文章标题:Semi-Supervised Semantic Segmentation with Cross-Consistency Training
文章地址:https://arxiv.org/abs/2003.09005
文章代码: https://github.com/yassouali/CCT
领域:半监督语义分割
小白入坑笔记,有理解不对的地方,欢迎各位大佬指正

一、Cross-Consistency Training提出的原因

在语义分割领域标签获得成本较高,作者希望利用更多的未标记例子来训练分割网络,从而有效处理与训练数据分布相同的测试数据
从上图可以看出,低密度区域在隐藏表示中比在输入中更明显。在Input level 中,低密度区域无法与类别边界对齐,因此聚类假设不适用;在Hidden representations level 各个类别更紧凑,与其他类别界限明显。因此,就想到利用编码器的输出来增强模型不同形式的扰动的一致性
二、算法流程及特点
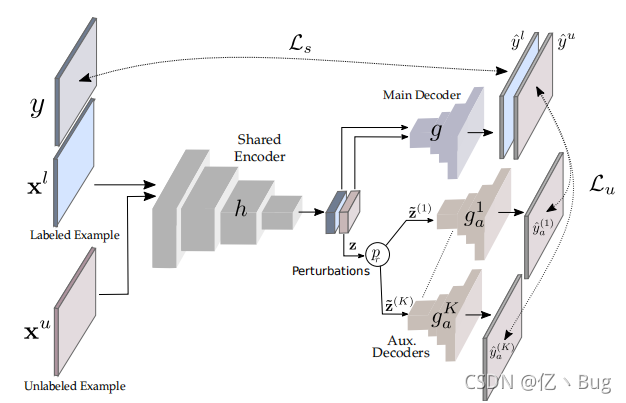

模型结构主要是:一个共享的编码器和一个主解码器,它们使用标记的例子进行训练。为了利用未标记的数据,用多个辅助解码器,它们的输入是共享编码器输出的扰动版本。
算法流程:在每次训练迭代中,从标记的Dl和未标记的Du集中采样相同数量的例子。使用主编码器的输出Z,遍历K个辅助解码器,对每个辅助解码器通过相同的扰动方式添加不同的扰动结果(后面结果部分有对应解释)。对于未标记的例子,计算每个辅助解码器的预测与主解码器的预测之间的MSE。然后计算总损失并反向传播。请注意,无监督损失Lu并没有通过主解码器g进行反向传播,只有标记的例子被用来训练g。
一致性训练的目的是在应用于输入的小扰动下,强制执行模型预测的不变性。因此,学习到的模型将对如此小的变化具有鲁棒性。一致性训练的有效性在很大程度上取决于数据分布的行为,即聚类假设,其中类必须被低密度区域分开。
损失:
上面算法流程是针对有标记和无标记的情况,并没有写对弱标记样本的损失Lw
在每次训练迭代中,我们采样等数量的标记和未标记样本。因此,我们在集合Dl上的迭代次数比在其未标记的对应物Du上的迭代次数更多,从而存在对标记集合Dl的过拟合的风险。(Dl的样本数远小于Du)
因此作者对Ls进行了改动:
只计算概率小于阈值η的像素上的监督损失:为了释放有监督的训练信号,阈值参数η在训练开始时从1/C逐渐增加到0.9,以C为输出类数。
改动前:
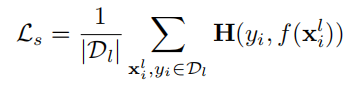
改动后:
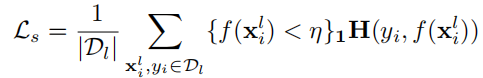
我的理解:在前期的时候,概率小于阈值的都是无标签样本,此时更需要注重无标签样本,因此针对无标签样本进行惩罚,让模型能够迅速学习无标签样本的分布,到了后期,模型学到了无标签的分布情况,那么此时预测错误的既有可能是无标签样本,也有可能是有标签样本,且要对有标签的样本,模型预测做出惩罚,发挥有标签样本的作用,如果阈值一直很小那就光学习无标签样本去了,所以阈值要变大。
模型表现:
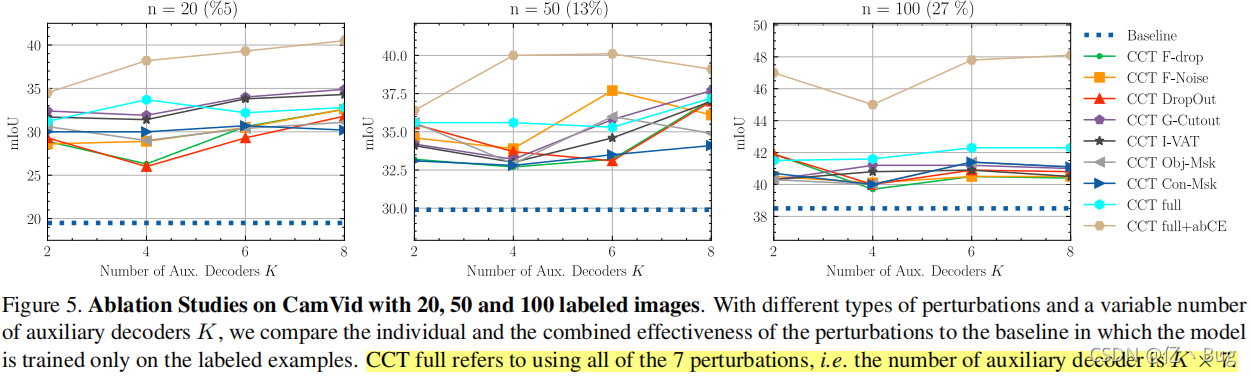
这里横轴表示辅助解码器的数量,比如最左边的图最下面的红色三角形表示,在扰动方法是DropOut,辅助解码器共4个的情况
不同的颜色的线代表不同的扰动方法
特别的CCT full表示使用以上七种全部的扰动方法,辅助解码器的数量是7*K。CCT full+abCE表示使用上面考虑修正的Ls,即考虑过拟合的情况
上面的结果表明,
1.不同扰动之间存在不显著的总体性能差距,证实了对语义分割隐藏表示的一致性的有效性。即作者的出发点:低密度区域在隐藏表示中比在输入中更明显是正确的
2.增加K总体上有轻微的改善,由于Con-Msk和Obj-Msk缺乏随机性,其变化最小。在结合所有扰动时也观察到一个轻微的改进,这表明编码器能够生成在许多扰动下生成一致的表示,从而提高整体性能
3.使用ab-CE逐步释放训练信号有助于提高8%,这证实了标记例子的过拟合会导致性能显著下降。
这里结果只是原文的一小部分,作者还进行了很多消融实验,感兴趣的可以自己去看原文