基于FPN_Tensorflow的PCB缺陷检测
这一篇实战,参考于:
基于深度学习的印刷电路板瑕疵识别.
因为介绍的数据集的预处理不是很详细,所以在这里再整理一遍,顺便学习新的深度学习网络模型。
一. 原理
Faster R-CNN.
深度学习网络 | FPN和fast rcnn及RPN网络是如何结合的细节.
二. 训练过程
1.数据准备
你可以从这里下载数据集:http://robotics.pkusz.edu.cn/resources/dataset/
我的已经将数据的训练数据和验证数据分配好了,这里按照从官网的数据集下载的来说。
下载好原始数据集的后,你会发现有这么多文件夹:

Annotations文件夹:
需要把各个文件夹的文件全部移动到Annotations/,想这样:
同样,对images/,就这样:
6个文件夹的图片全部移动出来,然后把空的文件夹删掉。
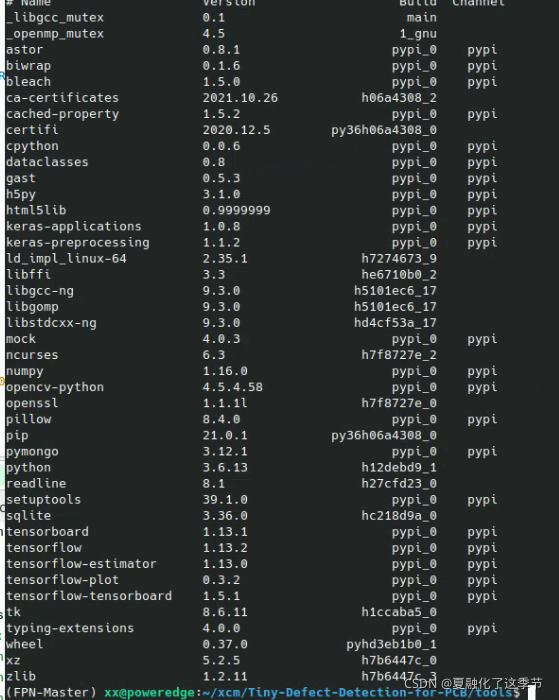
2.下载源代码
环境要求:注意版本匹配
3.数据拆分
将自己的数据集拆分为训练集、测试集合:
python /data/io/divide_data.py
将会生成两个文件夹:

4.修改配置
在/libs/label_name_dict/label_dict.py中添加自己的数据集标签类别。具体如下:
# -*- coding: utf-8 -*-
from __future__ import division, print_function, absolute_import
from libs.configs import cfgs
if cfgs.DATASET_NAME == 'ship':
NAME_LABEL_MAP = {
'back_ground': 0,
'ship': 1
}
elif cfgs.DATASET_NAME == 'aeroplane':
NAME_LABEL_MAP = {
'back_ground': 0,
'aeroplane': 1
}
elif cfgs.DATASET_NAME == 'WIDER':
NAME_LABEL_MAP = {
'back_ground': 0,
'face': 1
}
elif cfgs.DATASET_NAME == 'jyzdata':
NAME_LABEL_MAP = {
'back_ground': 0,
'classone': 1,
'boli': 2,
'dangeboli': 3,
'taoci': 4,
'taoci2': 4
}
elif cfgs.DATASET_NAME == 'icdar':
NAME_LABEL_MAP = {
'back_ground': 0,
'text': 1
}
elif cfgs.DATASET_NAME.startswith('DOTA'):
NAME_LABEL_MAP = {
'back_ground': 0,
'roundabout': 1,
'tennis-court': 2,
'swimming-pool': 3,
'storage-tank': 4,
'soccer-ball-field': 5,
'small-vehicle': 6,
'ship': 7,
'plane': 8,
'large-vehicle': 9,
'helicopter': 10,
'harbor': 11,
'ground-track-field': 12,
'bridge': 13,
'basketball-court': 14,
'baseball-diamond': 15
}
elif cfgs.DATASET_NAME == 'pascal':
NAME_LABEL_MAP = {
'back_ground': 0,
'aeroplane': 1,
'bicycle': 2,
'bird': 3,
'boat': 4,
'bottle': 5,
'bus': 6,
'car': 7,
'cat': 8,
'chair': 9,
'cow': 10,
'diningtable': 11,
'dog': 12,
'horse': 13,
'motorbike': 14,
'person': 15,
'pottedplant': 16,
'sheep': 17,
'sofa': 18,
'train': 19,
'tvmonitor': 20
}
elif cfgs.DATASET_NAME == 'pcb':
NAME_LABEL_MAP = {
'back_ground': 0,
'missing_hole': 1,
'mouse_bite': 2,
'open_circuit': 3,
'short': 4,
'spur': 5,
'spurious_copper': 6
}
else:
assert 'please set label dict!'
def get_label_name_map():
reverse_dict = {}
for name, label in NAME_LABEL_MAP.items():
reverse_dict[label] = name
return reverse_dict
LABEl_NAME_MAP = get_label_name_map()
然后就可以运行convert_data_to_tfrecord.py了。别忘了填上四个参数。
python convert_data_to_tfrecord.py --VOC_dir='***/VOCdevkit/VOCdevkit_train/' --save_name='train' --img_format='.jpg' --dataset='ship'
5.数据转换
下一步,需要分别将训练和测试数据转换成 TFrecord 格式。该格式是TensorFlow的高效存储格式,连续的内存二进制存储能够有效的加快数据的读取和写入。而像原始文件夹那样每个数据独立存储。
python convert_data_to_tfrecord.py --VOC_dir='***/data/pcb_test/' --save_name='test' --img_format='.jpg' --dataset='pcb'
python convert_data_to_tfrecord.py --VOC_dir='***/data/pcb_train/' --save_name='train' --img_format='.jpg' --dataset='pcb'
# 上一步训练、测试数据分离后的文件夹路径
--VOC_dir='你的数据路径'
#tfrecord名字。训练数据用'train' ,测试数据用'test'
--save_name='train'
#你的图片格式。有Png\tif\jpeg
--img_format='.jpg'
#你的数据集名字。这个需要在/libs/label_name_dict/label_dict.py中添加自己的数据集
--dataset='mydataset
6.参数设置
对应里面的model,应先下载好预训练模型,放在 /data/pretrained_weights/ 中。
预训练模型的下载地址:
Res101: resnet_v1_101_2016_08_28.tar.gz.
Res50: resnet_v1_50_2016_08_28.tar.gz.
数据准备好了,那么训练就要调参和调一些路径啦。打开/libs/configs/cfgs.py。
# -*- coding: utf-8 -*-
from __future__ import division, print_function, absolute_import
import os
import tensorflow as tf
# ------------------------------------------------
VERSION = 'FPN_Res101_0117_OHEM'#-----------------改
NET_NAME = 'resnet_v1_101'#-----------------改
ADD_BOX_IN_TENSORBOARD = True
# ---------------------------------------- System_config
ROOT_PATH = os.path.abspath('/home/cg/机器视觉与机器学习/工业缺陷检测项目/基于FPN的PCB缺陷检测/Xia-Detection-for-PCB')#工程文件路径-----------------改
print (20*"++--")
print (ROOT_PATH)
GPU_GROUP = "2"
SHOW_TRAIN_INFO_INTE = 10
SMRY_ITER = 100
SAVE_WEIGHTS_INTE = 10000
SUMMARY_PATH = ROOT_PATH + '/output/summary'
TEST_SAVE_PATH = ROOT_PATH + '/tools/test_result'
INFERENCE_IMAGE_PATH = ROOT_PATH + '/tools/inference_image'
INFERENCE_SAVE_PATH = ROOT_PATH + '/tools/inference_results'
if NET_NAME.startswith("resnet"):
weights_name = NET_NAME
elif NET_NAME.startswith("MobilenetV2"):
weights_name = "mobilenet/mobilenet_v2_1.0_224"
else:
raise NotImplementedError
PRETRAINED_CKPT = ROOT_PATH + '/data/pretrained_weights/' + weights_name + '.ckpt'
TRAINED_CKPT = os.path.join(ROOT_PATH, 'output/trained_weights')
EVALUATE_DIR = ROOT_PATH + '/output/evaluate_result_pickle/'
#test_annotate_path = '/home/yjr/DataSet/VOC/VOC_test/VOC2007/Annotations'
test_annotate_path = '/home/cg/机器视觉与机器学习/工业缺陷检测项目/基于FPN的PCB缺陷检测/pcb数据集/PCB_DATASET/Annotations/'#-----------------改
# ------------------------------------------ Train config
RESTORE_FROM_RPN = False
IS_FILTER_OUTSIDE_BOXES = False
FIXED_BLOCKS = 0 # allow 0~3
USE_07_METRIC = False
RPN_LOCATION_LOSS_WEIGHT = 1.
RPN_CLASSIFICATION_LOSS_WEIGHT = 1.0
FAST_RCNN_LOCATION_LOSS_WEIGHT = 1.0
FAST_RCNN_CLASSIFICATION_LOSS_WEIGHT = 1.0
RPN_SIGMA = 3.0
FASTRCNN_SIGMA = 1.0
MUTILPY_BIAS_GRADIENT = None # 2.0 # if None, will not multipy
GRADIENT_CLIPPING_BY_NORM = None # 10.0 if None, will not clip
EPSILON = 1e-5
MOMENTUM = 0.9
LR = 0.001 # 0.001 # 0.0003
#DECAY_STEP = [60000, 80000] # 50000, 70000
DECAY_STEP = [10000, 20000] # 50000, 70000
#MAX_ITERATION = 150000
MAX_ITERATION = 30000
# ------------------------------------------- Data_preprocess_config
DATASET_NAME = 'pcb' # 'ship', 'spacenet', 'pascal', 'coco' #-----------------改
# PIXEL_MEAN = [123.68, 116.779, 103.939] # R, G, B. In tf, channel is RGB. In openCV, channel is BGR
PIXEL_MEAN = [21.25, 85.936, 28.729] #-----------------改
IMG_SHORT_SIDE_LEN = 600 # 600
IMG_MAX_LENGTH = 3000 # 1000
CLASS_NUM = 6 #-----------------改
# --------------------------------------------- Network_config
BATCH_SIZE = 1
INITIALIZER = tf.random_normal_initializer(mean=0.0, stddev=0.01)
BBOX_INITIALIZER = tf.random_normal_initializer(mean=0.0, stddev=0.001)
WEIGHT_DECAY = 0.00004 if NET_NAME.startswith('Mobilenet') else 0.0001
# ---------------------------------------------Anchor config
USE_CENTER_OFFSET = False
LEVLES = ['P2', 'P3', 'P4', 'P5', 'P6']
# BASE_ANCHOR_SIZE_LIST = [32, 64, 128, 256, 512] # addjust the base anchor size for voc.
BASE_ANCHOR_SIZE_LIST = [15, 25, 40, 60, 80] # addjust the base anchor size for voc.
#BASE_ANCHOR_SIZE_LIST = [8, 15, 25, 40, 60]
ANCHOR_STRIDE_LIST = [4, 8, 16, 32, 64]
ANCHOR_SCALES = [2., 3., 4.]
ANCHOR_RATIOS = [2., 3., 4., 5.]
# ANCHOR_SCALES = [1.0]
# ANCHOR_RATIOS = [0.5, 1., 2.0]
ROI_SCALE_FACTORS = [10., 10., 5.0, 5.0]
ANCHOR_SCALE_FACTORS = None
# --------------------------------------------FPN config
SHARE_HEADS = True
KERNEL_SIZE = 3
RPN_IOU_POSITIVE_THRESHOLD = 0.7
RPN_IOU_NEGATIVE_THRESHOLD = 0.3
TRAIN_RPN_CLOOBER_POSITIVES = False
RPN_MINIBATCH_SIZE = 256
RPN_POSITIVE_RATE = 0.5
RPN_NMS_IOU_THRESHOLD = 0.7
RPN_TOP_K_NMS_TRAIN = 12000
#RPN_MAXIMUM_PROPOSAL_TARIN = 2000
RPN_MAXIMUM_PROPOSAL_TARIN = 2000
RPN_TOP_K_NMS_TEST = 6000
RPN_MAXIMUM_PROPOSAL_TEST = 1000
# specific settings for FPN
# FPN_TOP_K_PER_LEVEL_TRAIN = 2000
# FPN_TOP_K_PER_LEVEL_TEST = 1000
# -------------------------------------------Fast-RCNN config
ROI_SIZE = 14
ROI_POOL_KERNEL_SIZE = 2
#USE_DROPOUT = False
USE_DROPOUT = True
KEEP_PROB = 1.0
SHOW_SCORE_THRSHOLD = 0.6 # only show in tensorboard
#FAST_RCNN_NMS_IOU_THRESHOLD = 0.3 # 0.6
FAST_RCNN_NMS_IOU_THRESHOLD = 0.3
FAST_RCNN_NMS_MAX_BOXES_PER_CLASS = 100
FAST_RCNN_IOU_POSITIVE_THRESHOLD = 0.5
FAST_RCNN_IOU_NEGATIVE_THRESHOLD = 0.0 # 0.1 < IOU < 0.5 is negative
FAST_RCNN_MINIBATCH_SIZE = 256 # if is -1, that is train with OHEM
# FAST_RCNN_MINIBATCH_SIZE = -1
FAST_RCNN_POSITIVE_RATE = 0.25
#ADD_GTBOXES_TO_TRAIN = False
ADD_GTBOXES_TO_TRAIN = True
注意配置好路径,和参数。
7.训练
python /tools/train.py
等着训练完成吧。
8.验证测试
cd $PATH_ROOT/tools
python inference.py --data_dir='/PATH/TO/IMAGES/'
--save_dir='/PATH/TO/SAVE/RESULTS/'
--GPU='0'
训练完之后会在output/summary文件夹里,生成
9.效果
发现效果根训练的迭代次数有很大关系,迭代迭代次数越多,训练时间越长,一开始训练了两天时间,30000的迭代值。

需要源代码包的私信我就可啦。期待下一次的实战项目。