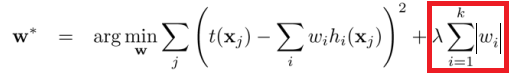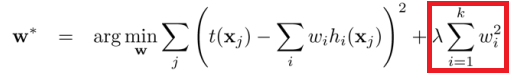- 正则项有那些类别
主要分为L1正则和L2正则,或者叫做一范数和二范数正则。
首先,范数(norm)是指向量在空间中的长度。用于对向量进行衡量。
范数的一般计算公式为:
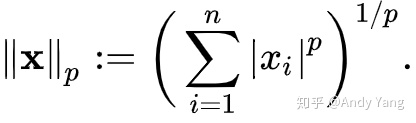
如果p值为1,就是一范数,p为2就是2范数。
范数可以用作损失函数或者是正则项。用作损失函数时,不同的范数起到的作用是不同的。
一范数作为损失函数时,可以看作是偏差的绝对值:
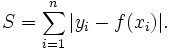
当使用二范数作为损失函数时,可以看作是和偏差的欧式距离:
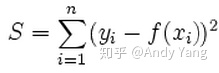
优化欧式距离的方法,就是最小二乘法。
使用一范数作为损失函数并没有使用二范数那么方便,因为一范数的导数函数是不连续的,所以无法直接求导得到最优解。而使用一范数的优势在于,能够增强模型的强健性。换句话说,使用二范数会容易让模型出现过拟合。原因是,由于一范数和二范数的特点不同,他们的一阶导的是这样的:

可见无论w等于多少,梯度总是-1或者是1,所以在经历过若干步后,这个特征很有可能会消失。在模型中,如果一个特征的作用并不明显,就有可能会被消除,这样可以保证模型是简洁的,也就保证模型不那么容易过拟合。
二范数的一阶导是:

随着w的值接近0时,梯度越来越小,所以很难收敛到0,这样导致很多不重要的特征被保留下来,模型变得冗余,泛化能力也会下降。
同理,在使用一范数和二范数作为损失函数时,也会存在类似的问题,一范数的正则函数的输出具有稀疏性。同时,一范数没有特定的最优解,而二范数有,一范数的优化要比二范数的优化在计算上复杂一点。