基于Tensorflow实现Transformer模型
1.Transformer模型

import tensorflow as tf
from official.transformer.model import attention_layer
from official.transformer.model import beam_search
from official.transformer.model import embedding_layer
from official.transformer.model import ffn_layer
from official.transformer.model import model_utils
from official.transformer.utils.tokenizer import EOS_ID
class Transformer(object):
"""
transformer模型由encoder和decoder创建。输入是int序列,encoder产生连续输出,decoder使用ecoder output输出序列概率
"""
def __int__(self,params,train):
"""
transformer model 初始化
:param params: 超参数设置,如:layer size,dropout rate 等
:param train: train模式使用dropput
:return:
"""
self.trian=train
self.params=params
self.embedding_softmax_layer=embedding_layer.EmbeddingSharedWeights(
params['vocab_size'],params['hidden_size'],
method='matmul' if params['tpu'] else 'gather'
)
def __call__(self, inputs, targets=None):
"""
训练/预测阶段的模型输出
:param input: tensor shape[batch_size,input_lenght]
:param targets: None 或者 shape[batch_size,target_length]
:return: 训练模式下,输出[batch_size,target_length,vocab_size];预测模式下,输出字典:
{
output:[batch_size,decoded_length]
# BLEU分数
score:[batch_size,float]
}
"""
initizlizer=tf.variance_scaling_initializer(
self.params['initializerz_gain'],mode='fan_avg',
distribution='unform'
)
with tf.variable_scope('transformer',initializer=initizlizer):
attention_bias=model_utils.get_padding_bias(inputs)
encoder_outputs=self.encode(inputs,attention_bias)
if targets == None:
return self.predict(encoder_outputs,attention_bias)
else:
logits=self.decode(targets,encoder_outputs,attention_bias)
return logits
def encode(self,inputs,attention_bias):
"""
:param inputs: int shape[batch_size,input_length]
:param attention_bias:float shape[batch_size,1,1,input_length]
:return: float shape[batch_size,input_length,hidden_size]
"""
with tf.name_scope('encode'):
embedding_inputs=self.embedding_softmax_layer(inputs)
inputs_padding=model_utils.get_padding(inputs)
with tf.name_scope('add_pos_encoding'):
lenth=tf.shape(embedding_inputs)[1]
pos_encoding=model_utils.get_position_encoding(
lenth,self.params['hidden_size']
)
encoder_inputs=embedding_inputs+pos_encoding
if self.train:
encoder_inputs=tf.nn.dropout(
encoder_inputs,1-self.params['layer_postprocess_dropout']
)
return self.encode_stack(encoder_inputs,attention_bias,inputs_padding)
def decode(self,targets,encoder_outputs,attention_bias):
"""
:param targets: int shape[batch_size,target_size]
:param encoder_outputs: float shape[batch_size,input_lenth,hidden_size]
:param attention_bias: float shape[batch_size,1,1,input_length]
:return: float shape[batch_size,target_lenth,vocab_size]
"""
with tf.name_scope('decode'):
decoder_inputs=self.embedding_softmax_layer(targets)
with tf.name_scope('shift_targets'):
decoder_inputs=tf.pad(
decoder_inputs,[[0,0],[1,0],[0,0]]
)[:,:-1,:]
with tf.name_scope('add_pos_encoding'):
length=tf.shape(decoder_inputs)[1]
decoder_inputs+=model_utils.get_position_encoding(
length,self.params['hidden_size']
)
if self.train:
decoder_inputs=tf.nn.dropout(
decoder_inputs,1-self.params['layer_posprocess_dropout']
)
decoder_self_attention_bias=model_utils.get_decoder_self_attention_bias(length)
outputs=self.decoder_stack(
decoder_inputs,encoder_outputs,decoder_self_attention_bias,attention_bias
)
logits=self.embedding_softmax_layer.linear(outputs)
return logits
def _get_symbols_to_logits_fn(self,max_decode_length):
"""
返回一个用于计算下一个tokens模型输出值的方法
:param max_decode_length:
:return:
"""
timing_signal=model_utils.get_position_encoding(
max_decode_length+1,self.params['hidden_size']
)
decoder_self_atttention_bias=model_utils.get_decoder_self_attention_bias(max_decode_length)
def symbols_to_logits_fn(ids,i,cache):
"""
生成下一个模型输出值ID
:param ids:当前编码序列
:param i: 循环索引
:param cache: 保存ecoder_output,encoder-decoder attention bias,上一个decoder attention bias值
:return: ([batch_size*beam_size,vocab_size],updated cache values)
"""
decoder_input=ids[:,-1,:]
decoder_input=self.embedding_softmax_layer(decoder_input)
decoder_input+=timing_signal[i:i+1]
self_attention_bias=decoder_self_atttention_bias[:, :, i:i + 1, :i + 1]
decoder_outputs=self.decoder_stack(
decoder_input,cache.get('encoder_outputs'),self_attention_bias,
cache.get('encoder_decoder_attention_bias'),cache
)
logits=self.embedding_softmax_layer.linear(decoder_outputs)
logits=tf.squeeze(logits,axis=[1])
return logits,cache
return symbols_to_logits_fn
def predict(self,encoder_outputs,encoder_decoder_attention_bias):
"""
:param endoer_outputs:
:param encoder_decoder_attention_bias:
:return:
"""
batch_size=tf.shape(encoder_outputs)[0]
input_length=tf.shape(encoder_outputs)[1]
max_decode_length=input_length+self.params['extra_decode_length']
symbols_to_logits_fn=self._get_symbols_to_logits_fn(max_decode_length)
initial_ids=tf.zeros(shape=[batch_size],dtype=tf.int32)
cache={
'layer_%d'%layer:{
'k':tf.zeros([batch_size,0,self.params['hidden_size']]),
'v':tf.zeros([batch_size,0,self.params['hidden_size']])
}for layer in range(self.params['num_hidden_layers'])
}
cache['encoder_outputs']=encoder_outputs
cache['encoder_decoder_attention_bias']=encoder_decoder_attention_bias
decoded_ids,scores=beam_search.sequence_beam_search(
symbols_to_logits_fn=symbols_to_logits_fn,
initial_ids=initial_ids,
initial_cache=cache,
vocab_size=self.params["vocab_size"],
beam_size=self.params["beam_size"],
alpha=self.params["alpha"],
max_decode_length=max_decode_length,
eos_id=EOS_ID
)
top_decoded_ids=decoded_ids[:,0,1:]
top_scores=scores[:,0]
return {'outputs':top_decoded_ids,"scores":top_scores}
class LayerNormalization(tf.keras.layers.Layer):
def __int__(self,hidden_size):
super(LayerNormalization,self).__init__()
self.hidden_size=hidden_size
def build(self,_):
self.scale=tf.get_variable('layer_nor_scale',[self.hidden_size],initializer=tf.ones_initializer())
self.bias=tf.get_variable('layer_norm_bias',[self.hidden_size],initializer=tf.zeros_initializer())
self.built=True
def call(self, x, epsilon=1e-6):
mean = tf.reduce_mean(x, axis=[-1], keepdims=True)
variance = tf.reduce_mean(tf.square(x - mean), axis=[-1], keepdims=True)
norm_x = (x - mean) * tf.rsqrt(variance + epsilon)
return norm_x * self.scale + self.bias
class PrePostProcessingWrapper(object):
"""
用于包装模型起点的attention层和最后的feed_forward全连接层
"""
def __int__(self,layer,params,train):
self.layer=layer,
self.postprocess_dropout=params['layer_postprocess_dropout']
self.train=train
self.layer_norm=LayerNormalization(params['hidden_size'])
def __call__(self, x,*args, **kwargs):
y=self.layer_norm(x)
y=self.layer(y,*args,**kwargs)
if self.train:
y=tf.nn.dropout(y,1-self.postprocess_dropout)
return x+y
class EncoderStack(tf.keras.layers.Layer):
"""
模型默认6层encoder,每一层有两个子层:1,self-attention层,2,feedforward全连接层(此层内又有两个子层)
"""
def __init__(self,params,train):
super(EncoderStack,self).__init__()
self.layers=[]
for _ in range(params['num_hidden_layers']):
self_attention_layer=attention_layer.SelfAttention(
params['hidden_size'],params['num_heads'],
params['attention_dropout'],train
)
feed_forward_network=ffn_layer.FeedFowardNetwork(
params['hidden_size'],params['filter_size'],
params['relu_dropout'],train,params['allow_ffn_add']
)
self.layers.append([
PrePostProcessingWrapper(self_attention_layer,params,train),
PrePostProcessingWrapper(feed_forward_network,params,train)
])
self.output_normalization=LayerNormalization(params['hidden_size'])
def call(self,encoder_inputs,attention_bias,inputs_padding):
"""
返回叠层的encoder output
:param encoder_inputs: int shape[batch_size,input_length,hidden_size]
:param attention_bias: shape[batch_size,1,1,input_length]
:param inputs_padding:
:return: float shape[batch_size,input_length,hidden_size]
"""
for n,layer in enumerate(self.layers):
self_attention_layer=layer[0]
feed_forward_network=layer[1]
with tf.variable_scope('layer_%d'%n):
with tf.variable_scope('self_attention'):
encoder_inputs=self_attention_layer(encoder_inputs,attention_bias)
with tf.variable_scope('ffn'):
encoder_inputs=feed_forward_network(encoder_inputs,inputs_padding)
return self.output_normalization
class DecoderStack(tf.keras.layers.Layer):
"""
层数与encoder一样,区别是decoder有三层
1,attention层
2,融合encoder output 前一个attention层的多头注意力层
3,feedforward全连接层(此层内又有两个子层)
"""
def __int__(self,params,train):
super(DecoderStack,self).__init__()
self.layers=[]
for _ in range(params['num_hidden_size']):
self_attention_layer=attention_layer.SelfAttention(
params['hidden_size'],params['num_heads'],
params['attention_dropout'],train
)
enc_dec_attention_layer=attention_layer.Attention(
params['hidden_size'],params['num_heads'],
params['attention_dropout'],train
)
feed_forward_network=ffn_layer.FeedFowardNetwork(
params['hidden_size'],params['filter_size'],
params['relu_dropout'],train,params['allow_ffn_pad']
)
self.layers.append([
PrePostProcessingWrapper(self_attention_layer,params,train),
PrePostProcessingWrapper(enc_dec_attention_layer,params,train),
PrePostProcessingWrapper(feed_forward_network,params,train)
])
self.output_normalization=LayerNormalization(params['hidden_size'])
def call(self,decoder_inputs, encoder_outputs, decoder_self_attention_bias,
attention_bias, cache=None):
"""
:param decoder_inputs: shape[batch_size,target_length,hidden_size]
:param encoder_outputs: shape[batch_size,input_length,hidden_size]
:param decoder_self_attention_bias:[1,1,target_len,target_length]
:param attention_bias: shape[batch_size,1,1,input_length]
:param cache:
:return: float shape[batch_size,target_length,hidden_size]
"""
for n,layer in enumerate(self.layers):
self_attention_layer=layer[0]
enc_dec_attention_layer=layer[1]
feed_forward_network=layer[2]
layer_name = "layer_%d" % n
layer_cache = cache[layer_name] if cache is not None else None
with tf.variable_scope(layer_name):
with tf.variable_scope('self_attention'):
decoder_inputs=self_attention_layer(
decoder_inputs,decoder_self_attention_bias,cache
)
with tf.variable_scope('encdec_attention'):
decoder_inputs=enc_dec_attention_layer(
decoder_inputs,encoder_outputs,attention_bias
)
with tf.variable_scope('ffn'):
decoder_inputs=feed_forward_network(decoder_inputs)
return self.output_normalization(decoder_inputs)
2.Attention
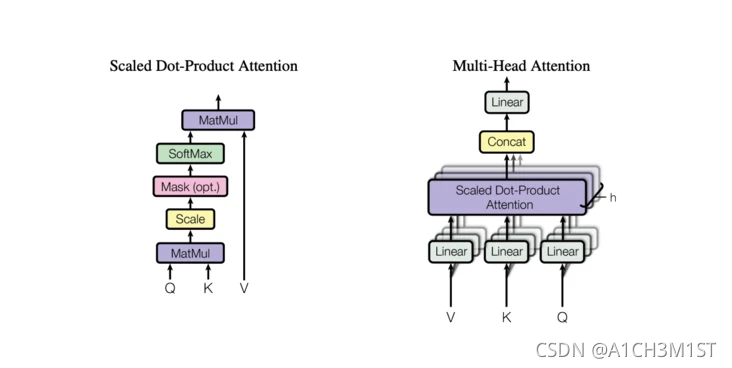
import tensorflow as tf
class Attention(tf.keras.layers.Layer):
"""
多头注意力层
"""
def __init__(self,hidden_size,num_heads,attention_dropout,train):
if hidden_size % num_heads != 0:
raise ValueError('Hidden size must be evenly divisible by the number of ""heads')
super(Attention,self).__init__()
self.hidden_size=hidden_size
self.num_heads=num_heads
self.attention_dropout=attention_dropout
self.train=train
self.q_dense_layer=tf.keras.layers.Dense(hidden_size,use_bias=False,name='q')
self.k_dense_layer=tf.keras.layers.Dense(hidden_size,use_bias=False,name='k')
self.v_dense_layer=tf.keras.layers.Dense(hidden_size,use_bias=False,name='v')
self.output_dense_layer=tf.keras.layers.Dense(hidden_size,use_bias=False,name='outpout_dropout')
def split_heads(self,x):
"""
将x拆分不同的注意力head,并将结果转置(转置的目的是为了矩阵相乘时维度正确)
:param x: shape[batch_size,length,hidden_size]
:return: shape[batch_size,num_heads,length,hidden_size/num_heads]
"""
with tf.name_scope('split_heads'):
batch_size=tf.shape(x)[0]
length=tf.shape(x)[1]
depth=(self.hidden_size // self.num_heads)
x=tf.reshape(x,[batch_size,length,self.num_heads,depth])
return tf.transpose(x,[0,2,1,3])
def combine_heads(self,x):
"""
将拆分的张量再次连接(split_heads逆操作),input是split_heads_fn的输出
:param x: shape[batch_size,num_heads,length,hidden_size/num_heads]
:return: shape[batch_size,length,hidden_size]
"""
with tf.name_scope('combine_heads'):
batchs_size=tf.shape(x)[0]
length=tf.shape(x)[2]
x=tf.transpose(x,[0,2,1,3])
return tf.reshape(x,[batchs_size,length,self.hidden_size])
def call(self,x,y,bias,cache=None):
"""
:param x: shape[batch_size,length_x,hidden_size]
:param y: shape[batch_size,length_y,hidden_size]
:param bias: 与点积结果相加
:param cache: 预测模式使用;返回类型为字典:
{
'k':shape[batch_size,i,key_channels],
'v':shape[batch_size,i,value_channels]
}
i:当前decoded长度
:return: shape[batch_size,length_x,hidden_size]
"""
q=self.q_dense_layer(x)
k=self.k_dense_layer(y)
v=self.v_dense_layer(y)
if cache is not None:
k=tf.concat([cache['k'],k],axis=1)
v=tf.concat([cache['v'],v],axis=1)
cache['k']=k
cache['v']=v
q=self.split_heads(q)
k=self.split_heads(k)
v=self.split_heads(v)
depth = (self.hidden_size // self.num_heads)
q *= depth ** -0.5
logits=tf.matmul(q,k,transpose_b=True)
logits+=bias
weights=tf.nn.softmax(logits,name='attention_weight')
if self.train:
weights=tf.nn.dropout(weights,1.0-self.attention_dropout)
attention_outpout=tf.matmul(weights,v)
attention_outpout=self.combine_heads(attention_outpout)
attention_outpout=self.output_dense_layer(attention_outpout)
return attention_outpout
class SelfAttention(Attention):
"""多头注意力层"""
def call(self, x, bias, cache=None):
return super(SelfAttention, self).call(x, x, bias, cache)
3.Embedding
import tensorflow as tf
from official.transformer.model import model_utils
from official.utils.accelerator import tpu as tpu_utils
class EmbeddingSharedWeights(tf.keras.layers.Layer):
"""
用于encoder,decoder的input embedding,并共享权重
"""
def __init__(self,vocab_size,hidden_size,method='gater'):
"""
:param voab_size: 标记字符(tokens)数量,一般小于32000
:param hidden_size:embedding层神经元数量,一般512或1024
:param method: gather更适用于CPU,GPU,matmulTPU运算更快
"""
super(EmbeddingSharedWeights,self).__init__()
self.vocab_size=vocab_size
self.hidden_size=hidden_size
if method not in ('gather','matmul'):
raise ValueError("method {} must be 'gather' or 'matmul'".format(method))
self.method=method
def build(self,_):
with tf.variable_scope('embedding_and_softmax',reuse=tf.AUTO_REUSE):
self.shared_weights=tf.get_variable(
'weights',shape=[self.vocab_size,self.hidden_size],
initializer=tf.random_normal_initializer(
0.,self.hidden_size**-0.5
)
)
self.built=True
def call(self,x):
"""
获取embedding后的x
:param x: int shape[batch_size,length]
:return: embeddings:shape [batch_size,length,embedding_size]
padding: shape[batch_size,length]
因为模型默认输入长度必须是固定的,所以需要补长。现在有其它衍变版本transformer-xl可以实现动态更改长度
"""
with tf.name_scope('embedding'):
mask=tf.to_float(tf.not_equal(x,0))
if self.method == 'gather':
embeddings=tf.gather(self.shared_weights)
embeddings*=tf.expand_dims(mask,-1)
else:
embeddings=tpu_utils.embedding_matmul(
embedding_table=self.shared_weights,
values=tf.cast(x,type=tf.int32),
mask=mask
)
embeddings*=self.hidden_size**0.5
return embeddings
def linear(self,x):
"""
输出模型logits
:param x: shape[batch_size,length,hidden_size]
:return: shape[batch_size,length,vovab_size]
"""
with tf.name_scope('presoftmax_linear'):
batch_size=tf.shape(x)[0]
length=tf.shape(x)[1]
x=tf.reshape(x,[-1,self.hidden_size])
logits=tf.matmul(x,self.shared_weights,transpose_b=True)
return tf.reshape(logits, [batch_size, length, self.vocab_size])
4.FFN_layer
import tensorflow as tf
class FeedFowardNetWork(tf.keras.layers.Layer):
"""
全连接层,共2层
"""
def __init__(self,hidden_size,filter_size,relu_dropout,train,allow_pad):
super(FeedFowardNetWork,self).__init__()
self.hidden_size=hidden_size
self.filter_size=filter_size
self.relu_dropout=relu_dropout
self.train=train
self.all_pad=allow_pad
self.filter_dense_layer=tf.keras.layers.Dense(
filter_size,use_bias=True,activation=tf.nn.relu,
name='filter_layer'
)
self.outpout_dense_layer=tf.keras.layers.Dense(
hidden_size,use_bias=True,name='outpout_layer'
)
def call(self,x,padding=None):
"""
返回全连接层输出
:param x: shape[batch_size,length,hidden_size]
:param padding:shape[batch_size,length]
:return:
"""
padding=None if not self.all_pad else padding
batch_size=tf.shape(x)[0]
length=tf.shape(x)[1]
if padding is not None:
with tf.name_scope('remove_padding'):
pad_mask=tf.reshape(padding,[-1])
nopad_ids=tf.to_int32(tf.where(pad_mask<1e-9))
x=tf.reshape(x[-1,self.hidden_size])
x=tf.gather_nd(x,indices=nopad_ids)
x.set_shape([None, self.hidden_size])
x = tf.expand_dims(x, axis=0)
outpout=self.filter_dense_layer(x)
if self.train:
outpout=tf.nn.dropout(outpout,1.0-self.relu_dropout)
outpout=self.outpout_dense_layer(outpout)
if padding is not None:
with tf.name_scope('re_add_padding'):
output=tf.squeeze(outpout,axis=0)
output = tf.scatter_nd(
indices=nopad_ids,
updates=output,
shape=[batch_size * length, self.hidden_size]
)
output = tf.reshape(output, [batch_size, length, self.hidden_size])
return output
5.模型参数
from collections import defaultdict
"""
基本模型参数配置
"""
BASE_PARAMS = defaultdict(
lambda: None,
default_batch_size=2048,
default_batch_size_tpu=32768,
max_length=256,
initializer_gain=1.0,
vocab_size=33708,
hidden_size=512,
num_hidden_layers=6,
num_heads=8,
filter_size=2048,
layer_postprocess_dropout=0.1,
attention_dropout=0.1,
relu_dropout=0.1,
label_smoothing=0.1,
learning_rate=2.0,
learning_rate_decay_rate=1.0,
learning_rate_warmup_steps=16000,
optimizer_adam_beta1=0.9,
optimizer_adam_beta2=0.997,
optimizer_adam_epsilon=1e-09,
extra_decode_length=50,
beam_size=4,
use_tpu=False,
static_batch=False,
allow_ffn_pad=True,
)
BIG_PARAMS = BASE_PARAMS.copy()
BIG_PARAMS.update(
default_batch_size=4096,
default_batch_size_tpu=16384,
hidden_size=1024,
filter_size=4096,
num_heads=16,
)
BASE_MULTI_GPU_PARAMS = BASE_PARAMS.copy()
BASE_MULTI_GPU_PARAMS.update(
learning_rate_warmup_steps=8000
)
BIG_MULTI_GPU_PARAMS = BIG_PARAMS.copy()
BIG_MULTI_GPU_PARAMS.update(
layer_postprocess_dropout=0.3,
learning_rate_warmup_steps=8000
)
TINY_PARAMS = BASE_PARAMS.copy()
TINY_PARAMS.update(
default_batch_size=1024,
default_batch_size_tpu=1024,
hidden_size=32,
num_heads=4,
filter_size=256,
)
|