2021SC@SDUSC
目录
MultiHeadAttention类和MatrixAttn类介绍
上篇博客对pargs.py中的方法进行了分析,因为generator.py中引用了newmodel.py中的model类,所以接下来会对newmodel.py中的方法进行分析。

torch.nn模块介绍
nn主要有四个模块:nn.Parameter,nn.Module,nn.functional和nn.__init__。
nn.Parameter: 一个张量的子类,用于表示可学习的参数 w,b
nn.Module: 网络层的基类,用于管理网络的属性,LeNet是一个module类,LeNet的子模块例如conv2,也是一个nn.module类
nn.functional:用于函数的实现,比如卷积运算,加法运算
nn.__init__:参数初始化方法
在newmodel.py中我们使用了nn.Module这个类,故要引入nn。
下面介绍一下nn.Module()类的主要属性
parameter : 用于存储和管理Parameter类
Module : 用于存储和管理Module类相关
buffers :存储缓冲属性,比如均值等
其他五个是用于管理钩子函数(_hocks())
MultiHeadAttention类和MatrixAttn类介绍
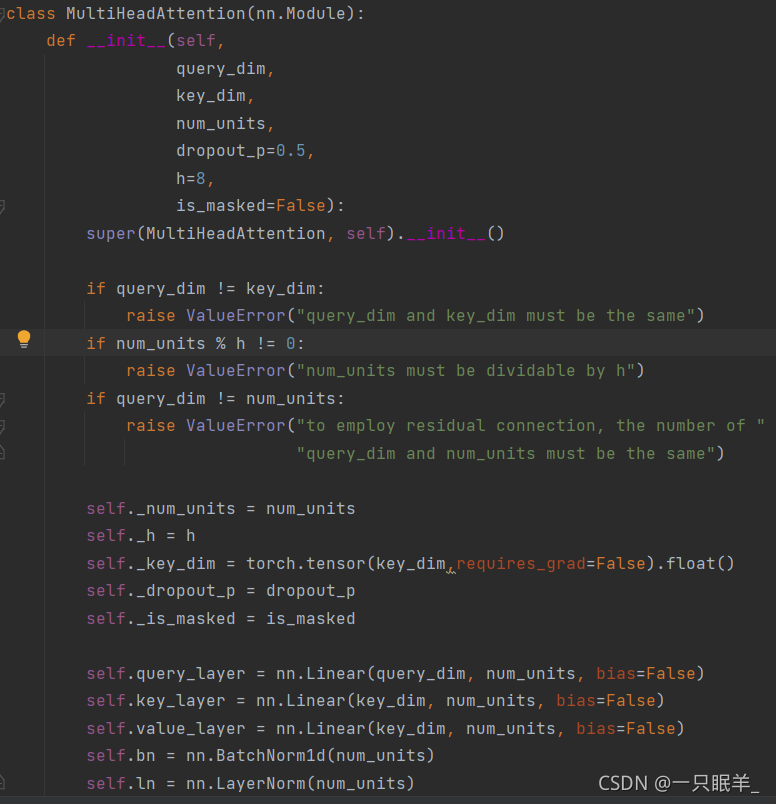
class MultiHeadAttention(nn.Module)://函数的参数是nn.Module类
def __init__(self,
query_dim,
key_dim,
num_units,
dropout_p=0.5,
h=8,
is_masked=False)://__init__中的参数,其中dropout_p,h和is_masked有默认值
super(MultiHeadAttention, self).__init__()//继承父类所有的特性(而不是基类),并且避免重复继承
if query_dim != key_dim:
raise ValueError("query_dim and key_dim must be the same")//如果不满足条件,抛出异常
if num_units % h != 0:
raise ValueError("num_units must be dividable by h")//如果不满足条件,抛出异常
if query_dim != num_units:
raise ValueError("to employ residual connection, the number of "
"query_dim and num_units must be the same")//如果不满足条件,抛出异常
//raise的作用:显式的抛出异常。当出现异常时,raise后面的语句就不会执行
self._num_units = num_units
self._h = h
self._key_dim = torch.tensor(key_dim,requires_grad=False).float()//输入,不需要求导
self._dropout_p = dropout_p
self._is_masked = is_masked
self.query_layer = nn.Linear(query_dim, num_units, bias=False)//输入样本大小,输出样本大小,该层不会学习加性偏差
self.key_layer = nn.Linear(key_dim, num_units, bias=False)//同上
self.value_layer = nn.Linear(key_dim, num_units, bias=False)//同上
self.bn = nn.BatchNorm1d(num_units)//定义一个归一化的函数bn,需要归一化的维度为num_units,其他参数即eps,momentum,affine,track_running_stats为默认
? self.ln = nn.LayerNorm(num_units)//期待输入大小num_units的输入形状,其他参数即eps,elementwise_affine为默认
//__init__中主要是初始化一些内部需要用到的state,所有放在构造函数__init__里面的层的都是这个模型的“固有属性”
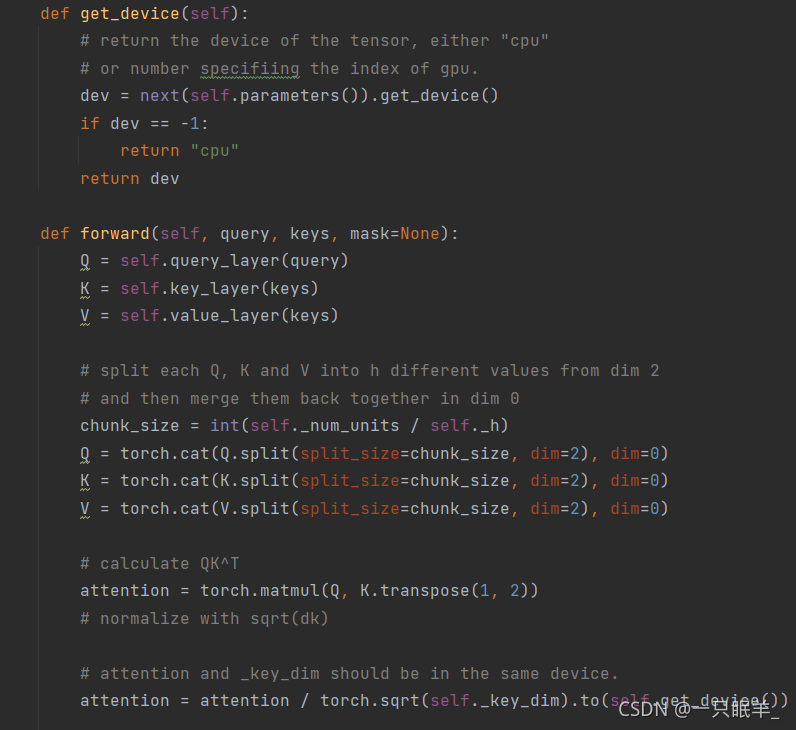
def get_device(self):
dev = next(self.parameters()).get_device()
if dev == -1:
return "cpu"
return dev//返回张量的设备,或“cpu”,或指定gpu索引的数字
def forward(self, query, keys, mask=None):
Q = self.query_layer(query)
K = self.key_layer(keys)
V = self.value_layer(keys)
//得到QKV
chunk_size = int(self._num_units / self._h)
Q = torch.cat(Q.split(split_size=chunk_size, dim=2), dim=0)
K = torch.cat(K.split(split_size=chunk_size, dim=2), dim=0)
V = torch.cat(V.split(split_size=chunk_size, dim=2), dim=0)
//将每个Q、K和V从尺寸2拆分为h个不同的值,然后将它们重新合并到0中
attention = torch.matmul(Q, K.transpose(1, 2))//计算QK^T
attention = attention / torch.sqrt(self._key_dim).to(self.get_device())//用sqrt(dk)标准化,注意和按键应在同一设备中。
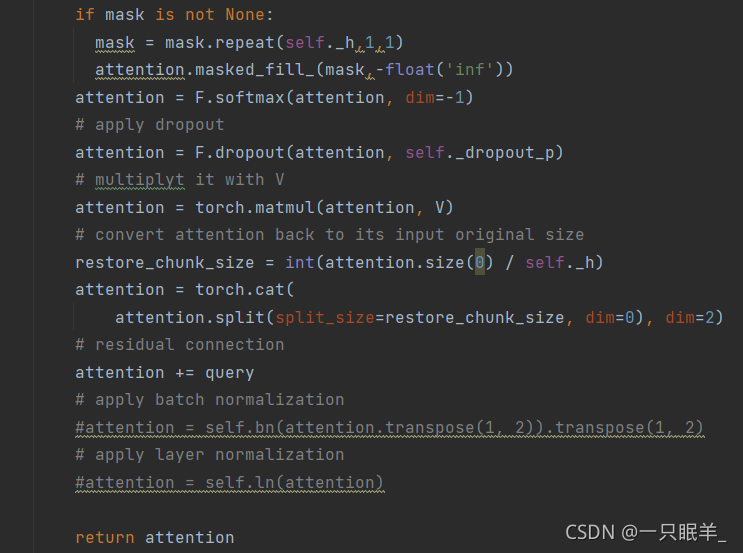
if mask is not None:
mask = mask.repeat(self._h,1,1)
attention.masked_fill_(mask,-float('inf'))
attention = F.softmax(attention, dim=-1)
attention = F.dropout(attention, self._dropout_p)//应用dropout
attention = torch.matmul(attention, V)//将其乘以V
restore_chunk_size = int(attention.size(0) / self._h)//转换回其输入的原始大小
attention = torch.cat(
attention.split(split_size=restore_chunk_size, dim=0), dim=2)
attention += query
return attention//返回结果
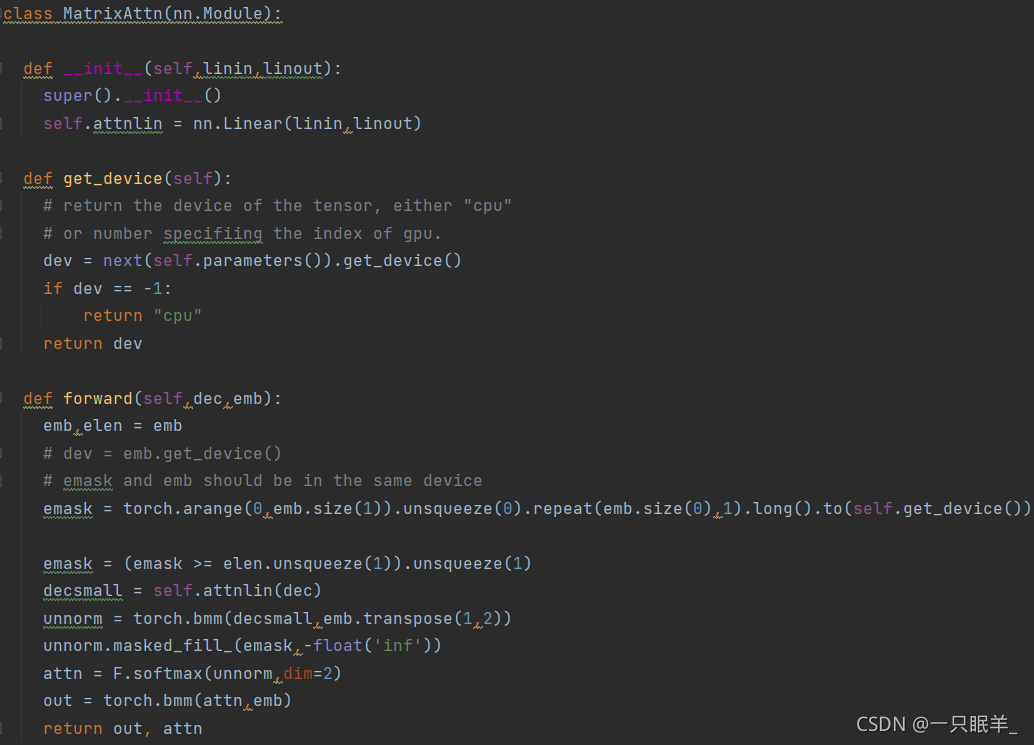
class MatrixAttn(nn.Module):
def __init__(self,linin,linout):
super().__init__()/继承父类所有的特性(而不是基类),并且避免重复继承
self.attnlin = nn.Linear(linin,linout)//输入样本大小,输出样本大小,该层会学习加性偏差
def get_device(self):
dev = next(self.parameters()).get_device()
if dev == -1:
return "cpu"
return dev//返回张量的设备,或“cpu”,或指定gpu索引的数字
def forward(self,dec,emb):
emb,elen = emb
emask = torch.arange(0,emb.size(1)).unsqueeze(0).repeat(emb.size(0),1).long().to(self.get_device())//emask和emb应位于同一设备中
emask = (emask >= elen.unsqueeze(1)).unsqueeze(1)
decsmall = self.attnlin(dec)
unnorm = torch.bmm(decsmall,emb.transpose(1,2))//传入参数,并对形状有要求
unnorm.masked_fill_(emask,-float('inf'))//进行填充
attn = F.softmax(unnorm,dim=2)//就是对unnorm矩阵中所有第2维下标不同,其他维下标均相同的元素进行操作(softmax)
out = torch.bmm(attn,emb)
return out, attn//返回结果