дкИХТЪТлжа,СНЫцЛњБфСПЕФвЛИіСЊКЯЗжВМПЩгЩвЛИіБфСПЕФБпдЕЗжВМКЭЖдгІЬѕМўЗжВМШЗЖЈ,вВПЩЖдГЦЕигЩСэвЛБфСПЕФБпдЕЗжВМКЭСэвЛЗНЯђЕФЬѕМўЗжВМШЗЖЈ,ЕЋЮоЗЈгЩетСНИіБпдЕЗжВМШЗЖЈЁЃвђДЫ,ПЩЗёНігЩетСНИіЬѕМўЗжВМРДШЗЖЈСЊКЯЗжВМ,ГЩЮЊСЫПЦбаШЫдБИааЫШЄЕФбаОПЗНЯђЁЃ
еыЖдЩЯЪіЮЪЬт,ЮЂШэбЧжобаОПдКЕФбаОПдБдк NeurIPS 2021 ЩЯЗЂБэЕФТлЮФИјГіСЫШЋУцЖјзМШЗЕФЛиД№,ВЂЛљгкДЫРэТлЬсГіСЫвЛИіШЋаТЕФЩњГЩЪННЈФЃФЃЪН CyGenЁЃЦфНіашСНИіПЩаЮГЩБеЛЗЕФЬѕМўЗжВМФЃаЭ,ЖјЮоашжИЖЈЯШбщЗжВМ,ДгЖјДгИљБОЩЯНтОіСЫСїаЮДэХфКЭКѓбщЬЎЫѕЮЪЬт,ЪЙЕУЦфдкЪЕбщжаПЩвдЭъУРБэДяЪ§ОнЗжВМ,ВЂФмНЋВЛЭЌЬиадЪ§ОнЕуЕФБэЪОЧјЗжПЊРДЁЃ
ЪьЯЄИХТЪТлЕФЖСепЯыБиВЛЛсЖдЬѕМўИХТЪЙЋЪНИаЕНФАЩњ,МД p(x,z)=p(z)p(xЉІz)=p(x)p(zЉІx)ЁЃЫќвтЮЖзХЖЈвхСНЫцЛњБфСП (x,z) ЕФвЛИіСЊКЯЗжВМ p(x,z) ПЩЭЈЙ§ЖЈвхБпдЕЗжВМ p(z) КЭЬѕМўЗжВМ p(xЉІz) ЭъГЩ,вВПЩЖдГЦЕиЭЈЙ§ЖЈвхСэвЛБпдЕЗжВМ p(x) КЭСэвЛЗНЯђЕФЬѕМўЗжВМ p(zЉІx) ЭъГЩЁЃЕЋЪЧ,гУСНИіБпдЕЗжВМ p(z) КЭ p(x) ШДЮоЗЈЖЈвхСЊКЯЗжВМ,вђЮЊЫќУЧУЛгаЬсЙЉxКЭzЯрЙиадЕФаХЯЂЁЃвђДЫ,гУСНИіЬѕМўЗжВМ p(xЉІz) КЭ p(zЉІx) ФмЗёШЗЖЈ (x,z) ЕФвЛИіСЊКЯЗжВМ,ГЩЮЊСЫбаОПдБУЧЪЎЗжИааЫШЄЕФбаОПЗНЯђЁЃ
ЮЂШэбЧжобаОПдКЕФбаОПдБУЧдк NeurIPS 2021 ЗЂБэЕФТлЮФЁАOn the Generative Utility of Cyclic ConditionalsЁБжа,ДгзюЛљБОЖјЭЈгУЕФВтЖШТлНЧЖШЗжЮіСЫДЫЮЪЬт,ВЂЧвЗЂЯжД№АИПЩвдЪЧПЯЖЈЕФ,ЕЋашвЊвЛЖЈЬѕМўЁЃбаОПдБЬсГіСЫвЛИіШЋаТЕФЩњГЩЪННЈФЃФЃЪН:жЛашНЈФЃСНИіЬѕМўЗжВМ,МДЫЦШЛФЃаЭ(likelihood model,ЛђГЦЩњГЩЦї generator ЛђНтТыЦї decoder)p(xЉІz),КЭЭЦЖЯФЃаЭ(inference model,ЛђГЦБрТыЦї encoder) q(zЉІx),ЖјВЛЯёвбгаФЃЪНЛЙашжИЖЈЛђНЈФЃЯШбщЗжВМ(prior distribution)p(z)ЁЃДЫаТФЃЪНПЩвдГЦжЎЮЊЁАГЩЛЗЪНЩњГЩЪННЈФЃЁБ,МђМЧЮЊ CyGen(Cyclic conditional Generative modeling),дДздЫќНіашЕФФЃПщЁЊЁЊp(xЉІz)КЭq(zЉІx)ЁЊЁЊЕФЗНЯђ(МДДг z ВЩ x КЭДг x ВЩ z)аЮГЩСЫБеЛЗЁЃCyGen БмУтСЫИївбгаЩњГЩФЃаЭвђашвЊЯШбщЖјДјРДЕФСїаЮДэХф(manifold mismatch)КЭКѓбщЬЎЫѕ(posterior collapse)ЮЪЬт,ДгЖјФмвдИќИпОЋЖШФтКЯВЂЩњГЩЪ§Он,ЧвФмГщШЁЕНИќгагУЕФЪ§ОнБэЪОЁЃ

ТлЮФЕижЗ:
https://arxiv.org/pdf/2106.15962
ДњТыЕижЗ:
https://github.com/changliu00/cygen
СНЬѕМўЗжВМФмЗёШЗЖЈСЊКЯЗжВМ?
ДЫЮЪЬтЦфЪЕАќКЌСЫСНИізгЮЪЬт,жЛгаЖМЪЧПЯЖЈЕФД№АИ,дЮЪЬтВХЪЧПЯЖЈЕФД№АИЁЃ
(1)ЯрШнад(compatibility):ЖдгкШЮвтИјЖЈЕФСНЬѕМўЗжВМ p(xЉІz) КЭ q(zЉІx),ЫќУЧЪЧЗёПЩгЩЭЌвЛИіСЊКЯЗжВМЕМГі?ЛЛбджЎ,ЪЧЗёДцдквЛИіСЊКЯЗжВМ Іа(x,z) ЪЙЕУ Іа(xЉІz)=p(xЉІz)ЧвІа(zЉІx)=q(zЉІx)?
(2)ОіЖЈад(determinacy):ЖдгкСНИіЯрШнЕФЬѕМўЗжВМ p(xЉІz) КЭ q(zЉІx),ЫќУЧЪЧЗёФмЮЈвЛОіЖЈвЛИіСЊКЯЗжВМ?ЛЛбджЎ,ФмЙЛЕМГіЖўепЕФСЊКЯЗжВМЪЧЗёЮЈвЛ?
ОјЖдСЌајЧщПі
ЪзЯШПМТЧСНИіЬѕМўЗжВМЖМгаУмЖШКЏЪ§(Radon-Nikodym ЕМЪ§,ЭГвЛУшЪіСЌајКЭРыЩЂБфСП)ЕФЧщПі,ВтЖШТлжаГЦжЎЮЊЁАОјЖдСЌајЁБ(absolutely continuous)[1]ЁЃЫќАќКЌСЫОЕфЕФБфЗжздБрТыЦї(variational auto-encoder,VAE)[2]-[3]МАзюНќаЫЦ№ЕФЛљгкРЉЩЂЙ§ГЬЕФЩњГЩФЃаЭ(diffusion-based generative models)[4]ЈC[6]ЁЃетЪЧИХТЪТлжазюГЃМћЕФЧщПі,гаСЫУмЖШКЏЪ§ОЭПЩвдЫцвтЪЙгУИїжжУмЖШКЏЪ§ЙЋЪНЁЃгЩДЫПЩжЊ,ШчЙћТњзуЯрШнад,ФЧУДОЭДцдкСЊКЯЗжВМ Іа(x,z) ЪЙЕУСНЬѕМўЗжВМЕФБШжЕ (p(xЉІz))/(q(zЉІx))=(Іа(x,z)/Іа(z))/(Іа(x,z)/Іа(x))=Іа(x) 1/Іа(z) ПЩЗжНтЮЊвЛИі x ЕФКЏЪ§ГЫвдвЛИі z ЕФКЏЪ§ЁЃЗДЙ§РД,ШєБШжЕТњзуетбљЕФЗжНт,ОЭПЩвдЙЙдьГіетбљЕФ Іа(x,z),ДгЖјЫЕУїСНЬѕМўЗжВМЯрШнЁЃете§ЪЧвбгаЙЄзї(Шч[7]ЈC[9])ЕФЛљДЁЁЃ
ЕЋЪЧ,вбгаЙЄзїКіТдСЫвЛМўЪТ:ЬѕМўЗжВМ(Шч p(?ЉІz))НідкБпдЕЗжВМ(Шч p(z))ЫљЖЈвхЕФЁАМИКѕДІДІЁБЕФвтвхЯТЪЧЮЈвЛЕФ,ЬиБ№ЪЧ,Шє z_0 дк p(z) ЕФжЇГХМЏ(support)жЎЭт,ФЧ p(?ЉІz_0) ПЩвдЪЧвЛИіШЮвтЕФЗжВМЁЃетвтЮЖзХШЮИјЕФСНЬѕМўЗжВМОЭЫуВЛдкећИіПеМф XЁСZ ЩЯТњзуЩЯЪіПЩЗжНтад,ЕЋШєЫќУЧПЩдквЛИіЧЁЕБЕФзгМЏЩЯТњзу,ШдгаПЩФмЪЧЯрШнЕФ,вђЮЊШєСЊКЯЗжВМвдДЫзгМЏЮЊжЇГХМЏ,ФЧУДСНЬѕМўЗжВМдкДЫзгМЏжЎЭтЕФБэЯжОЭПЩвдЪЧШЮвтЕФЁЃЫљвд,вбгаЙЄзїЕФНсТлЪЧГфЗжЕЋЗЧБивЊЕФЁЃНќРДвВгаЙЄзї[10]ЬсГіСЫГфЗжБивЊЕФЬѕМў,ЕЋЦфУшЪіШдШЛЪЧДцдкадЕФ,вђЖјЮоЗЈжИЕМЪЕМЪВйзїЁЃ
ЫљвдЮЂШэбЧжобаОПдКЕФбаОПдБУЧевГіСЫвЛИіМШГфЗжБивЊгжПЩВйзїЕФЯрШнадХаОн,ДѓвтЪЧИљОнЫљИјЬѕМўУмЖШКЏЪ§евГіЧЁЕБзгМЏВЂдкЦфЩЯХаЖЯПЩЗжНтадЁЃЦфбЯИёа№ЪіЩцМАвЛаЉЪ§бЇЯИНк,ИааЫШЄЕФЖСепПЩдФЖСТлЮФдЮФЁЃ
ЙигкОіЖЈад,баОПдБУЧвВИјГіСЫвЛИіБШвдЭљНсТл(Шч[9])ЁАИќБивЊЁБЕФГфЗжЬѕМўЁЃДѓвтЪЧ:дкУПвЛИіЁАЪЧЗНЕФЁБЕФСНЯрШнЬѕМўЗжВМЫљОіЖЈЕФЁАЧЁЕБзгМЏЁБЩЯ,СЊКЯЗжВМЪЧЮЈвЛЕФЁЃЬиБ№Еи,ШєСНЬѕМўЗжВМЖМгаШЋжЇГХМЏ,ФЧећИіПеМф XЁСZ ЪЧЮЈвЛПЩФмЕФЁАЧЁЕБзгМЏЁБЖјЧввВЁАЪЧЗНЕФЁБ,вђДЫШєСНепЯрШндђЫќУЧМДдкећИіПеМфЩЯЮЈвЛШЗЖЈСЫвЛИіСЊКЯЗжВМЁЃЫљвдОјЖдСЌајЧщПіЯТЕФЬѕМўЗжВМгаКмКУЕФОіЖЈадЁЃ
ЕвРПЫЗжВМЧщПі
СэЭтвЛаЉСїааЕФЩњГЩФЃаЭЕФЫЦШЛФЃаЭ(ЩњГЩЦї)ЪЧвЛИіДгвўБфСП z ЕНЪ§ОнБфСП x ЕФШЗЖЈадгГЩф,МД x=f(z),АќРЈЩњГЩЪНЖдПЙЭјТч(generative adversarial net, GAN)[11]вдМАЛљгкСїЕФЩњГЩФЃаЭ(flow-based generative model)[12], [13]ЁЃЫќЫљЖЈвхЕФЬѕМўЗжВМНЋЫљгаИХТЪжЪСПЖММЏжадкСЫ f(z) етвЛЕуЩЯ,БЛГЦЮЊЕвРПЫЕТЖћЫўЗжВМ(Dirac delta distribution):p(XЉІz)=ІФ_f(z) (X)=I[f(z)ЁЪX],МДШєПЩВтМЏ X АќКЌ f(z) дђЮЊЦфИГВтЖШ1,ЗёдђИГ0ЁЃзЂвтдкСЌајЧщПіЯТетИіЗжВМУЛгаУмЖШКЏЪ§,вђЖјВЛФмЪЙгУУмЖШКЏЪ§ЙЋЪН,ЖјБиаывЊДгВтЖШТлЕФНЧЖШЗжЮіЁЃ
баОПдБУЧЖдЕвРПЫЗжВМЧщПівВИјГіСЫвЛИіМШГфЗжБивЊгжПЩВйзїЕФЯрШнадХаОн,ДѓвтЪЧДцдквЛИі x_0 ЪЙЕУСэвЛЬѕМўЗжВМжЛдкЦфдЯёМЏЩЯЗХжУИХТЪжЪСП:q(f^(-1) ({x_0})|x_0)=1ЁЃПЩФмЗДжБОѕЕФЪЧжЛашвЛИіетбљЕФ x_0 МДПЩТњзуЯрШнад,етЪЧвђЮЊ ІФ_((x_0, f^(-1) ({x_0})))вбОЪЧвЛИіПЩЕМГіСНепЕФСЊКЯЗжВМ,ЖјСНепдкДЫСЊКЯЗжВМЕФжЇГХМЏ (x_0,f^(-1) ({x_0})) жЎЭтЕФБэЯжПЩвдЪЧШЮвтЕФЁЃВЛЙ§,ЕЅЕуЩЯЕФЯрШнадЖдгкЪЕМЪЪЙгУВЂВЛзуЙЛ,вђЖјШЫУЧЯЃЭћЯрШнадФмдквЛИіМЏКЯЩЯГЩСЂЁЃШєСэвЛЬѕМўЗжВМ q(ZЉІx) вВШЁЕвРПЫЗжВМЕФаЮЪН,ФЧзюаЁЛЏЖдХМбЇЯАжаГЃгУЕФЛЗЪНвЛжТадЫ№ЪЇКЏЪ§(cycle-consistency loss)[14]ЈC[18]БуЖдЯрШнадЪЧГфЗжЕФЁЃШчЙћ f ЛЙЪЧПЩФцЕФ,ФЧЫќвВЪЧБивЊЕФ,ЧвЯрШнЕФ q(ZЉІx) ЕФгГЩфКЏЪ§ЪЧ f ЕФФцЁЃетвВЫЕУїСїФЃаЭЬьЩњОЭЪЧЯрШнЕФЁЃ
жСгкОіЖЈад,ИеВХвбЬсЕН,дк (x_0,f^(-1) ({x_0})) ЩЯСНЯрШнЬѕМўЗжВМПЩШЗЖЈЮЈвЛЕФСЊКЯЗжВМ ІФ_((x_0,f^(-1) ({x_0})))ЁЃЕЋШєетбљЕФ x_0 ВЛЮЈвЛ,ФЧетаЉ x_0 ЩЯЕФИХТЪжЪСПЗжХфЪЧЮоЗЈШЗЖЈЕФ,вђЖјЮоЗЈдкећИіПеМф XЁСZ ЩЯЖЈвхСЊКЯЗжВМЁЃетвВгыжБОѕЯрЗћ:ЕвРПЫЗжВМ ІФ_f(z) МАгыЦфЯрШнЕФ q(?|x) жЛФмШЗЖЈ XЁСZ жаЕФвЛЬѕЧњЯп x=f(z),ЕЋВЛФмШЗЖЈДЫЧњЯпЩЯЕФЗжВМЁЃвђЖјЕвРПЫЗжВМЧщПіЯТЕФЬѕМўЗжВМШБЗІОіЖЈадЁЃ
ШЋаТЕФЩњГЩЪННЈФЃФЃЪН:CyGen
ЩњГЩЪННЈФЃШЮЮёЪЧжИЖдЪ§ОнБфСП x ЕФЗжВМ p(x) НјааНЈФЃЁЃЖдгк x ЮЌЖШКмИпЕФЧщПіжБНгНЈФЃДЫЗжВМВЛБуСщЛюЕиБэДяИїЮЌЖШЕФЯрЙиад,вђЖјЕБЧАСїааЕФ(ЩюЖШ)ЩњГЩФЃаЭЖМЛсв§ШывўБфСП z ВЂНЈФЃСЊКЯЗжВМ p(x,z) РДИјГіp(x)=Ёв(p(x,z) dz),гУДЫЛ§ЗжБэДя x ИїЮЌЖШМфИДдгЕФЯрЙиад,ЭЌЪБетИівўБфСП z вВПЩвдзїЮЊЪ§ОнЕФвЛИіНєДе(ЕЭЮЌ)ЕФгагявхЕФБэЪО(representation)ЁЃетаЉФЃаЭЭЈЙ§жИЖЈЯШбщЗжВМ p(z) КЭЫЦШЛФЃаЭ p_ІШ (xЉІz)(ІШ ЮЊВЮЪ§)РДЖЈвхСЊКЯЗжВМ p_ІШ (x,z)=p(z) p_ІШ (xЉІz)ЁЃЭЌЪБ,ЮЊЬсШЁЪ§ОнБэЪО,ЫќУЧвВЛсв§ШыЭЦЖЯФЃаЭ q_? (zЉІx)(? ЮЊВЮЪ§)гУРДНќЫЦСЊКЯЗжВМЫљЖЈвхЕФКѓбщЗжВМ p_ІШ (zЉІx)ЁЃБфЗжздБрТыЦї(variational auto-encoder,VAE)[2], [3]ЁЂЫЋЯђЩњГЩЪНЖдПЙЭјТч(bi-directional generative adversarial net,BiGAN)[19], [20],ЛљгкСїЕФЩњГЩФЃаЭ(flow-based generative model)[12], [13]вдМАЛљгкРЉЩЂЙ§ГЬЕФЩњГЩФЃаЭ(diffusion-based generative model)[4]ЈC[6]ЖМЪєгкетжжНЈФЃФЃЪНЁЃ
ШЛЖј,ЪЙгУ p(z) КЭ p_ІШ (xЉІz) ЖЈвхСЊКЯЗжВМЛсДјРДвЛаЉЮЪЬтЁЃЖдгквЛАуШЮЮё(ШчЭМЯёЗжВМЕФНЈФЃ)ШЫУЧВЂВЛжЊЕРЪВУДбљЕФЯШбщЗжВМзюКЯЪЪ,вђЖјДѓЖрбЁгУБъзМИпЫЙЗжВМЁЃЕЋЫќЕФжЇГХМЏЪЧЕЅСЌЭЈЕФЧвЫЦШЛФЃаЭЭЈГЃЪЧСЌајЕФ(МДБЃЭиЦЫЕФ),етвтЮЖзХФЃаЭжЛФмБэДяжЇГХМЏвВЪЧЕЅСЌЭЈЕФЪ§ОнЗжВМ,ЖјШєецЪЕЪ§ОнЗжВМгаЖрСЊЭЈЗжСП,Р§ШчЭМ1зѓЩЯНЧЫљЪОЕФЪ§ОнЗжВМ,етбљЕФФЃаЭБуЮоЗЈКмКУЕиНЈФЃЪ§ОнЗжВМЁЃР§Шч VAE ЩњГЩЕФЪ§ОнЗжВМЪЧФЃК§ЕФ,Жј BiGAN ЩњГЩЕФЮхАъЪ§ОнЖбвВШдШЛЪЧСЌдквЛЦ№ЕФЁЃетГЦЮЊСїаЮДэХф(manifold mismatch)ЮЪЬтЁЃСэвЛЗНУц,ИпЫЙЯШбщвВЛсШУЭЦЖЯФЃаЭ q_? (zЉІx) ЖМЯђдЕуМЏжа,НЋОпгаВЛЭЌЬиадЕФЪ§ОнЕуЕФБэЪОЛьдквЛЦ№,ЪЙЕУетаЉБэЪОВЛФмГфЗжЬхЯжИїЪ§ОнЕу x ЕФЬиад,вђЖјВЛЙЛгагУЁЃЭМ1ЕкЖўааеЙЪОСЫ VAE КЭ BiGAN ЕУЕНЕФЪ§ОнБэЪОЛсНЋВЛЭЌРрБ№Ъ§ОнЕФБэЪОМЗдквЛЦ№ЩѕжСжиЕўЁЃетГЦЮЊКѓбщЬЎЫѕ(posterior collapse)ЮЪЬтЁЃвВгаЗНЗЈЪдЭМЪЙгУШЫРрзЈМвЩшМЦЕФЯШбщЗжВМЛђепИќМгИДдгЕФЯШбщФЃаЭРДНтОіетаЉЮЪЬт,ЕЋетаЉЗНЗЈвЊУДжЛЪЪгУгкИіБ№ОпЬхШЮЮё,вЊУДв§ШыСЫЖюЭтЕФНЈФЃЁЂбЕСЗКЭЪЙгУЕФДњМлЁЃ

ЭМ1:КЯГЩЪ§ОнМЏ(зѓЩЯНЧЭМ)ЩЯИїРрЩњГЩФЃаЭЖдгкЪ§ОнЗжВМНЈФЃ(ЕквЛаа)КЭЬсШЁЪ§ОнБэЪО(ЕкЖўаа)ЕФБэЯжЁЃ
ДгИљБОЩЯНтОіЮЪЬтЕФЭООЖЪЧНтГ§ЩњГЩЪННЈФЃжаашвЊжИЖЈЯШбщЗжВМЕФетИівЊЧѓЁЃетОЭв§ГіСЫвЛПЊЪМЕФЮЪЬт:ФмЗёНігУСНИіЬѕМўЗжВМФЃаЭЖЈвхСЊКЯЗжВМНјЖјЪЕЯжЩњГЩЪННЈФЃЁЃбаОПдБУЧЪзЯШЗЂЯж,МђЕЅДжБЉЕиШЅЕєЯШбщЗжВМЪЧВЛааЕФЁЃШчЭМ1ЫљЪО,ЪЙгУШЅдыздБрТыЦї(denoising auto-encoder,DAE)[21]ЈC[23](ЫќВЂЗЧзїЮЊЩњГЩФЃаЭЬсГі,ЕЋвВжЛашСНИіЬѕМўЗжВМФЃаЭ)ЮоЗЈЕУЕНКЯРэЕФНсЙћЁЃ
ЮЊДЫ,баОПдБУЧЬсГіСЫ**ЁАГЩЛЗЪНЩњГЩЪННЈФЃЁБCyGen**(Cyclic conditional Generative modeling)етвЛЩњГЩЪННЈФЃЕФШЋаТФЃЪНЁЃЫќНіашСНИіПЩаЮГЩБеЛЗЕФЬѕМўЗжВМФЃаЭ p_ІШ (xЉІz) КЭ q_? (zЉІx) ЖјЮоашжИЖЈЯШбщЗжВМ,ВЂЧвЗНЗЈдДздЩЯУцЫљНЈСЂЕФбЯИёРэТлЗжЮі,БЃжЄСЫЯрШнадКЭОіЖЈад,вђЖјЪЧвЛИіКЯЗЈЕФЩњГЩЪНФЃаЭЁЃашвЊВћУїЕФЪЧ,СНЬѕМўЗжВМФЃаЭТњзуЯрШнадКЭОіЖЈадОЭЮЈвЛШЗЖЈСЫСЊКЯЗжВМ,вђДЫвВвўЪНЕиЖЈвхСЫвЛИіЯШбщЗжВМ,жЛЪЧ CyGen ЮоашЬивтЮЊЫќНЈСЂФЃаЭЯдЪНБэДяЁЃгЩгкЮоашжИЖЈЯШбщЗжВМ,CyGen ДгИљБОЩЯНтОіСЫСїаЮДэХфКЭКѓбщЬЎЫѕЮЪЬт,ЭМ1ЕФНсЙћБэУїЫќШЗЪЕФмЭъУРБэДяЪ§ОнЗжВМ,ВЂФмНЋВЛЭЌЬиадЪ§ОнЕуЕФБэЪОИјЧјЗжПЊРДЁЃ
ТњзуЯрШнадКЭОіЖЈад
ЮЊЙЙГЩКЯЗЈЕФЩњГЩФЃаЭ,СНЬѕМўЗжВМФЃаЭБиаыФмЖЈвхвЛИіСЊКЯЗжВМ,ЫљвдЫќУЧБиаыТњзуЯрШнадКЭОіЖЈадЁЃЖдгкОіЖЈад,ДгЩЯУцЕФРэТлЗжЮіПЩвдЕУжЊ,ЕвРПЫаЮЪНЕФЬѕМўФЃаЭ,Р§Шч GAN МАЛљгкСїЕФЩњГЩФЃаЭжаШЗЖЈадЕФЫЦШЛФЃаЭ(ЩњГЩЦї),ЮоЗЈИјГіОіЖЈадЁЃвђЖјЪЙгУОјЖдСЌајаЮЪНЕФЬѕМўФЃаЭ,Р§Шч VAE жаИХТЪадЕФЫЦШЛФЃаЭКЭЭЦЖЯФЃаЭ,ЦфСМКУЕФОіЖЈадвВЪЧРэТлЗжЮіЕФНсТлЁЃ
баОПдБУЧЪЙгУОјЖдСЌајЧщПіЯТЕФЯрШнадХаОнРДЪЕЯжЯрШнадЁЃгЩгквЛАуЕФИХТЪадЬѕМўЗжВМФЃаЭНсЙЙЖМгаШЋжЇГХМЏ,вђДЫХаОнжаЕФЁАЧЁЕБзгМЏЁБжЛПЩФмЪЧећИіПеМф XЁСZ,ЫљвдТњзуЯрШнаджЛашТњзуСНЬѕМўЗжВМУмЖШКЏЪ§ЕФБШЕФПЩЗжНтадЬѕМўЁЃЮЊДЫ,ашвЊв§ШыШчЯТЯрШнадЫ№ЪЇКЏЪ§(compatibility loss):
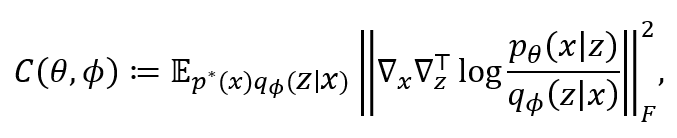
Цфжа p^*(x) ЮЊецЪЕЪ§ОнЗжВМЁЃжБОѕЩЯЫЕ,ШєЬѕМўУмЖШБШПЩЗжНт,ФЧЦфЖдЪ§ОЭЪЧвЛИі x ЕФКЏЪ§МгЩЯвЛИі z ЕФКЏЪ§,вђЖјдкЖдzЕФШЮвЛЗжСПгжЖд x ЕФШЮвЛЗжСПЧѓЭъЕМЪ§КѓЕУСуЁЃетвВПЩвдЫЕУїЗДЙ§РДвВГЩСЂЁЃРэТлЗжЮіжаЬсЕНЙ§ЛЗЪНвЛжТадЫ№ЪЇКЏЪ§ПЩЪЕЯжЕвРПЫЗжВМЧщПіЯТЕФЯрШнад,ЕЋШДЮоЗЈгУгкОјЖдСЌајЕФЧщПі,ЙЪДЫЫ№ЪЇКЏЪ§ПЩЪгЮЊЫќЕФЭЦЙуЁЃЫќИќНвЪОСЫБъзМ VAE ЕФУиУм:ШєСНЬѕМўЗжВМЖМбЁЮЊИпЫЙЗжВМ,ФЧЕБЖўепЯрШнЁЂМДЯрШнадЫ№ЪЇКЏЪ§ЮЊСуЪБ,СНепЕФОљжЕКЏЪ§ЖМЪЧЗТЩф(ЯпадКЏЪ§МгГЃЪ§)ЕФЁЃетНтЪЭСЫБъзМVAEЕФвўПеМфЗЧГЃЯпадетвЛвбгаЙлВь[24]ЁЃЭЌЪБвВПЩЕУжЊ,ШєЯЃЭћбЇЕНЗЧЯпадБэЪО,жБНгЪЙгУЩюЖШЩёОЭјТчЪЧВЛЙЛЕФЁЃвђДЫбаОПдБУЧНЋЦфжавЛИіЬѕМўЗжВМФЃаЭШЁЮЊБШИпЫЙЗжВМИќМгСщЛюЕФЗжВМ,Р§ШчЛљгкСїЕФИХТЪФЃаЭ(Шч[25])ЁЃ
ЪЙгУетИіЫ№ЪЇКЏЪ§ЛЙУцСйвЛИіЙиМќЮЪЬт:жБНгЖдЫќЙРМЦашвЊ O(d_X d_Z) ДЮЧѓЕМВйзї(d_X КЭ d_Z ЗжБ№ЮЊБфСП x КЭ z ЕФЮЌЖШ)ЁЃЖдгкГЃМћШЮЮёШчЭМЦЌЩњГЩ,СНИіЮЌЖШЖММЋИп,етИіМЦЫуДњМлЪЧВЛПЩНгЪмЕФЁЃЮЊДЫ,баОПдБУЧПЊЗЂСЫДЫЫ№ЪЇКЏЪ§ЕФвЛИіЫцЛњЕЋЮоЦЋЧвИДдгЖШНіЮЊ O(d_X+d_Z) ЕФЙРМЦЦїЁЃЯъЯИаХЯЂПЩдФЖСТлЮФдЮФЁЃ
ФтКЯгыЩњГЩЪ§Он
зїЮЊвЛИіЩњГЩФЃаЭ,СНЬѕМўЗжВМФЃаЭЛЙБиаыЬсЙЉЯргІЕФЗўЮё,МДФтКЯгыЩњГЩЪ§ОнЁЃЕБСНИіЬѕМўЗжВМФЃаЭТњзуЯрШнадКЭОіЖЈадЪБ,дђПЩгУЫќУЧаДГіЪ§ОнБфСП x ЕФБпдЕЗжВМ p_(ІШ,?) (x),НјЖјПЩНјаазюДѓЫЦШЛЙРМЦ(maximum likelihood estimate):
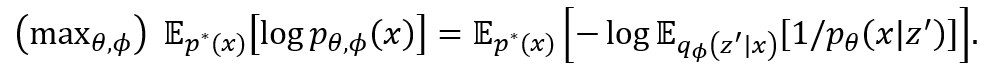
ЕШЪНгвБпЕкЖўИіЦкЭћПЩгУ VAE жаГЃВЩгУЕФ q_? (z|x) жиВЮЪ§ЛЏММЪѕ(reparameterization trick)гУУЩЬиПЈТо(Monte Carlo)ЗНЗЈЙРМЦ[2],ЖјЙРМЦЦфЖдЪ§дђПЩЪЙгУ logsumexp ММЪѕБЃжЄЪ§жЕЮШЖЈЁЃЯрБШжЎЯТ,ЧАЮФЬсЕНЕФ DAE ЕФФПБъКЏЪ§ E_(p^* (x) q_? (z^ЁЎЉІx)) [log? p_ІШ (xЉІz^ЁЏ)]ШДЪЧЫќЕФЩЯНч(зЂвтетРяашвЊзюДѓЛЏ),вђЖјЮоЗЈБЃжЄФтКЯаЇЙћЁЃЬиБ№ЪЧ,ЫќЛсШУ q_? (zЉІx) БфЮЊМЏжадк p(x|z) Жд z ЕФзюДѓжЕНтЩЯЕФЕвРПЫЗжВМ(МДФЃЪНЬЎЫѕ,mode-collapse),ЫљвдЦЦЛЕСЫОіЖЈадЁЃетНтЪЭСЫЫќдкЭМ1жаЕФЪЇАмЁЃCyGen зюжеЕФгХЛЏФПБъЪЧДЫзюДѓЫЦШЛФПБъгыЩЯЪіЯрШнадФПБъжЎКЭЁЃ
жСгкЩњГЩЪ§Он,гЩгкСНЬѕМўЗжВМУЛгаЖЈвхвЛИіДгЭЗЕНЮВЕФЩњГЩЙ§ГЬ,зцЯШВЩбљ(ancestral sampling)ЮоЗЈЪЙгУ,ЕЋШдШЛПЩгУТэЖћПЩЗђСДУЩЬиПЈТо(Markov chain Monte Carlo,MCMC)ЗНЗЈВЩбљЁЃЫќУЧжЛашФПБъЗжВМЕФЮДЙщвЛЛЏУмЖШКЏЪ§,Жј CyGen е§КУПЩвдЬсЙЉ:p_(ІШ,?) (x)Ёи(p_ІШ (x|z))/(q_? (z|x))ЁЃбаОПдБУЧбЁШЁСЫЛљгкЖЏСІбЇЯЕЭГЕФ MCMC ЗНЗЈ,Р§ШчЫцЛњЬнЖШРЪжЎЭђЖЏСІбЇЯЕЭГЗНЗЈ(stochastic gradient Langevin dynamics,SGLD)[26],ЯъЯИаХЯЂПЩдФЖСТлЮФдЮФЁЃ
ЪЕбщНсЙћ
Г§СЫЭМ1жаКЯГЩЪ§ОнМЏЩЯЕФЪЕбщНсЙћ,баОПдБУЧвВдкецЪЕЭМЦЌЪ§ОнМЏ MNIST КЭ SVHN ЩЯзіСЫЪЕбщЁЃЮЊЙЋЦНБШНЯ,ЫљгаЗНЗЈЖМгУСЫЭЌбљЕФЬѕМўЗжВМФЃаЭНсЙЙЁЃгЩгкЪЧИХТЪадЕФ(ЮЊТњзу CyGen ЕФОіЖЈад),BiGAN ЕФбЕСЗЙ§ГЬЪЎЗжВЛЮШЖЈ,ЮДФмВњЩњКЯРэЕФНсЙћ,ЫљвдУЛгаеЙЪОЁЃЭМ2жаЕФНсЙћБэУї,CyGen ЕФЩњГЩаЇЙћЪЎЗжЧхЮњЖјЖрбљ,ЧвгУЫќЬсШЁЕФЪ§ОнБэЪОЫљбЕСЗЕФЗжРрЦїШЁЕУСЫзюИпЕФзМШЗТЪЁЃетЗжБ№ЬхЯжСЫ CyGen БмУтСїаЮДэХфМАКѓбщЬЎЫѕЕФКУДІЁЃЯрБШжЎЯТ,DAE гЩгкУЛгаОіЖЈад,ЩњГЩжЪСПВЛКУ,Ыљвд VAE ЕФзМШЗТЪЪЧзюЕЭЕФ,БэУїЫќгаУїЯдЕФКѓбщЬЎЫѕЮЪЬтЁЃТлЮФвВИјГіСЫИќЖрЪЕбщЗжЮі,БэУїв§ШыЯрШнадЫ№ЪЇКЏЪ§ЪЧБивЊЕФ,ЪЙгУ SGLD ЩњГЩЪ§ОнЕФаЇЙћКУгкЪЙгУМЊВМЫЙВЩбљ,ВЂЧвОЁЙмЩсЦњСЫЯШбщЗжВМ,ШЫРржЊЪЖШдПЩЭЈЙ§ЬѕМўЗжВМФЃаЭНјШыЕНЩњГЩЪННЈФЃжаЁЃ

ЭМ2:ецЪЕЭМЦЌЪ§ОнМЏMNISTКЭSVHNЩЯИїРрЩњГЩФЃаЭЕФЩњГЩаЇЙћвдМАгУЫќУЧЬсШЁЕФЪ§ОнБэЪОЫљбЕСЗЕФЗжРрЦїЕФАйЗжзМШЗТЪ(ИїЭМгвЯТНЧ)ЁЃ
НсгягыеЙЭћ
БОЙЄзїЮЊЁАСНЬѕМўЗжВМЪЧЗёПЩШЗЖЈСЊКЯЗжВМЁБетИіЮЪЬтНЈСЂСЫвЛИіЭГвЛЕФРэТлПђМм,АќРЈСЊКЯЗжВМЕФДцдкадКЭЮЈвЛадЁЊЁЊМДСНЬѕМўЗжВМЕФЯрШнадКЭОіЖЈадЁЊЁЊЕФГфЗжБивЊХаОнЛђГфЗжЬѕМў,ВЂЛљгкДЫРэТлЬсГіСЫвЛИіНіашСНЬѕМўЗжВМФЃаЭЖјЮоашжИЖЈЯШбщЗжВМЕФЩњГЩЪННЈФЃШЋаТФЃЪН CyGen,АќРЈЪЕЯжЯрШнадКЭОіЖЈадвдМАФтКЯКЭЩњГЩЪ§ОнЕФЫуЗЈЁЃЪЕбщеЙЪОСЫ CyGen вђНтГ§ЖджИЖЈЯШбщЗжВМЕФашЧѓЖјДјРДЕФИќКУЕФЩњГЩаЇЙћМАИќгагУЕФЪ§ОнБэЪОЕШгХЪЦЁЃ
CyGen етжжЩњГЩЪННЈФЃФЃЪНЛсЮЊКмЖргІгУСьгђДјРДБуРћ,вђЮЊдкДѓВПЗжГЁОАжаКмФбжЊЕРвЛИіЯШбщЗжВМ,ЕЋШДЖдЬѕМўЗжВМгавЛЖЈЕФжЊЪЖ,Р§ШчЭМЦЌЬиеїЖдЭМЦЌЦНвЦа§зЊЫѕЗХЕФВЛБфадЁЃСэвЛЗНУц,БОЮФжаЫљНЈСЂЕФЛљДЁРэТлвВФмЖдЛњЦїбЇЯАЦфЫћСьгђ(Р§ШчЖдХМбЇЯАКЭздМрЖНбЇЯА)ДјРДаТЕФШЯЪЖ,НјЖјЦєЗЂаТЕФЗжЮіКЭЫуЗЈЁЃ
ВЮПМЮФЯз
[1] P. Billingsley, Probability and Measure. New Jersey: John Wiley & Sons, 2012.
[2] D. P. Kingma and M. Welling, ЁАAuto-encoding variational Bayes,ЁБ in Proceedings of the International Conference on Learning Representations, 2014.
[3] D. J. Rezende, S. Mohamed, and D. Wierstra, ЁАStochastic Backpropagation and Approximate Inference in Deep Generative Models,ЁБ in International Conference on Machine Learning, 2014, pp. 1278ЈC1286.
[4] J. Sohl-Dickstein, E. A. Weiss, N. Maheswaranathan, and S. Ganguli, ЁАDeep Unsupervised Learning using Nonequilibrium Thermodynamics,ЁБ in International Conference on Machine Learning, 2015.
[5] J. Ho, A. Jain, and P. Abbeel, ЁАDenoising diffusion probabilistic models,ЁБ in Advances in Neural Information Processing Systems, 2020, vol. 256.
[6] Y. Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole, ЁАScore-Based Generative Modeling through Stochastic Differential Equations,ЁБ in Proceedings of the International Conference on Learning Representations, 2021, pp. 1ЈC32.
[7] B. C. Arnold and S. J. Press, ЁАCompatible conditional distributions,ЁБ J. Am. Stat. Assoc., vol. 84, no. 405, pp. 152ЈC156, 1989.
[8] B. C. Arnold, E. Castillo, and J. MarЈЊa Sarabia, ЁАConditionally specified distributions: An introduction,ЁБ Stat. Sci., vol. 16, no. 3, pp. 249ЈC265, 2001.
[9] B. C. Arnold, E. Castillo, and J.-M. Sarabia, Conditionally Specified Distributions. 1992.
[10] P. Berti, E. Dreassi, and P. Rigo, ЁАCompatibility results for conditional distributions,ЁБ J. Multivar. Anal., vol. 125, pp. 190ЈC203, 2014.
[11] I. J. Goodfellow et al., ЁАGenerative Adversarial Nets,ЁБ in Advances in Neural Information Processing Systems, pp. 1ЈC9, 2014.
[12] L. Dinh, D. Krueger, and Y. Bengio, ЁАNICE: Non-linear Independent Components Estimation,ЁБ in workshop on the International Conference on Learning Representations, 2015.
[13] D. P. Kingma and P. Dhariwal, ЁАGlow: Generative Flow with Invertible 1x1 Convolutions,ЁБ in Advances in Neural Information Processing Systems, 2018.
[14] T. Kim, M. Cha, H. Kim, J. K. Lee, and J. Kim, ЁАLearning to Discover Cross-Domain Relations with Generative Adversarial Networks,ЁБ in International Conference on Machine Learning, 2017.
[15] J.-Y. Zhu, T. Park, P. Isola, and A. A. Efros, ЁАUnpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks,ЁБ in IEEE International Conference on Computer Vision (ICCV), 2017.
[16] Z. Yi, H. Zhang, P. Tan, and M. Gong, ЁАDualGAN: Unsupervised Dual Learning for Image-to-Image Translation,ЁБ in IEEE International Conference on Computer Vision (ICCV), 2017.
[17] Y. Xia, T. Qin, W. Chen, J. Bian, N. Yu, and T.-Y. Liu, ЁАDual Supervised Learning,ЁБ in International Conference on Machine Learning, 2017, no. 1.
[18] Y. Xia et al., ЁАDual Learning for Machine Translation,ЁБ in Advances in Neural Information Processing Systems, 2016.
[19] J. Donahue, P. Kr?henbЈЙhl, and T. Darrell, ЁАAdversarial Feature Learning,ЁБ in Proceedings of the International Conference on Learning Representations, 2017.
[20] V. Dumoulin et al., ЁАAdversarially Learned Inference,ЁБ in Proceedings of the International Conference on Learning Representations, 2017.
[21] P. Vincent, H. Larochelle, Y. Bengio, and P.-A. Manzagol, ЁАExtracting and Composing Robust Features with Denoising Autoencoders,ЁБ in International Conference on Machine Learning, 2008, vol. 311, pp. 1ЈC10.
[22] Y. Bengio, L. Yao, G. Alain, and P. Vincent, ЁАGeneralized denoising auto-encoders as generative models,ЁБ in Advances in Neural Information Processing Systems, 2013, pp. 1ЈC9.
[23] Y. Bengio, ЈІ. Thibodeau-Laufer, G. Alain, and J. Yosinski, ЁАDeep generative stochastic networks trainable by backprop,ЁБ in International Conference on Machine Learning, 2014, vol. 2, pp. 1470ЈC1485.
[24] H. Shao, A. Kumar, and P. Thomas Fletcher, ЁАThe Riemannian geometry of deep generative models,ЁБ in IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, 2018.
[25] R. Van Den Berg, L. Hasenclever, J. M. Tomczak, and M. Welling, ЁАSylvester normalizing flows for variational inference,ЁБ in 34th Conference on Uncertainty in Artificial Intelligence, 2018, vol. 1, pp. 393ЈC402.
[26] M. Welling and Y. W. Teh, ЁАBayesian Learning via Stochastic Gradient Langevin Dynamics,ЁБ in International Conference on Machine Learning, 2011.