read_csv("./wine.csv",header=0)
print(df.describe())
for i in range(1,8):
number=420+i
ax1=plt.subplot(number)
ax1.locator_params(nbins=3)
plt.title
ax1.scatter(df[df.columns[i]],df['Wine'])
plt.tight_layout(pad=0.4,w_pad=0.5,h_pad=1.0)
X = df[df.columns[1:13]].values
Y=df['Wine'].values-1
#预先打乱数据
X,Y=shuffle(X,Y)
scaler=preprocessing.StandardScaler()
X=scaler.fit_transform(X)
class Linear(tf.keras.Model):
def __init__(self):
super().__init__()
self.dense = tf.keras.layers.Dense(
units=3,
activation="softmax",
kernel_initializer=tf.zeros_initializer(),
bias_initializer=tf.zeros_initializer()
) # 全连接层 f.keras.layers.Dense
def call(self, input):
output = self.dense(input)
return output
tf.keras.backend.set_floatx('float64')
model = Linear()
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01) # 使用 SGD 优化器
sparse_categorical_accuracy = tf.keras.metrics.SparseCategoricalAccuracy()
for i in range(100):
X, Y = shuffle(X, Y, random_state=1)
Xtr = X[0:140, :]
Ytr = Y[0:140]
Xt = X[140:178, :]
Yt = Y[140:178]
Xtr, Ytr = shuffle(Xtr, Ytr, random_state=0)
# 使用交叉熵损失
with tf.GradientTape() as tape:
y_pred = model(Xtr)
loss = tf.keras.losses.sparse_categorical_crossentropy(y_true=Ytr, y_pred=y_pred)
loss = tf.reduce_mean(loss)
grads = tape.gradient(loss, model.variables)
optimizer.apply_gradients(grads_and_vars=zip(grads, model.variables))
y_pred_test = model.predict(Xt)
#在收敛性测试中,使用tf.keras.metrics.SparseCategoricalAccuracy计算该模型的准确度。
# 评估器,输出预测正确的样本数占总样本数的比例
sparse_categorical_accuracy.update_state(y_true=Yt, y_pred=y_pred_test)
print("test accuracy: %f" % sparse_categorical_accuracy.result())
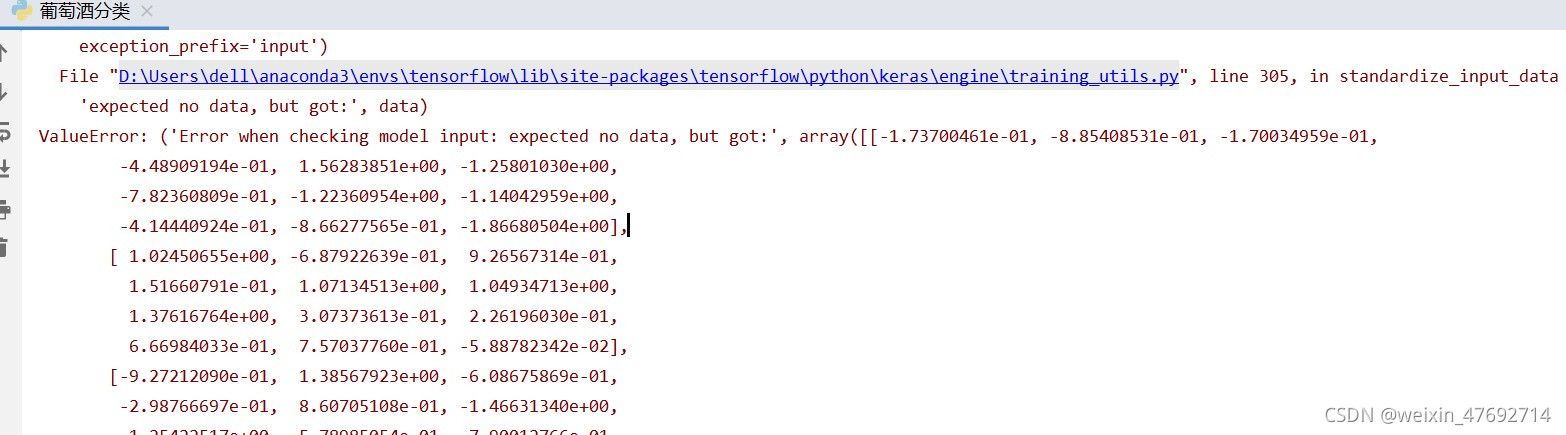
运行过程中的报错和解决方法:?
1.出现:“FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecate...”?
改成:np.dtype([("quint8", np.uint8, (1,))])? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ??
参考:??????解决python调用TensorFlow时出现FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecate_BigDream123的博客-CSDN博客?(点击警告里的链接,找到对应报错代码然后修改。)
2.“ValueError: ('Error when checking model input: expected no data, but got:', array([[-1.73700461e-01, -8.85408531e-01, -1.70034959e-01,”? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?
?出现这个着实让我不明觉厉)
?如图:)