[TOC](Tensorflow + Keras + Kaggle)
����
��ʵ��,��Ҳ�ǸոսӴ�Python Deep Learning and Neural Networks,��Ϊһ��Rookie,�Ҿ������б�Ҫ���Լ����������̺��ĵ�����������ķ�ʽ��¼����������ν���ǹ�ѧȻ��֪����,��Ȼ��֪����֪����Ȼ�����Է�Ҳ,֪��Ȼ������ǿҲ����Ի:����ѧ���Ҳ����
���˻�����װ������Ϊ:Windows10 + conda 4.10.3(�����������) + GPU + �ȸ�ر����(��ͷ)
��Ҫ��Jupyter Notebook ����ɴ����ʵ��
��Ϊ����ˮƽ��ԭ��,��������ȫ�˽�ÿһ�д���ĺ��������,��������̳���Ϊ��Щ����������ѧϰ,��Ҫ��ͨ���̵�Rookie���ġ�����д�ţ������������ָ������,���¸м�������
���������̵�ʱ�������ĺܶ��Bug(�ܶ�),�����Ͻ����,Ҳ������û�н���ġ� ��������һ����Ƶ������.,��Ȼ����,���Ǵ��뻹���õ������װġ����Ҫ��������Ļ�,���Կ������Ƶ�ҵ�������ԭ��
Tensorflow�Ļ�����װ(�������)
��Ϊ�ٷ��Ƽ�ʹ��Tensorflow2.0 �������¶�����Tensor flow2.0�Ľ̳�
��ϵͳ�ϰ�װ Python ��������(�����̲����ص�,�Ҹ�����Ӧ�Ĵ�������ս��)
pip3 --version

��ͼ������������Python�����ı�־,�������������ͼ������,��ô��ϲ���Ѿ�����˵�һ����
���������ǰ
pip install virtualenv --upgrade
conda create -n PC_2 python=3.7 anaconda
���û�б���,��ô�������֮�����ζ�Ŵ�����һ����ΪPC_2�������,�����python�汾�����Լ����������Ҫ����ѡ��
��Ϊ���ε�����ΪTensor flow ��������Ҳ������ԵĴ���һ����ΪTensorflow�������,��Ϊ����ⷽ��Ļ��������������,��ô�ҵ���������֮��,ֱ�ӱ���ɾ���Ϳ����Ƶ�����,���ص��İ�ϵͳ�ļ�ɾ����
conda create -n tensorflowenv python=3.7 anaconda
����cmd��ָʾ��,�Ϳ��Գɹ�������һ����Ϊ tensorflowenv �������,�����ַ�ʽ�����ĺô���,����Anaconda���Ժܺõ�����,������ֻ��һ���������ļ��л���
- ����
- �����ڿ�ʼ�˵��е�Anacondaһ���лᷢ�������´����������
- ������Anaconda���û�������ֱ�ӵ���л�
- ��װTenwsorflow��Keras
pip install tensorflow # ��װtensorflow
pip install keras #��װKeras
activate tensorflowenv #��base�����������
deactivate #�ر������
import tensorflow as tf
print(tf.__version__)
import keras
print(keras.__version__) #����Tensorflow �� Keras�Ĵ���
- ������Ѿ�������������ô�ʹ�������Ҫ��ʼ���ǵ���ͷϷ��
����jupyter notebook �� ��Kaggle���������ݼ�(��Ҫ������������������)

- Ȼ���Ҽ����ļ����д�
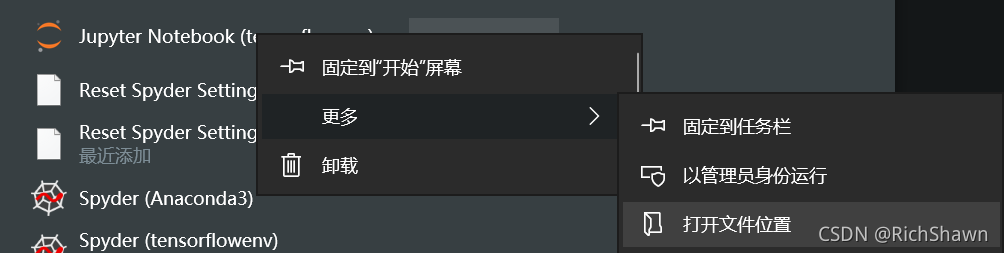
- �� ����
�����������Ǹ�·����Ϊ�Լ�����ļ���·������(�����ҵ���E:\ForKeras)
����: Kaggle.(�����վ�д��������ݼ�,���������ÿһ�����ݼ�,�Ͼ�������)
���ε�ʹ�õ����ݼ�����: Dogs&Cats.
�����������������,��ô�Ұ���ε��ļ��ϴ��ڰٶ�����
����:https://pan.baidu.com/s/1fGw3siDZDIVOAGH0Mt76mw
��ȡ��:6dyj
�������غ��ļ�֮��,������������ӵ�����

����test_set�����ǵIJ��Լ�,training_set�����ǵ�ѵ������
��ʼ��ѵ�����ݼ�
import os ##ʹ��os
base_dir = 'E:\ForKeras\Blog' #�Լ������ݼ���ŵ�λ��
train_dir = os.path.join(base_dir,'training_set', 'training_set')
validation_dir = os.path.join(base_dir,'test_set', 'test_set') ##������ݼ��������ļ��� һ��Ҫע��
train_cats_dir = os.path.join(train_dir, 'cats') ## �������� ����Ϊcats & dogs
train_dogs_dir = os.path.join(train_dir, 'dogs')
test_cats_dir = os.path.join(validation_dir, 'cats') ## �������� ����Ϊcats & dogs
test_dogs_dir = os.path.join(validation_dir, 'dogs')
train_cat_fnames = os.listdir( train_cats_dir )
train_dog_fnames = os.listdir( train_dogs_dir )
print(train_cat_fnames[:20])
print(train_dog_fnames[:20]) #����ѵ��������ɹ�û��
�������ɹ������ʾ��ͬ������ݼ����ݵ��ļ�����

print('total training cat images :', len(os.listdir(train_cats_dir)))
print('total training dog images :', len(os.listdir(train_dogs_dir)))#�鿴ѵ������ͼ��ĸ���
print('total test cat images :', len(os.listdir(test_cats_dir)))
print('total test dog images :', len(os.listdir(test_dogs_dir)))#�鿴��֤����ͼ��ĸ���
������ʾ����

%matplotlib inline
import matplotlib.image as mpimg
import matplotlib.pyplot as plt
nrows = 4
ncols = 4
pic_index = 0
fig = plt.gcf()
fig.set_size_inches(ncols*4, nrows*4)
pic_index+=8
next_cat_pix = [os.path.join(train_cats_dir, fname)
for fname in train_cat_fnames[ pic_index-8:pic_index]
]
next_dog_pix = [os.path.join(train_dogs_dir, fname)
for fname in train_dog_fnames[ pic_index-8:pic_index]
]
for i, img_path in enumerate(next_cat_pix+next_dog_pix):
sp = plt.subplot(nrows, ncols, i + 1)
sp.axis('Off')
img = mpimg.imread(img_path)
plt.imshow(img)
plt.show() ##�鿴�������ݼ��еIJ�����Ƭ

���Ͼ��������ݼ���ȫ����,�����Ѿ���ȫ����˵ػ�,����ʼ ����������CNN ������
����������CNN����
** ���ٿ�����ģ��:�����������,������Ҫ��������ٵ���֤��ѧϰ,���ϵĵ�����ȥ,���Կ�����ģ��ͨ����Ҫ����,ģ����������,Ч��������²��һЩ����,����̫����ϸ�ڡ��ں��ڵĹ����ж������ģ�ͽ��и�����Ż����ﵽ�������Ч�� **
�����ǿ��� ά���ٿ� ����ô������������:
** �����ѧϰ��,����������(CNN��ConvNet)��һ�����������,����ڷ����Ӿ�ͼ��
CNNʹ�ö���֪���ı������,��Ҫ���ٵ�Ԥ����������Ҳ����Ϊ��λ�����ռ䲻���˹�������(SIANN),�������ǵĹ���Ȩ�ؼܹ���ƽ�Ʋ������������������类���������﹤����֮�������ͼ������Ԫ�����ڶ������֯�Ӿ�Ƥ�㡣����Ƥ����Ԫ���ڱ���Ϊ����Ұ����Ұ�����������жԴ̼�������Ӧ����ͬ��Ԫ�ĸ���Ұ�����ص�,ʹ�����Ǹ���������Ұ��
������ͼ������㷨���,CNNʹ����Խ��ٵ�Ԥ����������ζ������ѧϰ��ͳ�㷨���ֹ���ƵĹ���������������������е���ǰ֪ʶ�������Ķ�������һ����Ҫ�ŵ㡣
���ǿ�����ͼ�����Ƶʶ��,�Ƽ�ϵͳ,ͼ�����,ҽѧͼ���������Ȼ���Դ���**
import tensorflow as tf
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(16, (3,3), activation='relu', input_shape=(150, 150, 3)),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(32, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
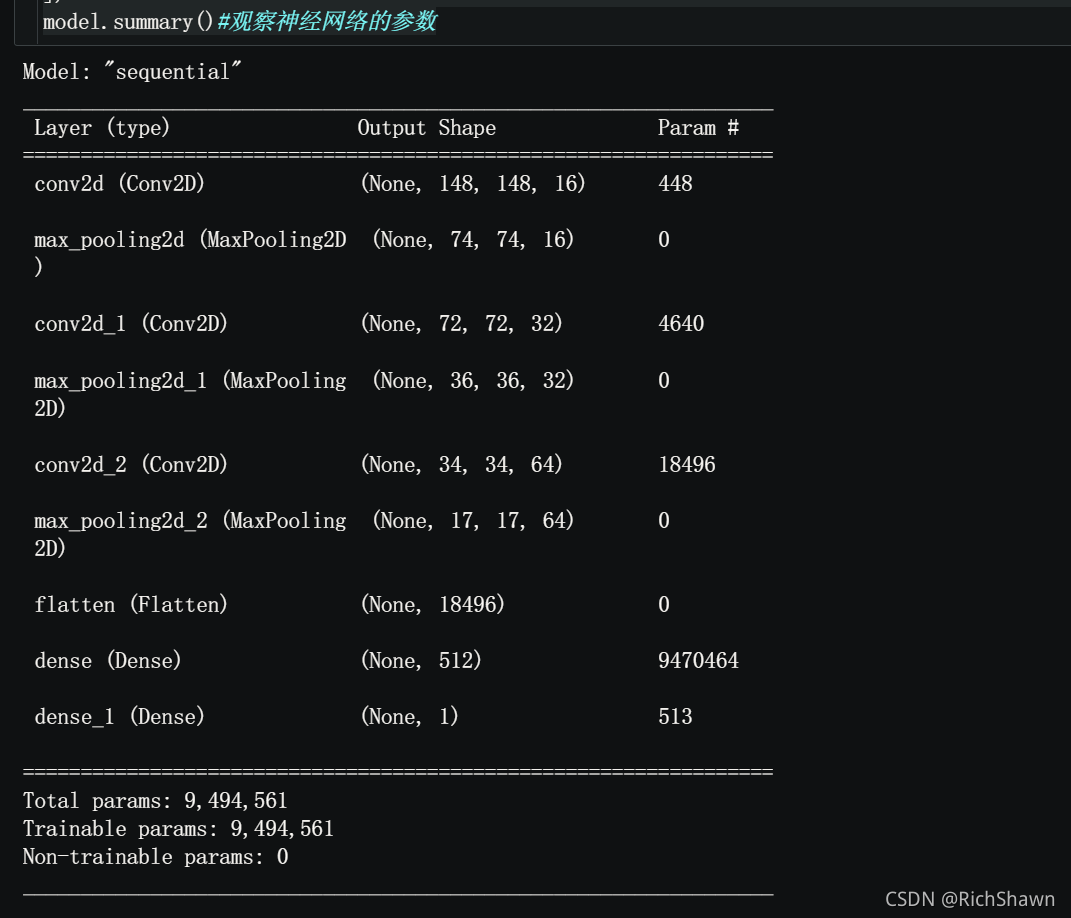
model.summary()#�۲�Neural Networks
�IJ���
��ͼ����������ȡ�ļ�������
from tensorflow.keras.optimizers import RMSprop
from tensorflow.keras.preprocessing.image import ImageDataGenerator
model.compile(optimizer=RMSprop(learning_rate=0.001), #model.compile() �Ż���(loss:������ʧ,�����õ��ǽ�������ʧ,metrics: �б�,��������ģ����ѵ���Ͳ���ʱ�����ܵ�ָ��)
loss='binary_crossentropy',
metrics = ['acc'])
#������[0,1]
train_datagen = ImageDataGenerator( rescale = 1.0/255. )
test_datagen = ImageDataGenerator( rescale = 1.0/255. )
#ImageDataGenerator����һ�����ļ���ͼ��ת���������ʽ��ת��ͷ,ͨ���ȶ���һ��ת��ͷtrain_datagen,�����Ը�����Ҫ��ͼ����и��ֱ任,Ȼ���ٰ��������ļ���(flow����������array��),Լ���ó������ݵĸ�ʽ(����ͼ��Ĵ�С��ÿ�γ�������������������ǩ�ĸ�ʽ�ȵ�)�����������train_generator�Ǹ�(X,y)Ԫ��,X��shapeΪ(20,150,150,3),y��shapeΪ(20,)
train_generator = train_datagen.flow_from_directory(train_dir, #����ͼƬ(2000��)����ߴ��СΪ150x150��С
batch_size=20,
class_mode='binary',
target_size=(150, 150))
test_generator = test_datagen.flow_from_directory(test_dir,
batch_size=20,
class_mode = 'binary',
target_size = (150, 150))

��ô������,���Ǿ��Ѿ������ģ�͡��ڴ�ͬʱ,���ǵĹ���Ҳ�����һ���,���������ǰ���������������������ʱ��!
�������һ�����ھ���������CNN����վ,�����վ�����ݱȽ������Ľ����˹��ھ���������CNN�ֵ�֪ʶ�����Ҷ�����֮��,��Ŷ��� ����������CNN ����һ����������Ĵ,������Ը�����˽��������˵,����һ�������Ŀ�ʼ.
��ʼѵ��
ֱ���ϴ���
history = model.fit_generator(train_generator, #���������п���ͼ��ѵ��30��,�������в���ͼ���Ͻ�����֤��
validation_data=validation_generator,
steps_per_epoch=100,
epochs=30,
validation_steps=50,
verbose=2)
���ǻῴ�����������
���Dz��õ���,����Warning����ʾ��Model.fit_generatoris deprecated and will be
removed in a future version. Please useModel.fit, which supports
generators. ����Ŀǰ���ǻ��ǿ�����������ͨ���ǵ����̵�,�����º���Model.fit�����ڻ����Ժ��ѧϰ���õ�����

ѵ������֮�����ʾ��������
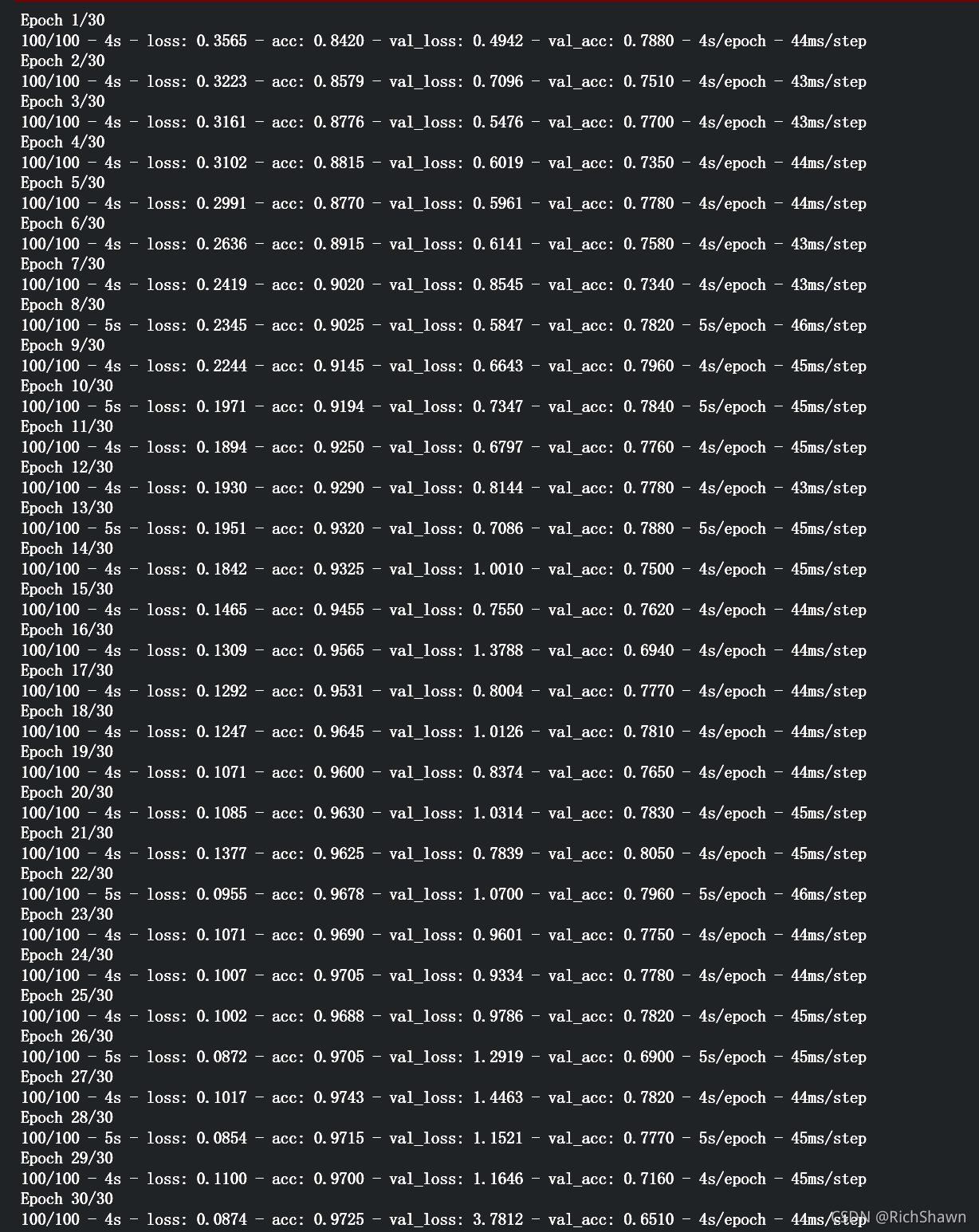
��ô����Щ������:
loss ��ʧ����ֵ,���㶨�����ʧ����ֵ���
acc ȷ��
mean_absolute_error ƽ���������
Loss �� Accuracy ��ѵ�����ȵ�һ���ܺõ�ָ�ꡣ ����ѵ�����ݵķ�����в²�,Ȼ�����ѵ���õ�ģ�Ͷ�����м������� ȷ������ȷ�²�IJ��֡� ��֤ȷ���Ƕ�δ��ѵ����ʹ�õ����ݽ��еļ��㡣 ��ô�����и��ȽϺ�����ͨ�����Ľ���,�����Ҿ���ͦ������
����ѵ��
֮�����Ƕ����ǵ�ģ�ͽ��б���Ϳ�����
model.save('Cats_and_Dogs.h5') #���ֵ��ǿ������ȡ,���ǻ���Ҫ�����Ժ�IJ���
���ļ������λ������ForKeras�� E:\ForKeras Ҳ��������һ��ʼ��ѡ�������ݼ���λ�á�

��������ӻ�
import tkinter as tk
from tkinter import filedialog
import numpy as np
from keras.preprocessing import image
root = tk.Tk()
root.withdraw()
Filepath = filedialog.askopenfilename()
path=Filepath
img=image.load_img(path,target_size=(150, 150))
x=image.img_to_array(img)
x=np.expand_dims(x, axis=0)
images = np.vstack([x])
classes = model.predict(images, batch_size=10)
print(classes[0])
if classes[0]>0:
print("This is a dog")
else:
print("This is a cat")
�������ϴ���֮����һ�������ļ���,����Դ���ѡ�������Ҫ��֤��ͼƬ,Ҳ����ֱ�Ӵ��������ر��浽����֮��������֤,�����è�ǹ�����ʾ�ڴ�����·�,�������ѡ��Ȩ,���ǰ������������
����˵��������������һ����ë

Ȼ���������д���,�ȵ������Ĵ�����ѡ�����ͼƬ

���Ľ������

�ɹ�!
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
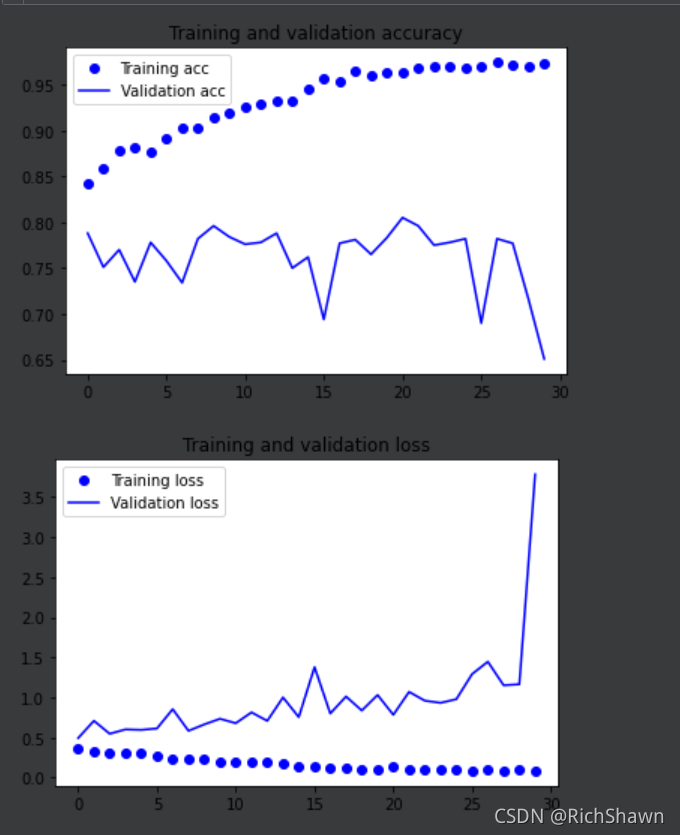
ѵ���������ͼ��ʾ,������ģ�������������,��Ҫԭ�������ݲ���,����˵�����������,ģ������(ѵ����ʧ�ڵ�30��epoch�ͽ�Ϊ0��)��
datagen = ImageDataGenerator(
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
# This is module with image preprocessing utilities
from keras.preprocessing import image
fnames = [os.path.join(train_cats_dir, fname) for fname in os.listdir(train_cats_dir)]
# We pick one image to "augment"
img_path = fnames[3]
# Read the image and resize it
img = image.load_img(img_path, target_size=(150, 150))
# Convert it to a Numpy array with shape (150, 150, 3)
x = image.img_to_array(img)
# Reshape it to (1, 150, 150, 3)
x = x.reshape((1,) + x.shape)
# The .flow() command below generates batches of randomly transformed images.
# It will loop indefinitely, so we need to `break` the loop at some point!
i = 0
for batch in datagen.flow(x, batch_size=1):
plt.figure(i)
imgplot = plt.imshow(image.array_to_img(batch[0]))
i += 1
if i % 4 == 0:
break
plt.show()
�����ʵ���Ƕ���Ƭ�����˲�ͳһ���Ĵ���,�������ӻ��������Ķ�����,���Ը��õ���ǿѵ����Ч����

��Chrome����ɫģʽ�Ѻ����������е㲻���,����Ӱ�첻�Ǻܴ�,����ֻҪ���Կ���ͼ����֮��Ľ���Ϳ����ˡ�
import numpy as np
import random
from tensorflow.keras.preprocessing.image import img_to_array, load_img
#�����
successive_outputs = [layer.output for layer in model.layers[:8]] #layer_outputs:��ȡǰ8������
#���ӻ�ģ��
visualization_model = tf.keras.models.Model(inputs = model.input, outputs = successive_outputs) #activation_model:����һ��ģ��,����ģ�͵�����,���Է�����Щ���
#���ѡ��һ��è��ͼƬ
cat_img_files = [os.path.join(train_cats_dir, f) for f in train_cat_fnames]
dog_img_files = [os.path.join(train_dogs_dir, f) for f in train_dog_fnames]
img_path = random.choice(cat_img_files + dog_img_files)
img = load_img(img_path, target_size=(150, 150))
x = img_to_array(img) #ת��Ϊ150*150*3������
x = x.reshape((1,) + x.shape) #ת��Ϊ1*150*150*3������
#����
x /= 255.0
successive_feature_maps = visualization_model.predict(x)
layer_names = [layer.name for layer in model.layers]
for layer_name, feature_map in zip(layer_names, successive_feature_maps):
if len(feature_map.shape) == 4:
n_features = feature_map.shape[-1]
size = feature_map.shape[ 1]
display_grid = np.zeros((size, size * n_features))
for i in range(n_features):
x = feature_map[0, :, :, i]
x -= x.mean()
x /= x.std ()
x *= 64
x += 128
x = np.clip(x, 0, 255).astype('uint8')
display_grid[:, i * size : (i + 1) * size] = x
scale = 20. / n_features
plt.figure( figsize=(scale * n_features, scale) )
plt.title ( layer_name )
plt.grid ( False )
plt.imshow( display_grid, aspect='auto', cmap='viridis' )
�������ͼ:

acc = history.history[ 'acc' ]
val_acc = history.history[ 'val_acc' ]
loss = history.history[ 'loss' ]
val_loss = history.history['val_loss' ]
epochs = range(len(acc))
plt.plot ( epochs, acc ,label='acc')
plt.plot ( epochs, val_acc ,label='val_acc')
plt.legend(loc='best')
plt.title ('Training and validation accuracy')
plt.figure()
plt.plot ( epochs, loss ,label='loss')
plt.plot ( epochs, val_loss ,label='val_loss')
plt.legend(loc='best')
plt.title ('Training and validation loss')
��ʾ���(Ϊ�˿����ݻ��ǰ�DarkMod����):
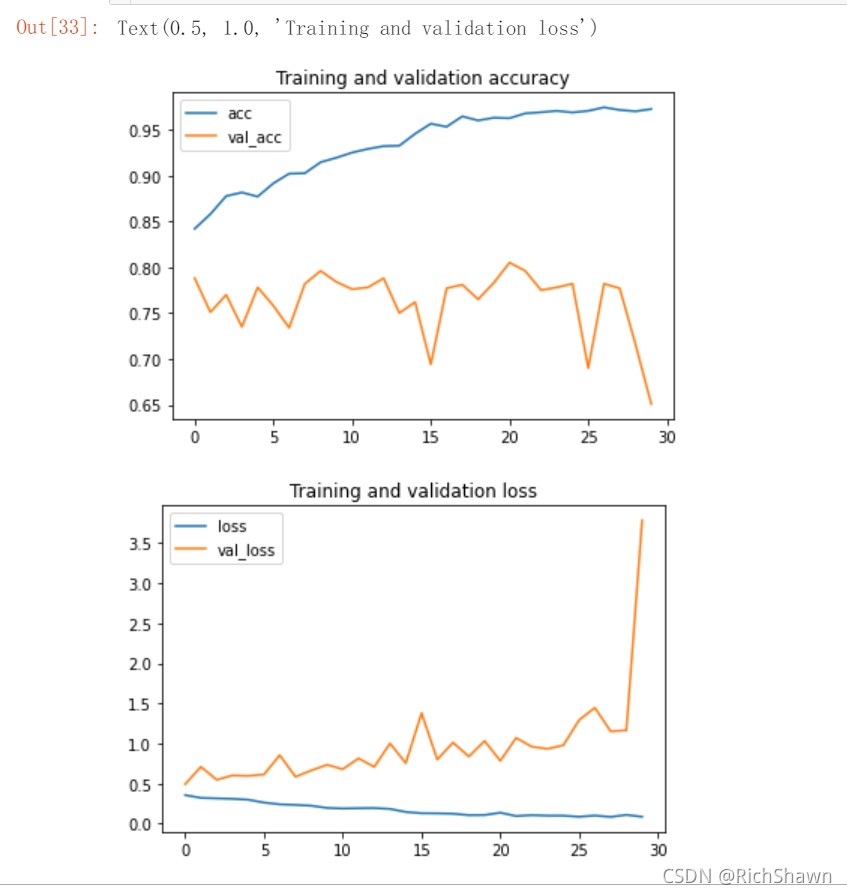
��ô��ʵ�����ǿ��������Ŀ���,ͼ�߷��ֳ����˹���ϵ�����,���ǵ�ѵ��ȷ�ȼ������� 100%,�������ǵĵ���֤��ȷ��ֻ��80%��ȷ��(���ҷ�ֵҲ��10%֮��)��
�ڽyӋ�W��,�^�m(Ӣ�Z:overfitting,��Q�M���^��)��ָ�^춾o�ܻ_��ƥ���ض��Y�ϼ�,����춟o�����õ���������Y�ϻ��A�yδ�����^��Y���ĬF�� �����ģ��ָ��������������ݶ���,����������߽ṹ���ڸ��ӵ�ͳ��ģ�͡� ���������ʱ,ģ�͵�ƫ��С�������
��ô���Ǹ���ν���������?
�������Ѹ�������һЩ˼·:
Ƿ��ϻ����϶��ᷢ����ѵ���տ�ʼ��ʱ��,��������ѵ��֮��Ƿ���Ӧ�ò���ô�����ˡ����������Ļ��Ǵ��ڵĻ�,����ͨ���������縴�ӶȻ�����ģ������������,��Щ���Ǻܺý��Ƿ��ϵķ�����
������
��ô������,����֪�����������̾͵���λ����,�ܸ������ܿ�������,��������֯���滹��һ����Ƿȱ,���Ը�л�������ġ���Ϊ������ѧ�Ĺ����г�������Ϊ�Ӵ���ӷ������֪ʶ������,��̬������һЩСС�ı仯����ϣ����ƪ�����ܹ��������г�ѧ��Positive feedback������ʱ��
����˵����,Ҫ���������� ���� ³Ѹ