? ? ? ? ОіВпЪїетвЛеТНквбОаДЙ§РрЫЦЕФСЫ:ОпЬхЕФЬиеїбЁдёЫуЗЈПЩвдПДвдЧАЕФЮФеТ:
ЁЖЭГМЦбЇЯАЗНЗЈЁЗОіВпЪїМАМєжІ,ЛиЙщЪїЗжРрЪї
? ? ? ? РяУцЖМЯъЯИЕиНщЩмСЫID3,C4.5,ЛЙгаGINIЯЕЪ§Ш§жжЬиеїбЁдёЗНЗЈСЫ
????????
? ? ? ? Г§ДЫжЎЭт,ЪщЩЯЛЙЬсИпСЫЫћУЧжЎМфЕФЖдБШ,етРяПЩвдзХжиПДвЛЯТ:
1. ID3 КЭC4.5 ЕФЬсЩ§ЕудкФФРя
? ? ? ? етРяЦфЪЕЩЯУцЬсЕНЕФЮФеТвВЫЕСЫ,ЕЋЪЧетРядйЫЕвЛДЮ:
? ? ? ? ID3ЛсгХЯШбЁдёФЧаЉЬиеїЕФШЁжЕНЯЖрЕФЬиеї,ИљОнДЫЬиеїЛЎЗжИќШнвзЕУЕНДПЖШИќИпЕФзгМЏ,вђДЫЛЎЗжжЎКѓЕФьиИќЕЭ,гЩгкЛЎЗжЧАЕФьиЪЧвЛЖЈЕФ,вђДЫаХЯЂдівцИќДѓ,вђДЫаХЯЂдівцБШНЯ ЦЋЯђШЁжЕНЯЖрЕФЬиеїЁЃздМКЕФЛАРэНтОЭЪЧ,вђЮЊЮветИіЬиеїЕФШЁжЕПЩвдЗЧГЃЖр,ЫљвдПЩвдЗЧГЃКУЕиЙ§ФтКЯЕиЪЪгІбЕСЗМЏЕФЪ§Он,ЫљвдЮвУЧПЩвдИќШнвзЕУЕНДПЖШИќИпЕФзгМЏ,ДгЖјЪЙЕУаХЯЂдівцБШИќМгИпЁЃ
? ? ? ? ID3ЕФЙцдђЯТ,аХЯЂдівцдНДѓ,ДњБэетИіЬиеїдНЙмгУ,ЮвУЧгІИУбЁ
? ? ? ? Ыљвд C4.5ОЭЛсдк дкID3ЕФЛљДЁЩЯ(аХЯЂдівцЕФЛљДЁЩЯ)ГЫЩЯвЛИіГЭЗЃВЮЪ§ЁЃЬиеїИіЪ§НЯЖрЪБ,ГЭЗЃВЮЪ§НЯаЁ;ЬиеїИіЪ§НЯЩйЪБ,ГЭЗЃВЮЪ§НЯДѓЁЃгУРДЖєжЦID3вђЮЊШЁжЕЖрЖјНсЙћДѓЕФЧщПі
? ? ? ? дйЛЛОфЛАЫЕОЭЪЧЯждкКђбЁЬиеїжаевГі аХЯЂдівц ИпгкЦНОљЫЎЦНЕФЬиеї,ШЛКѓдкетаЉЬиеїжадйбЁдё аХЯЂдівцБШ?зюИпЕФЬиеїЁЃ?
2. ID3 жЛФмДІРэРыЩЂБфСП,C4.5КЭCARTПЩвдДІРэСЌајБфСП
? ? ? ??ЦфЪЕID3КЭC4.5ДІРэСЌајБфСПБОжЪЩЯЖМЪЧдкСЌајЕФБфСПРяУц,евЕНЧаЗжЕу,АбСЌајЕФЪєадзЊЛЏГЩВМЖћРраЭ,ДгЖјНЋСЌајабБфСПзЊЛЛЖрИіШЁжЕЧјМфЕФРыЩЂаЭБфСП(ШчЙћгаNЬѕбљБО,ФЧУДЮвУЧгаN-1жжРыЩЂЛЏЕФЗНЗЈ:<=vjЕФЗжЕНзѓзгЪї,>vjЕФЗжЕНгвзгЪїЁЃМЦЫуетN-1жжЧщПіЯТзюДѓЕФаХЯЂдівцТЪЁЃ)СэЭт,ЖдгкСЌајЪєадЯШНјааХХађ(Щ§ађ),жЛгадкОіВпЪєад(МДЗжРрЗЂЩњСЫБфЛЏ)ЗЂЩњИФБфЕФЕиЗНВХашвЊЧаПЊ,етПЩвдЯджјМѕЩйдЫЫуСП
????????C4.5ЖдСЌајЪєадЕФДІРэ:(КЭCARTвЛбљЪЧЖўВцЗжСб)

? ? ? ? ЗДЙлCART:ВЛЙмЪЧЗжРрЛЙЪЧЛиЙщ
????????ЗжРрЪЧМЦЫуЯжгаЬиеїЖдИУЪ§ОнМЏЕФЛљФсжИЪ§ЁЃДЫЪБЖдУПвЛИіЬиеїA,ЖдЦфПЩФмШЁЕФУПвЛИіжЕa,ИљОнбљБОЕуЖдA=aЕФВтЪдЮЊЁАЪЧЁБЛђЁАЗёЁБНЋDЗжИюГЩD1КЭD2СНИізгМЏ,ШЛКѓШЅМЦЫуетИіA=aЪБЖдетИіМЏКЯЕФЛљФсЯЕЪ§
? ? ? ? ЛиЙщЪЧРћгУзюаЁЛЏЫ№ЪЇКЏЪ§ШЅзі:етРяЕФЧаЗжБфСПКЭЧаЗжЕуВЛЪЧвЛвЛЖдгІЕФ,ЯШБщРњj,ШЛКѓдкУПИіjЩЯгжШЅБщРњs,Р§зг:ЧаЗжБфСП:ФъСф,ЧаЗжЕу:Дг8ЫъЕН40Ыъ,ЫљвдЧаЗжЕуОЭ[8.40]ЁЃЦфЪЕОЭЪЧЭЈЙ§евЕНвЛИіЕуj,ЪЙЕУЕБЧАетДЮЧјЗж,СНБпЖМЛёЕУБШНЯаЁЕФЫ№ЪЇКЏЪ§
? ? ? ? вВОЭЪЧЫЕ,ЮоТлЪЧЗжРрЛЙЪЧЛиЙщЖМЛсЖдЬиеїНјааЖўжЕЛЏЗж,вђДЫПЩвдКмКУЕиЪЪгУгкСЌајБфСПЁЃ
3. ID3КЭC4.5жЛФмгІгУгкЗжРрШЮЮё,CARTЗжРрЛиЙщЖМПЩвд
????????жївЊдвђЪЧЬиеїЗжСбЕФЦРМлБъзМВЛвЛбљ,CARTгаСНжжЦРМлБъзМ:зюаЁЛЏЦНЗНЮѓВюКЭGiniЯЕЪ§ЁЃЖјID3КЭC4.5ЕФЦРМлЛљДЁЖМЪЧаХЯЂьиЁЃ
????????аХЯЂьиКЭGiniЯЕЪ§ЪЧеыЖдЗжРрШЮЮёЕФжИБъ,ЖјзюаЁЛЏЦНЗНЮѓВюЪЧеыЖдСЌајжЕЕФжИБъвђДЫПЩвдгУРДзіЛиЙщ,дЄВтжЕЕШгкИУНкЕуЫљгажЕЕФЦНОљЁЃ
4. C4.5 КЭ CARTЖМдѕУДДІРэШБЪЇжЕЕФ
????????ЛњЦїбЇЯАБЪМЧ(7)ЁЊЁЊC4.5ОіВпЪїжаЕФШБЪЇжЕДІРэ_аЁедЕФВЉПЭ-CSDNВЉПЭ_c4.5ДІРэШБЪЇжЕ
? ? ? ? УЛПДЖЎ,ЯШЗХзХ,КѓЦкРДПДЁЃ
5. ID3 КЭC4.5ПЩвддкУПИіНкЕуЩЯВњЩњГіЖрВцЗжжЇ,ЧвУПИіЬиеїдкВуМЖМфВЛЛсИДгУ,ЖјCARTУПИіНкЕужЛЛсВњЩњГіСНИіЗжжЇ,УПИіЬиеїПЩвдБЛжиИДЪЙгУЁЃ
????????ЬиеїФмЗёМЬајЪЙгУетбљЕФЮЪЬтгІИУзЊЛЏЮЊдкЕБЧАЗжжЇЯТ,ИУЬиеїФмЗёПЩдйДЮЛЎЗжЕФЮЪЬт(ЛђЪЧЪЧЗёЛЙгаПЩРћгУЕФМлжЕ)ВЛФмдйДЮЛЎЗжЕФвтЫМОЭЪЧдкЕБЧАЗжжЇФк,ИУЬиеїжЛгаЮЈвЛЕФжЕЁЃ
????????ШчЙћXiЪЧРыЩЂЬиеї:
????????ID3КЭC4.5дкРыЩЂЬиеїЩЯЖМЪЧЖрВцЪї,ОЭЪЧАДееИУЬиеїЕФШЋВПЬиеїжЕНјааЗжСб,ФЧУДЯдШЛЗжСбКѓЕФШЮвтвЛИіЗжжЇФкЬиеїXiжЛгаЮЈвЛЕФжЕ,ЫљвдИУЬиеїЯћКФЕєСЫЁЃ(ЮвгУID3КЭC4.5ШЅбЁГіЖдаХЯЂьиРДЫЕзюгХЕФЬиеї,ШЛКѓОЭШЋгУСЫ,етРягІИУЩЯвЛИіР§зг)
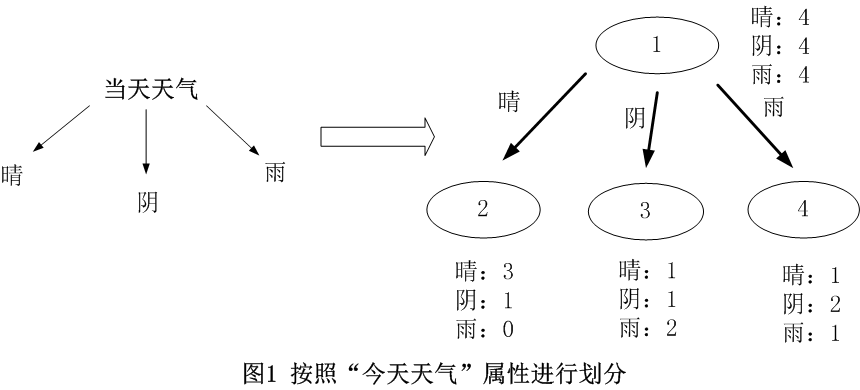 ?
?
????????ШчЙћXiЪЧСЌајЬиеї:
????????ID3УЛЗЈДІРэ,ТдЙ§ЁЃC4.5ЪЧНЋСЌајЬиеїНјааХХађ,АДееЯрСкРыЩЂжЕЕФжаЕуНјааЗжСб,ПЩвдЫЕдкСЌајЬиеїЩЯ,C4.5ЪЧЖўВцЗжСбЕФЁЃШчЙћИУСЌајЬиеїжЛгаСНИіРыЩЂжЕ,ФЧУДвЛДЮЗжСбОЭЛсЯћКФЕєетИіЬиеї;ШчЙћгаЖрИіРыЩЂжЕ,ФЧУДПЩвдОЪмЖрДЮЗжСбЁЃ
????????зюКѓдйЫЕCARTЫуЗЈ:
????????CARTЫуЗЈЪЧЖўВцЪї,вВОЭЪЧЮоТлXiЪЧСЌајЬиеїЛЙЪЧРыЩЂЬиеїЖМЪЧЖўВцЗжСбЕФЁЃФЧУДШчЙћXiгаЖргк2ИіРыЩЂжЕ,МДБуXiЪЧРыЩЂЬиеї,вВПЩвдОЪмЖрДЮЗжСб,вВОЭЪЧФуЫЕЕФФмБЛжиИДРћгУЁЃ
? ? ? ? Гізд:CARTЫуЗЈжаФГвЛЬиеїБЛЪЙгУКѓЛЙФмБЛжиИДЪЙгУТ№? - жЊКѕ
?
6. ID3КЭC4.5 ПЩвдЭЈЙ§МєжІРДКтСПЪїЕФзМШЗТЪКЭЗКЛЏФмСІ,CARTжБНгРћгУШЋВПЪ§ОнЗЂЯжЫљгаПЩФмЕФЪїНсЙЙНјааЖдБШЁЃ
? ? ? ? ОпЬхЕФМєжІПЩвдПДвдЧАЕФЮФеТ,РяУцгаID3,C4.5 вдМА CARTЪї ЖдгІЕФМєжІСїГЬ:
ЁЖЭГМЦбЇЯАЗНЗЈЁЗОіВпЪїМАМєжІ,ЛиЙщЪїЗжРрЪї_Francis_sЕФВЉПЭ-CSDNВЉПЭ