ժҪ
�ල����Ӧ(UDA)��Ԥ��ģ�ʹ���ȫ��ǵ�Դ��ת�Ƶ��ޱ�ǵ�Ŀ����Ȼ��,��ijЩӦ�ó�����,������Դ�����ռ���ǩ���ܰ���,��ʹ����ǰ�Ĵ��������������ʵ�ʡ�Ϊ�˽���������,����Ĺ���ִ���˻���ʵ���Ŀ��������Ҽලѧϰ,Ȼ����һ����������Ρ�Ȼ��,ʵ���Լලѧϰֻѧϰ�Ͷ���Ͳ�ε��б��������ڱ�����,���������һ���˵���ԭ�Ϳ����Լලѧϰ(PCS)�������С�����ල����Ӧ(FUDA)��PCS�����Կ���ͼ���������,���ҶԿ�����Ƕ��ռ��е�����ṹ���б���Ͷ��롣���ǵĿ��ͨ������ԭ�ͶԱ�ѧϰ�����ݵ��������ṹ;��ͨ���������ԭ�����Ҽල�����������롣��Ŀǰ���Ƚ��ķ������,PCS��FUDA�϶Բ�ͬ��Ե�ƽ�����ྫ�ȷֱ������10.5%��3.5%��9.0%��13.2%��
1. Introduction
�ල������Ӧ(UDA)��Ԥ��ģ�ʹ�һ����ȫ��ǵ�Դ��ת�Ƶ�һ��δ��ǵ�Ŀ������Ȼ��Ŀ������û�б�ǩ��Ϣ������¾�����ս��,������UDA��������Դ���зḻ����ʽ�ල,�Լ�δ��ǵ�Ŀ���������������,������Ŀ������ʵ�ֽϸߵľ��ȡ�
Ȼ��,��һЩʵ�ʵ�Ӧ�ó�����,����ע�͵ĸ߳ɱ����Ѷ�,��ʹ��Դ�����ṩ���ģע��Ҳ����������ս�ԡ���ҽѧ����Ϊ��,��������Ĥ�������ݼ���ÿһ��ͼ����һ����7��8������ίԱ����֤�ۿ�ҽ����ɵ�С��ע��,��С�鹲��54��ҽ�������,��ʵ�ʲ�����,�ٶ�Դ���ݾ��зḻ�ı�ǩ�ǹ����ϸ�ġ�
�ڱ�����,Ϊ��Ӧ��Դ��ı�dzɱ�,���ǿ�����С�����ල������Ӧ(FUDA)����,����ֻ�м�С����Դ���������,�������Դ��Ŀ����������δ��ǡ���������Ƚ���UDA����ͨ����С��ij����ʽ�ķֲ�����������Դ������Ŀ������,��ͨ����С����ȫ���Դ�����ݵļල��ʧ��ѧϰ�б��ʾ��Ȼ��,��FUDA��,�������ǵı��Դ���������dz�����,��˺���ѧϰԴ���еļ�������,������˵��Ŀ�������ˡ�
����ļ�ƪ�����Լලѧϰ (SSL) ������չʾ�˶����Ե������ͼ�����ϣ���ı���ѧϰ���,[39] ��һ����չ����������ִ�� SSL,�Ի�ø��õ�����Ӧ���ܡ��������������,[39] �еĻ���ʵ���ķ�����һЩ���������㡣����,���ݵ�����ṹ������ѧϰ���Ľṹ����ġ�������Ϊ [39] �е������Լල������ʵ����Ϊ����,ֻҪ�������Բ�ͬ������,������������������Ρ����,�������ͬ�����ʵ���������ռ��б����ܻ�ӭ���ƿ������,[39] �еĿ���ʵ����ʵ��ƥ����쳣�����dz����С�����һ�����,����Դ������Ŀ��������Ƕ������Զ(������ܴ�),����һ���쳣Դ�������κ�����Դ��������������Ŀ��������Ȼ�� [39] �еķ����Ὣ����Ŀ����������ͬ��Դ����ƥ��(�μ�ͼ 3)�����ڸ���������,�������е�ƥ��������ѵ�������п��ܻᷢ�����ұ仯,�Ӷ�ʹ�Ż���������������,���ιܵ�(�� SSL �������Ӧ)�ܸ���,ʵ�������ͬ���ݼ������ DA �����Dz�ͬ�ġ����,ѵ���൱����,���Ҳ��������ڵڶ�����Բ�ͬ�����ݼ�ѡ�����ŵ� DA ������
�ڱ�����,��������˵��͵Ŀ����Լලѧϰ,����һ����ӱ��FUDA�ĵ��ο��,������ʾѧϰ���������С������ǵ�Դ����ͳһ������PCS����������Ҫ��ɲ���,����ѧϰ������������������������,PCSִ�����ڵ����Լල,�����ݵ�����ṹ��ʽ���뵽Ƕ��ռ���,���ǻ���[41]�Ķ���,�����ǽ�һ�������������֪������Ϣ,��ÿ������ѧϰ���õ�����ṹ�����,PCSִ�п���ʵ����ԭ�͵�ƥ��,�Ը���׳�ķ�ʽ��֪ʶ��Դ���䵽Ŀ�ꡣ��һ��������ԭ��ƥ��(����һ���������Ƶ�ʵ���Ĵ�����Ƕ��)���Ƚ�,ʹ�Ż������ٶȸ���,������ʵ����ʵ����ƥ�䡣����,PCS��ԭ��ѧϰ�����ҷ���������,����Դԭ�ͺ�Ŀ��ԭ������Ӧ�ظ������ҷ���������Դԭ��ת�Ƶ�Ŀ��ԭ��,����Ŀ�����ϻ�ø��õ����ܡ�Ϊ�˽�һ���������ƥ���Ӱ��,���Dz�������ķ�������ø������������������֤��,�������С��,���൱���������ͼ�������Ԥ��֮��Ļ���Ϣ(MI)������:
(1)���������һ����ӱ��ԭ�Ϳ����Լලѧϰ��� (PCS),�����������ල����Ӧ��
(2)���ǽ�������ԭ����ͳһ���ල������Ӧ�ķ�ʽִ�и��õ�����ṹѧϰ���б�����ѧϰ�Ϳ�����롣
(3)��Ȼ�����ڸ��ӵ����ο����ѡ�����������䷽��,��PCS���Ժ������ڶ˵��������Ͻ���ѵ��,�����ڶ�������ݼ����Խϴ�ķ��ȳ����������Ƚ��ķ�����
2. Related Work
������Ӧ�� �ල������Ӧ(UDA)����˽�֪ʶ��һ����ȫ��ǵ�Դ��ת�Ƶ�һ��δ��ǵ�Ŀ��������⡣�����UDA�����������������ֲ������ϡ����ڲ���ķ�����ʽ�ؼ���Դ��Ŀ��֮������ƽ������(MMD),�Զ���������[47]���ʹ������MMD�����������Ϸֲ���[63]��[79]��һ������˶���Դ������Ŀ�������Ķ���ͳ�����ݡ��������ɶԿ�����ķ�չ,����������öԿ�ѧϰ�������ռ��н��������ķ��������,�Ѿ�����ͼ��ƽ�Ʒ���,ͨ��ִ�����ؼ���������һ���Ľ�������Ӧ��[60]û����ȷ����������,�������Ӧ�ļ�С�����ء���Щ������Դ�������ȫ�ļල,�������ǹ�ע����һ���µ���Դ��ǩ������Ӧ���á�
�Լලѧϰ�� �Լලѧϰ (SSL) ���ලѧϰ������һ���Ӽ�,���мල�Ǵ��������Զ����ɵġ� SSL ����IJ���֮һ���ֹ�������������������Ԥ��δ����ȱʧ����������Ϣ���ر���,ͼ����ɫ������λ��Ԥ�� ��ͼ��ƴͼ ��ͼ�����ͼ��α任 �ѱ�֤�����а����ġ�Ŀǰ,�Ա�ѧϰ�ڱ���ѧϰ��ȡ�������Ƚ������ܡ�������Աȷ������ǻ���ʵ����,ּ��ѧϰһ��Ƕ��ռ�,��������ͬһʵ�������������ø���,�����Բ�ͬʵ�����������ƿ������,����ԭ�͵ĶԱ�ѧϰ�ڱ���ѧϰ����ʾ����ϣ���Ľ����
����Ӧ���Լලѧϰ�� �����Լල�ķ����� SSL ��ʧ����ԭʼ�������硣��һЩ���ڹ�����,�ؽ����ȱ������Լල���� ,����Դ��Ŀ�깲����ͬ�ı���������ȡ��������Ϊ��ͬʱ�������ض���������,[5] ��ȷ�ؽ�ͼ���ʾ��ȡ�������ռ���,һ����ÿ����˽�е�,��һ���ǿ������ġ��� [6] ��,���ƴͼ��Ϸ [51] �������Լල�������������Ӧ�ͷ������⡣[64]��һ�����ͨ������ѧϰ������Ҽල������ִ����Ӧ��������������Դͼ���Ŀ��ͼ����,Ȼ����ȡ���������뵽��ͬ���Լල����ͷ�С����,����ʵ������ [72],[39] �����һ�ֿ��� SSL ����,������Ӧ����û��Դ��ǩ������� SSL Ҳ�����������������Ӧ,��������ʶ�� [1]��ҽѧ���� [33]�������ָ� [9]�������� [34]���沿���� [74] �ȡ�
3. Approach
��С�����ල����Ӧ��,���ǵõ��dz����������ı��Դͼ��
D
s
=
{
(
x
i
s
,
y
i
s
)
}
i
=
1
N
s
D_s=\{(x^s_i,y^s_i)\}^{N_s}_{i=1}
Ds?={(xis?,yis?)}i=1Ns??,�Լ�δ���Դͼ��
D
s
u
=
{
(
x
s
u
)
}
i
=
1
N
s
u
D_{su}=\{(x^{su})\}^{N_{su}}_{i=1}
Dsu?={(xsu)}i=1Nsu??����Ŀ������,����ֻ�õ�δ��ǵ�Ŀ��ͼ��
D
t
u
=
{
(
x
t
u
)
}
i
=
1
N
t
u
D_{tu}=\{(x^{tu})\}^{N_{tu}}_{i=1}
Dtu?={(xtu)}i=1Ntu??��Ŀ������
D
s
,
D
s
u
,
D
t
u
D_s,D_{su},D_{tu}
Ds?,Dsu?,Dtu?��ѵ��ģ��;����
D
t
u
D_{tu}
Dtu?�Ͻ���������
��ģ��������������
F
F
F��
?
2
?_2
?2?��һ����,�����һ����������
f
��
R
d
f��\R^d
f��Rd�ͻ����������ƶȵķ�����
C
C
C��ɡ�
3.1.����ԭ�ͶԱ�ѧϰ
����ѧϰ��һ����������������
F
F
F,������������������ȡ�б���������[39]��ʹ��ʵ���б�[72]��ѧϰ�б���������Ϊһ����ʵ���Ա�ѧϰ����,�������һ��Ƕ��ռ�,��������ʵ�����ܺõط��롣����ȡ���˿�ϲ�Ľ��,��ʵ��������һ������������:���ݵ�����ṹ������ѧϰ���ı�������ġ�������Ϊ����ʵ��ֻҪ���Բ�ͬ�������ͱ���Ϊ����,���������ǵ�������Ρ����ڵ�����,ProtoNCE����ͨ��ִ�е�������ͱ�ʾѧϰ��ѧϰ���ݵ�����ṹ��Ŀ�����ƶ�ͬһ��Ⱥ�е�������ø��Ӿۺ�,����ͬ��Ⱥ�е�������ø�Զ��
Ȼ��,�����ǵ�������Ӧ������,���صĽ�ProtoNCEӦ����
D
s
��
D
s
u
��
D
t
u
D_s \cup D_{su} \cup D_{tu}
Ds?��Dsu?��Dtu?�ᵼ��DZ�ڵ����⡣��Ҫ�������ת��,���Բ�ͬ��IJ�ͬ���ͼ����ܻᱻ����ؾۺϵ�ͬһ����Ⱥ��,�����Բ�ͬ���ͬһ���ͼ����Ա�ӳ�䵽����Զ�ļ�Ⱥ�С�Ϊ�˻�����Щ����,���ǽ�����
D
s
��
D
s
u
D_s \cup D_{su}
Ds?��Dsu?��
D
t
u
D_{tu}
Dtu?�зֱ�ִ��ԭ�ͶԱ�ѧϰ�����Ƿ�ֹ�������ͼ�����Ͳ������ֵ�����ѧϰ��
������˵,�ֱ�ΪԴ��Ŀ��ά�������洢
V
s
V^s
Vs��
V
t
V^t
Vt:
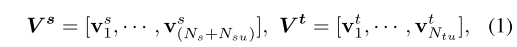
����
v
i
v_i
vi?��
x
i
x_i
xi?�Ĵ洢��������,��
f
i
f_i
fi?��ʼ������ÿ�����ö��� m ����:
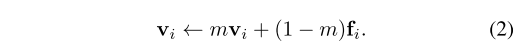
Ϊ�˽�������ԭ�ͶԱ�ѧϰ,��
V
s
V^s
Vs��
V
t
V^t
Vt���� k-means ����,�õ�Դ��Ⱥ
C
s
=
{
C
1
(
s
)
,
C
2
(
s
)
,
��
C
k
(
s
)
}
C^s=\{C^{(s)}_1, C^{(s)}_2,��C^{(s)}_k\}
Cs={C1(s)?,C2(s)?,��Ck(s)?}�����Ƶ���������Դԭ��
{
��
j
s
}
j
=
1
k
\{{\mu}^s_j\}^k_{j=1}
{��js?}j=1k?������Ŀ��ԭ��
{
��
j
t
}
j
=
1
k
\{{\mu}^t_j\}^k_{j=1}
{��jt?}j=1k?��
C
t
C^t
Ct��������˵,
��
j
s
=
u
j
s
�O
�O
u
j
s
�O
�O
{\mu}^s_j=\frac{u^s_j}{||u^s_j||}
��js?=�O�Oujs?�O�Oujs??,����
u
j
s
=
1
�O
C
j
(
s
)
�O
��
v
i
s
��
C
j
(
s
)
v
i
s
u^s_j=\frac{1}{|C^{(s)}_j|}\sum_{v_i^s \in C^{(s)}_j}v_i^s
ujs?=�OCj(s)?�O1?��vis?��Cj(s)??vis?������ֻ��Դj���Ͻ��ͼ���ʾ,���в�������Ŀ����ִ�С�
��ѵ��������,������������
F
F
F������������
f
i
s
=
F
(
x
i
s
)
f^s_i=F(x^s_i)
fis?=F(xis?)��Ϊ�˽�������ԭ�ͶԱ�ѧϰ,���Ǽ���
f
i
s
f^s_i
fis?��
{
��
j
s
}
j
=
1
k
\{{\mu}^s_j\}^k_{j=1}
{��js?}j=1k?֮������Ʒֲ�����,��ʽΪ
P
i
s
=
[
P
i
,
1
s
,
P
i
,
2
s
,
.
.
.
,
P
i
,
k
s
]
P_i^s=[P_{i,1}^s,P_{i,2}^s,...,P_{i,k}^s]
Pis?=[Pi,1s?,Pi,2s?,...,Pi,ks?],����:
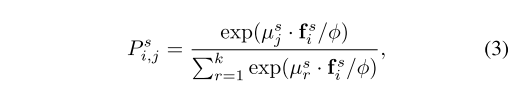
���Ц���ȷ��Ũ��ˮƽ���¶�ֵ��������ԭ�ͶԱ���ʧ����дΪ
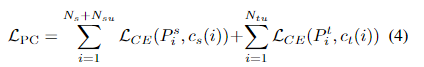
����
c
s
(
?
)
c_s(��)
cs?(?)��
c
t
(
?
)
c_t(��)
ct?(?)����ʵ���ļ�Ⱥ���������ھ���������,���ǶԲ�ͬ��������
{
k
m
}
m
=
1
M
\{k_m\}^M_{m=1}
{km?}m=1M?������ִ��M��k-means������,��FUDA������,������
n
c
n_c
nc?����������֪��,��������Ϊ�����m������
k
m
=
n
c
k_m=n_c
km?=nc?�����ڲ��Լල��������ʧΪ:
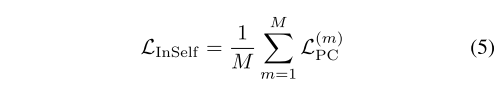
3.2. Cross-domain Instance-Prototype SSL
Ϊ����Դ���Ŀ��������ȷ��ǿ��ִ��ѧϰ�������������Ե�����,����ִ���˿���ʵ��-ԭ���Լලѧϰ��
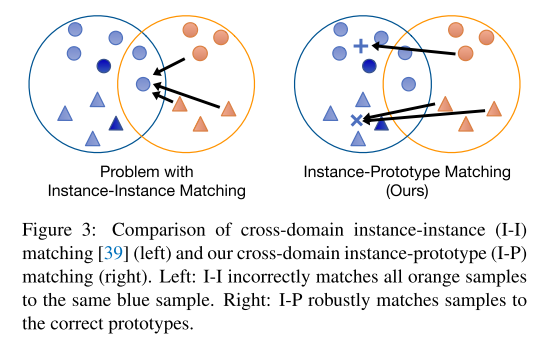
������ǰ�Ĺ�����������ͨ��������С����Կ���ѧϰ�����е���������ϡ�Ȼ��,��Щ�����ı��ֽϲ��ѵ�����ȶ�������,���Ǵ�༯���ڷֲ�ƥ��,��û�п��ǿ��������������ƥ�䡣�����ʵ��-ʵ��ƥ��[39]����һ��ʵ�� i ����һ�����е���һ��ʵ�� j ����ƥ�䡣����,�������϶,ʵ�����Ժ�����ӳ�䵽�������еIJ�ͬ���ʵ������ijЩ�����,���һ�����е�һ���쳣ֵ�dz��ӽ���һ����,��ô��������һ�����е�����ʵ����ƥ��,��ͼ3��ʾ��
�෴,���ǵķ��������˲�ͬ����ʵ���ͼ�Ⱥԭ��֮�����ƥ���ƥ�䡣Ϊ���ҵ�ʵ�� i ��ƥ��,���Ƕ����ʾ֮��������Էֲ�����ִ������С��,����
f
i
s
f^s_i
fis?����һ���������
{
��
j
t
}
j
=
1
k
\{{\mu}^t_j\}^k_{j=1}
{��jt?}j=1k?��
������˵,����Դ�����������
f
i
s
f^s_i
fis?,Ŀ���������
{
��
j
t
}
j
=
1
k
\{{\mu}^t_j\}^k_{j=1}
{��jt?}j=1k?,���ȼ���Ŀ��������ƶȷֲ�����
P
i
s
��
t
=
[
P
i
,
1
s
��
t
,
��
,
P
i
,
k
s
��
t
]
P^{s��t}_i=[P^{s��t}_{i,1},��,P^{s��t}_{i,k}]
Pis��t?=[Pi,1s��t?,��,Pi,ks��t?],����
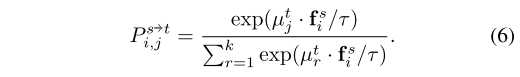
Ȼ��������С��
P
i
s
��
t
P^{s��t}_i
Pis��t?����,��:
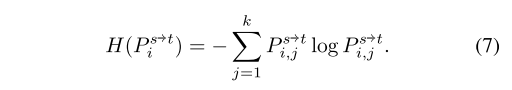
���Ƶ�,���ǿ��Լ���
H
(
P
i
t
��
s
)
H(P^{t��s}_i)
H(Pit��s?),����ʵ��-ԭ��SSL��������ʧ��:
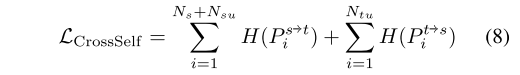
3.3. Adaptive Prototypical Classi?er Learning
���ڵ�Ŀ����ѧϰһ�����õ�����롢�б�������������
F
F
F,����Ҫ����,ѧϰһ��������Ŀ������ʵ�ָ߾��ȵ����ҷ�����
C
C
C��
���ҷ����� C ��Ȩ������
W
=
[
w
1
,
w
2
,
.
.
.
,
w
n
c
]
W = [w_1,w_2, . . . ,w_{n_c}]
W=[w1?,w2?,...,wnc??],����
n
c
n_c
nc?��ʾ����������¶�T��C�����,
1
T
W
T
f
\frac{1}{T}W^Tf
T1?WTf������ softmax ��
��
��
�� �Ի�����ո������
p
(
x
)
=
��
(
1
T
W
T
f
)
p(x) = ��(\frac{1}{T}W^Tf)
p(x)=��(T1?WTf)�����ű�Ǽ�
D
s
D_s
Ds?�Ŀ�����,ʹ�ñ���������ʧѵ��
F
F
F��
C
C
C���з���ܼ�:
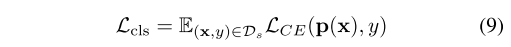
Ȼ��,����
D
s
D_s
Ds?��FUDA�����¹�ģ�൱С,ֻ��
L
c
l
s
L_{cls}
Lcls?ѵ��������Ŀ���ϻ�ø����ܵķ�����
C
C
C��
����Ӧԭ�ͷ��������� (APCU)�� ��ע��,Ϊ���� C ��ȷ��������,Ȩ������
w
i
w_i
wi?�ķ�����Ҫ������Ӧ���
i
i
i�������������
w
i
w_i
wi?�������
i
i
i�����뼯Ⱥԭ��һ�¡����ǽ���ʹ�ö����뼯Ⱥԭ�͵Ĺ���������
W
W
W�� Ȼ��,�������
{
u
j
s
}
\{u^s_j\}
{ujs?}��
{
u
j
t
}
\{u^t_j\}
{ujt?}����ֱ�ӵ����ڴ�Ŀ��,������Ϊ
{
w
i
}
\{w_i\}
{wi?}��
{
u
j
}
\{u_j\}
{uj?}֮��Ķ�Ӧ��ϵ��δ֪��,���� k-means ������ܰ����dz������ļ�Ⱥ,���²����д����Ե�ԭ�͡�
����ʹ��С������ǵ������Լ����и����Ŷ�Ԥ�������������ÿ�����ԭ�͡���ʽ��,���Ƕ���
D
s
(
i
)
=
{
x
�O
(
x
,
y
)
��
D
s
,
y
=
i
}
D^{(i)}_s=\{x|(x,y)��D_s,y=i\}
Ds(i)?={x�O(x,y)��Ds?,y=i},����
D
s
u
(
i
)
D^{(i)}_{su}
Dsu(i)?��
D
t
u
(
i
)
D^{(i)}_{tu}
Dtu(i)?�ֱ��ʾ��Դ��Ŀ���Ͼ��и����ű�ǩ i ����������
p
(
x
)
=
[
p
(
x
)
1
,
��
,
p
(
x
)
n
c
]
,
D
s
u
(
i
)
=
{
x
�O
(
x
,
y
)
��
D
s
u
,
p
(
x
)
i
>
t
}
p(x)=[p(x)_1,��,p(x)_{n_c}],D^{(i)}_{su}=\{x|(x,y)��D_{su},p(x)_i > t\}
p(x)=[p(x)1?,��,p(x)nc??],Dsu(i)?={x�O(x,y)��Dsu?,p(x)i?>t},����
t
t
t��һ��������ֵ,
D
t
u
(
i
)
D^{(i)}_{tu}
Dtu(i)?���ơ�Ȼ���Դ���Ŀ�����
w
i
w_i
wi?���ƿ��Լ���Ϊ:
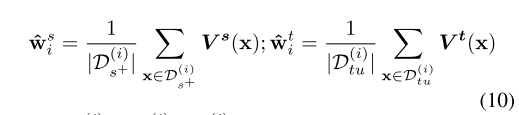
����,
D
s
+
(
i
)
=
D
s
(
i
)
��
D
s
u
(
i
)
D^{(i)}_{s+}=D^{(i)}_s \cup D^{(i)}_{su}
Ds+(i)?=Ds(i)?��Dsu(i)?��
V
(
x
)
V(x)
V(x)�����ڴ���ж�Ӧ��
x
x
x�ı�ʾ��ʽ��
����Դ��ֻ�к��ٵı������,��˺���ѧϰ�������Ĵ�����ԭ�͡�����û��ֱ��Ϊ��
i
i
iʹ��ȫ��ԭ��,���ǽ�һ��������������Ӧ��ʽ����
w
i
w_i
wi?,������ѵ����ʹ��
w
^
i
s
\hat{w}^s_i
w^is?,�ں���ʹ��
w
^
i
t
\hat{w}^t_i
w^it?��������Ϊ
w
^
i
s
\hat{w}^s_i
w^is?������ѵ���θ����Ƚ�,��Ϊ��ǵ�Դ��������,��
w
^
i
t
\hat{w}^t_i
w^it?�����Ժ���ܴ���Ŀ�����Ի�ø��õ���Ӧ���ܡ�������˵,����ʹ��
�O
D
t
u
(
i
)
�O
|D^{(i)}_{tu}|
�ODtu(i)?�Oȷ��
w
^
i
t
\hat{w}^t_i
w^it?�Ƿ��Ƚ�ʹ��:
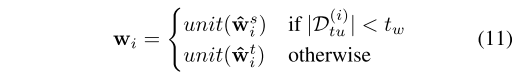
����,
u
n
i
t
(
?
)
unit(\cdot)
unit(?)������������һ��,
t
w
t_w
tw?��һ����ֵ��������
����Ϣ��� Ϊ��ʹ����ͳһԭ�ͷ�����ѧϰ��ʽ�ܹ���������,������Ҫ���㹻�ɿ���Ԥ��,����
�O
D
(
i
)
�O
>
t
w
|D^{(i)}| > t_w
�OD(i)�O>tw?,����������,����Ƚ���
w
^
i
s
\hat{w}^s_i
w^is?��
w
^
i
t
\hat{w}^t_i
w^it?,
i
=
1
,
.
.
.
,
n
c
i=1,...,n_c
i=1,...,nc?������,Ϊ�˴ٽ����������ݼ��ϵĶ��������,���������Ԥ������Ԥ��
H
(
E
x
��
D
[
p
(
y
�O
x
;
��
)
]
)
\mathcal{H}(E_{x��D}[p(y|x;��)])
H(Ex��D?[p(y�Ox;��)])����,����
��
��
����ʾ
F
F
F��
C
C
C�еĿ�ѧϰ����,�Լ�
D
=
D
s
��
D
s
u
��
D
t
u
D=D_s \cup D_{su} \cup D_{tu}
D=Ds?��Dsu?��Dtu?�����,Ϊ�˶�ÿ���������и����ŵ�Ԥ��,�����������������������С��,���ڱ�ǩϡȱ�ij�������ʾ������Ч�ԡ���������������Ϊ�ȼ��������������֮��Ļ���Ϣ:
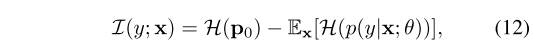
����,����ֲ�
p
0
p_0
p0?��
H
(
E
x
��
D
[
p
(
y
�O
x
;
��
)
]
)
\mathcal{H}(E_{x��D}[p(y|x;��)])
H(Ex��D?[p(y�Ox;��)])����,��ϸ���Ƶ������������ϡ����ǿ���ʵ������Ŀ��:
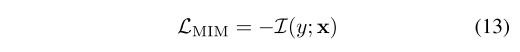
3.4. PCS Learning for FUDA
PCSѧϰ���ִ������ԭ�ͶԱ�ѧϰ������ʵ��ԭ���Լලѧϰ��ͳһ������Ӧԭ�ͷ�����ѧϰ����ͬEq.11�е�APCU,����ѧϰĿ����:
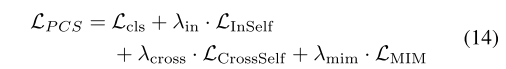
4. Experiments
4.1. Experimental Setting
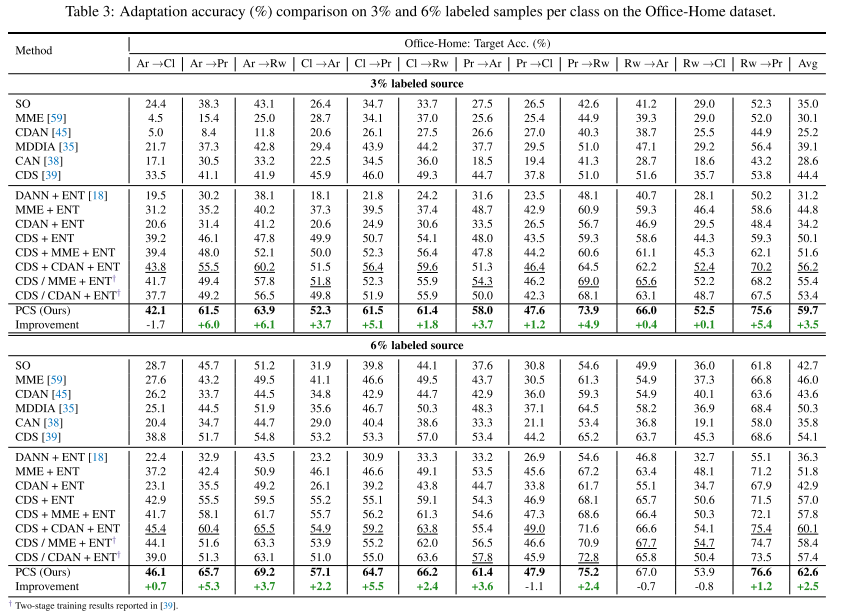
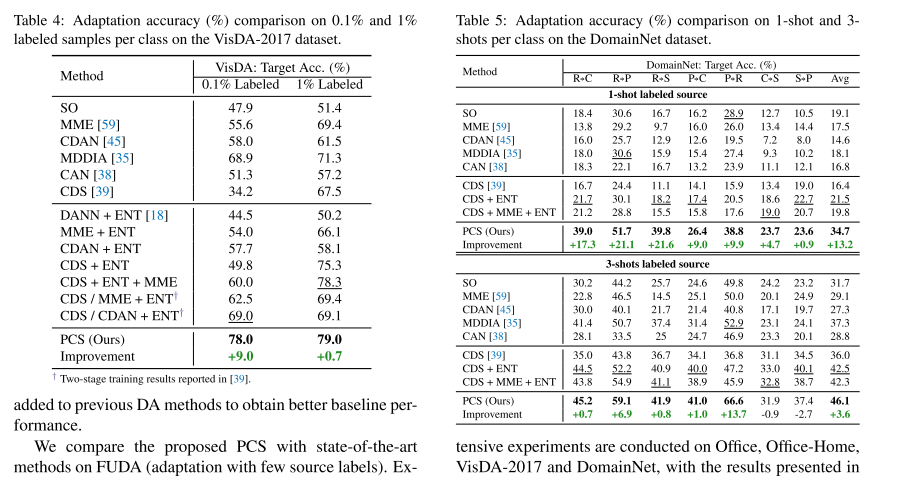
���ݼ��� �������ĸ��������ݼ������������ǵķ���,����֮ǰ�Ĺ���[39]�Ļ�����ѡ����Դ���еı��ͼ��Office[58]��һ��������������Ӧ�������ʵ���ݼ���������3����(����ѷ,DSLR,��������ͷ),��31���ࡣʵ���ڸ����ݼ���,ÿ����ʹ��1�κ�3�ε�Դ��ǩ���С�Office-Home[69]��һ����Office�����ѵ����ݼ�,����65�����е�4������(��������ֽ��������Ʒ����ʵ)��ɡ���[39]֮��,���Dz鿴ÿ������3%��6%���Դͼ�������,����ζ��ÿ����ƽ����2��4�����ͼ��VisDA-2017[55]��һ��������ս�Ե�ģ���ʵ�����ݼ�,������12����ij���280K��ͼ����[39]�Ľ���,���Ƕ�ÿ����ʹ��0.1%��1%���Դͼ���Դͼ��������֤�����ǵ�ģ�͡�����[54]��һ�����ģ����������Ӧ��������һЩ���������������,������ѭ[59],��ʹ��һ�������ĸ���(��ֽ��������ʵ���滭������)���Ӽ���126���ࡣ������������ݼ�����ʾ��ʹ��1�κ�3��Դ��ǩ���õĽ����
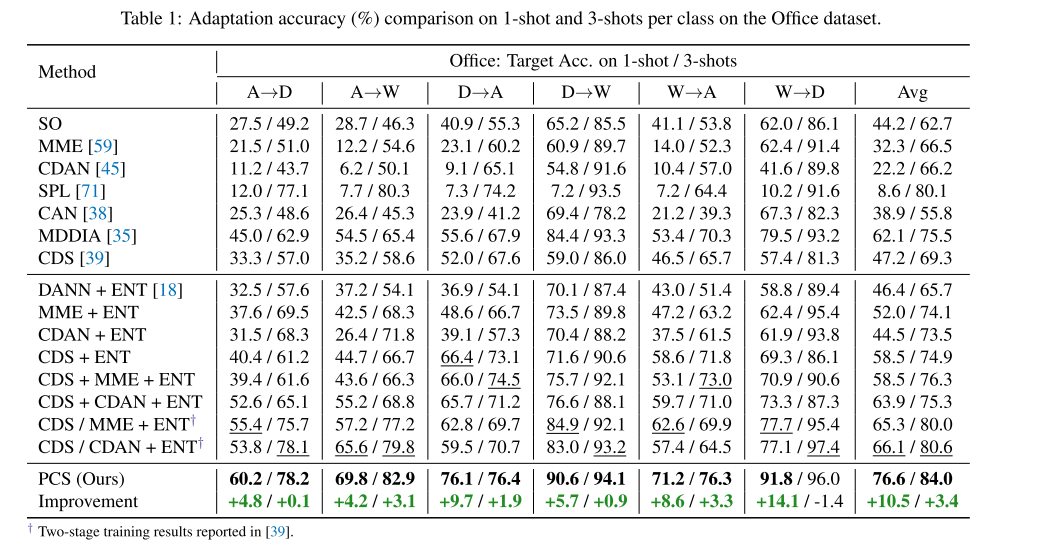

ʵ��ϸ�ڡ� ����ʹ����ResNegeNet��Ԥѵ����(��������)��ResNet-101��ResNet-50(�����������ݼ�)��Ϊ���ǵĹǸɡ�Ϊ����[39]���й�ƽ�ıȽ�,���ǽ����һ��FC���滻Ϊһ��512-D�����ʼ�������Բ㡣�������������L2��һ�������������ڿ���[37]��ʹ��k-means GPUʵ����ʵ����Ч�ľ��ࡣ����ʹ��SGD,����Ϊ0.9,ѧϰ��Ϊ0.01,��������СΪ64�������ʵʩϸ�ڿ����ڲ���������ҵ���

5. Conclusion
�ڱ�����,�����о���Դ��ֻ�������������,Ŀ����û�б��������С�����ල����Ӧ�����������һ���µ�ԭ�Ϳ����Լලѧϰ(PCS)���,�ÿ�ܿ���ͬʱִ�����ںͿ���ԭ���Լලѧϰ,�Լ�����Ӧԭ�ͷ�����ѧϰ�������ڶ�������ݼ��Ͻ����˴�����ʵ��,֤����PCS������������ѷ�����PCSΪС�����ල��������Ӧ�趨��һ���µļ���״̬��