
论文链接:https://arxiv.org/pdf/2111.11418.pdf
代码链接:https://github.com/sail-sg/poolformer
一、背景和动机
如图1a所示,Transformer 的 encoder 由两个部分组成:
- attention for mixing information
- MLP & residual connections
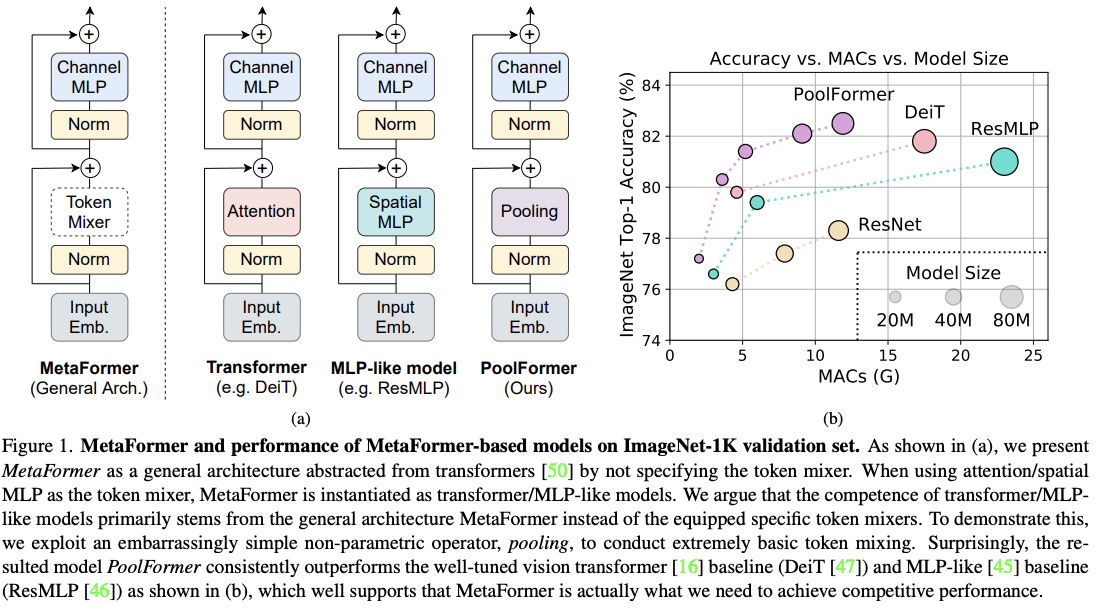
Transformer 最近在计算机视觉任务上展示了很好的效果,大家基本上都认为这种成功来源于基于 self-attention 的结构。但又有文章证明,只使用 MLP 也能达到很好的效果,所以作者假设 Transformer 的效果来源于 transformer 的结构,而非将 token 进行融合交互的模块。
所以,作者使用简单的 spatial pooling 模块替换了 attention 模块,来实现 token 之间的信息交互,称为 PoolFormer,也能达到很好的效果。
在 ImageNet-1K 上达到了 82.1% 的 top-1 acc。
作者使用 PoolFormer 证明了他们的猜想,并且提出了 “MetaFormer” 的概念,也就是一种从 Transformer 中抽象出来的结构,没有特殊的 token mixer 方式。
二、方法
2.1 MetaFormer
MetaFormer 其实是 Transformer 的一个抽象,其他部分和 Transformer 保持一致,token mixer 方式是不特殊指定的。
① 首先,输入
I
I
I 经过 embedding:
X
=
I
n
p
u
t
E
m
d
(
I
)
X=InputEmd(I)
X=InputEmd(I)
② 然后,将 embedding token 输入 MetaFormer blocks,该 block 包含两个残差 sub-blocks
- 第一个 sub-block:token mixer,即在 tokens 之间进行信息传递
Y = T o k e n M i x e r ( N o r m ( X ) ) + X Y=TokenMixer(Norm(X))+X Y=TokenMixer(Norm(X))+X
- 第二个 sub-block:两个 MLP & 激活层
Z = σ ( N o r m ( Y ) W 1 ) W 2 + Y Z=\sigma(Norm(Y)W_1)W_2+Y Z=σ(Norm(Y)W1?)W2?+Y
2.2 PoolFormer
作者为了证明猜想,使用了非常简单的 pooling 算子来实现 token mixer,没有任何可学习参数。
假设输入形式为 T ∈ R C × H × W T\in R^{C\times H \times W} T∈RC×H×W,channel 维度在前,则 pooling 操作如下, k k k 为 pooling 大小:
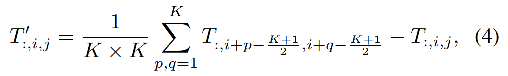
伪代码如下:

已知,self-attention 和 spatial MLP 的计算复杂度是 token 个数的平方,且仅仅能处理一百个左右的 token,pooling 的复杂度与序列的长度是呈线性关系的,且没有可学习参数。
作者使用层级的方式来进行 pooling,如图 2 所示。
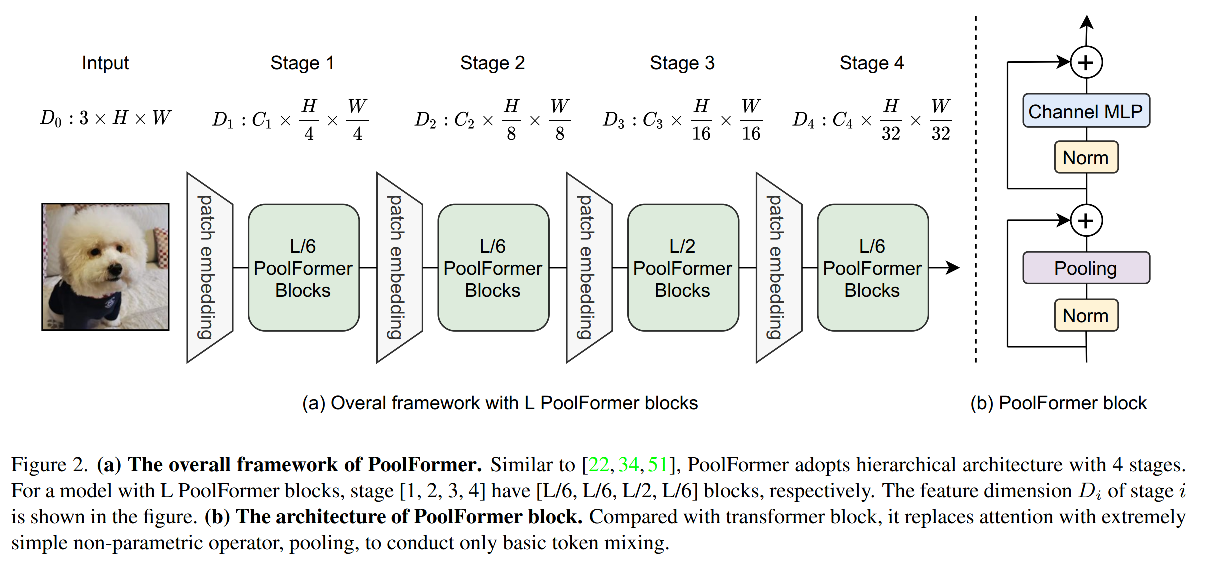
PoolFormer 共 4 个 stages,tokens 的大小分别为:
- H 4 × W 4 \frac{H}{4} \times \frac{W}{4} 4H?×4W?
- H 8 × W 8 \frac{H}{8} \times \frac{W}{8} 8H?×8W?
- H 16 × W 16 \frac{H}{16} \times \frac{W}{16} 16H?×16W?
- H 32 × W 32 \frac{H}{32} \times \frac{W}{32} 32H?×32W?
不同大小的模型使用不同的编码维度:
- 小尺度模型:4 个 stages 分别为 64,128,320,512
- 中尺度模型:4 个 stages 分别为 96,192,384,768
假设模型中共有 L L L 个 PoolFormer blocks,则 4 个 stages 中包含的 block 数量分别为:
- L / 6 L/6 L/6
- L / 6 L/6 L/6
- L / 2 L/2 L/2
- L / 6 L/6 L/6
MLP expansion ratio:4
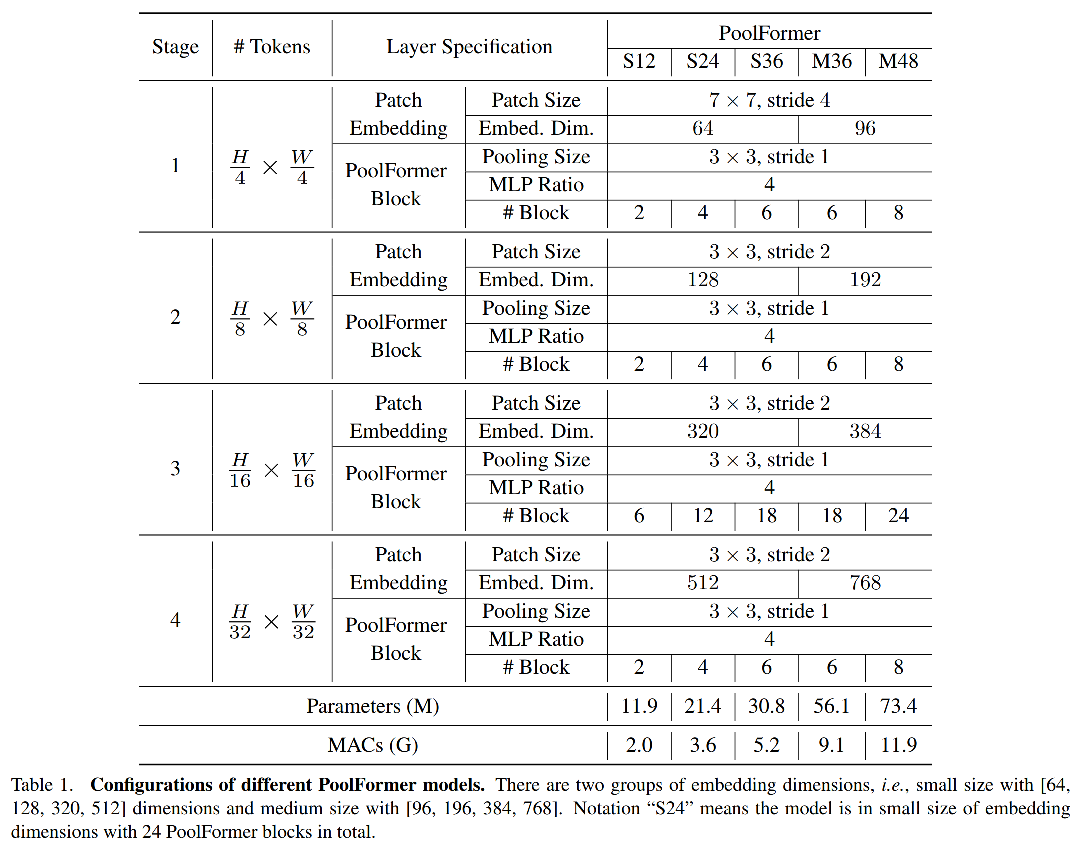
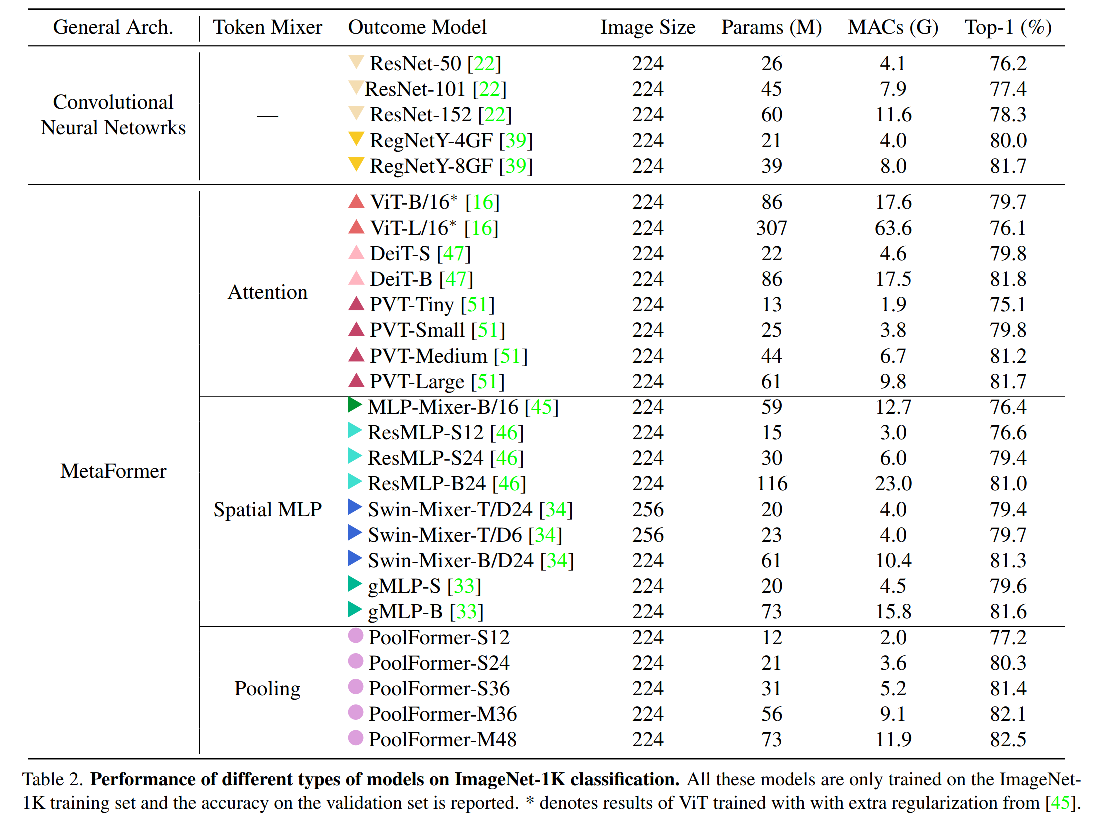
五种不同大小的 PoolFormer 模型参数如表 1 所示:
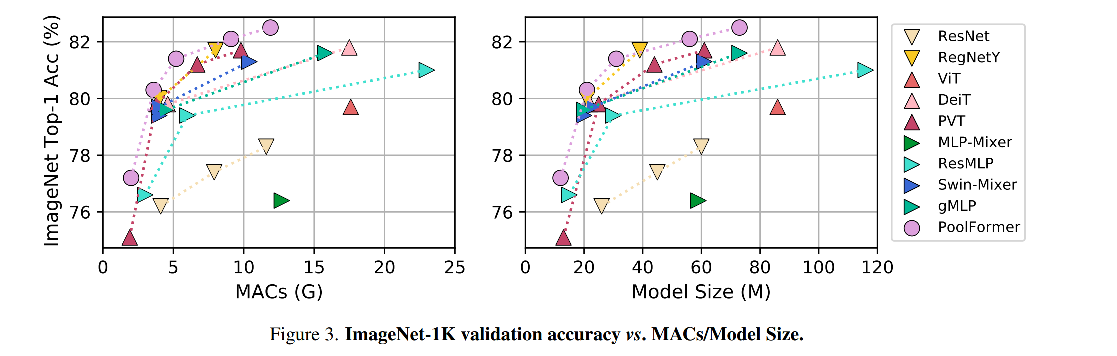
三、效果
1、分类
使用 pooling 操作,每个 token 都能从其邻近的 token 中平均的抽取特征,所以可以看做是最基本的 token mixing 方式,但 PoolFormer 仍然取得了很好的效果。
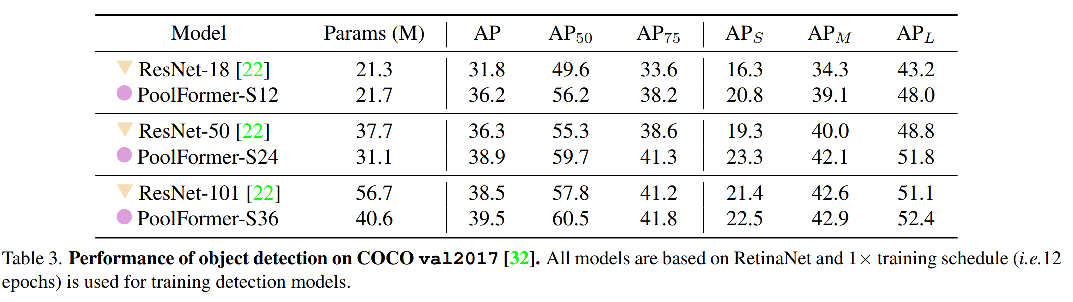
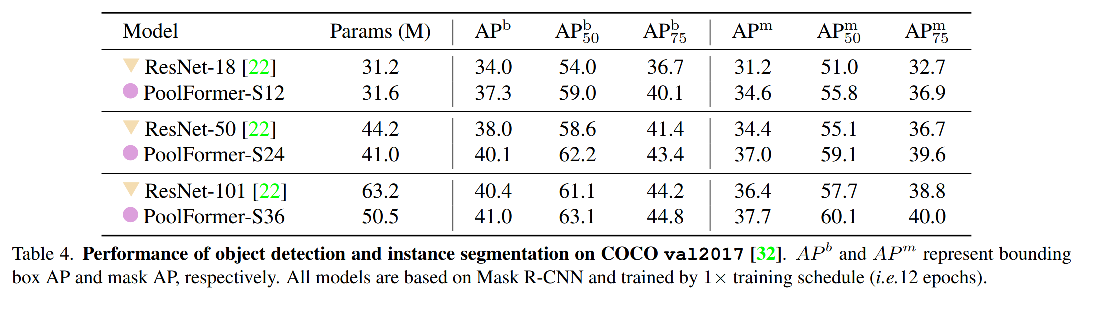
2、检测
作者将 PoolFormer 作为 RetinaNet 和 Mask RCNN 的主干网络,来证明 PoolFormer 的效果。
PoolFormer-based RetinaNet 超越了基于 ResNet 的效果,
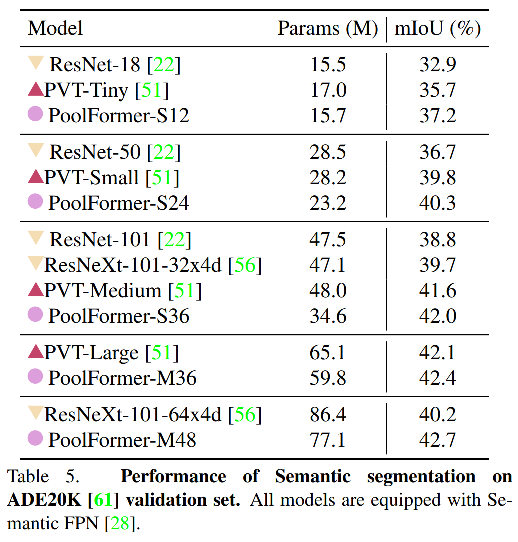
3、语义分割
作者使用 PoolFormer 作为 Semantic FPN 的主干网络,使用 mmsegmentation 训练的结果如下。超越了基于 CNN 的网络。
4、消融实验
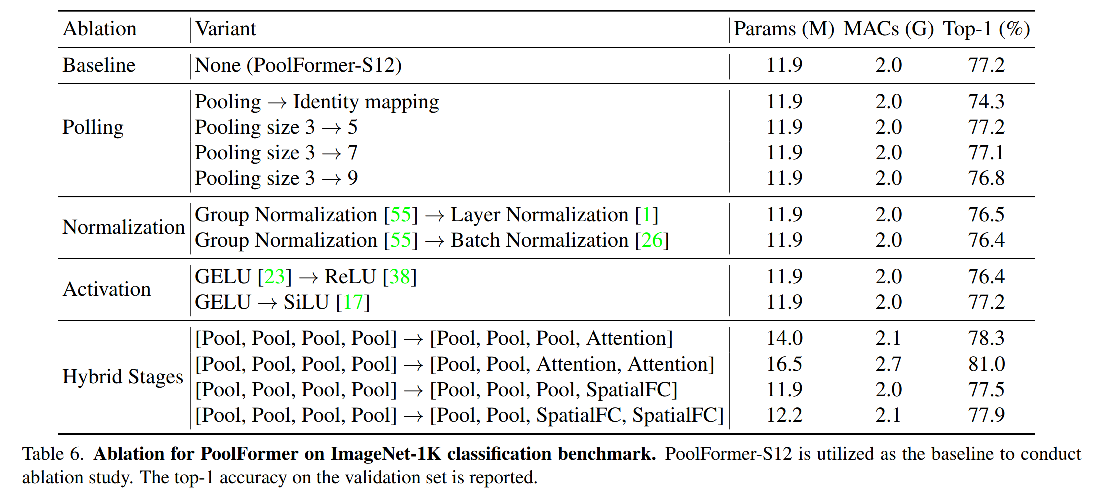
① 为了证明使用 pooling 的效果,作者对该操作做了消融实验。
作者首先使用恒等映射来代替 pooling,发现仍能达到 74.3% 的top-1 acc,证明了作者认为的 Transformer 的结构的重要性。
然后对不同 pooling size 做了实验,当使用 3,5,7 的时候,效果都差不多。使用 9 的时候,性能下降了 0.5%,所以,作者使用了 3。
② 多个 stage 的效果
关于 pooling、MLP、attention 这三种不同的 token mixer 方式。pooling 方式能够处理更长的输入序列,attention 和 MLP 更能捕捉全局信息,所以,这也是作者使用 pooling 在低层 stage 来解决长序列问题,在高层 stage 使用 attention 或 MLP 的原因。
为了验证这种方法的效果,作者使用 FC 或 attention 来代替低层的 pooling,如表 6 所示,效果也不错。但前两层用 pooling,最后两层用 attention 的方法达到了最好的效果。
四、代码
pooling 模块代码
class Pooling(nn.Module):
"""
Implementation of pooling for PoolFormer
--pool_size: pooling size
"""
def __init__(self, pool_size=3):
super().__init__()
self.pool = nn.AvgPool2d(
pool_size, stride=1, padding=pool_size//2, count_include_pad=False)
def forward(self, x):
return self.pool(x) - x
poolformer block
class PoolFormerBlock(nn.Module):
"""
Implementation of one PoolFormer block.
--dim: embedding dim
--pool_size: pooling size
--mlp_ratio: mlp expansion ratio
--act_layer: activation
--norm_layer: normalization
--drop: dropout rate
--drop path: Stochastic Depth,
refer to https://arxiv.org/abs/1603.09382
--use_layer_scale, --layer_scale_init_value: LayerScale,
refer to https://arxiv.org/abs/2103.17239
"""
def __init__(self, dim, pool_size=3, mlp_ratio=4.,
act_layer=nn.GELU, norm_layer=GroupNorm,
drop=0., drop_path=0.,
use_layer_scale=True, layer_scale_init_value=1e-5):
super().__init__()
self.norm1 = norm_layer(dim)
self.token_mixer = Pooling(pool_size=pool_size)
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim,
act_layer=act_layer, drop=drop)
# The following two techniques are useful to train deep PoolFormers.
self.drop_path = DropPath(drop_path) if drop_path > 0. \
else nn.Identity()
self.use_layer_scale = use_layer_scale
if use_layer_scale:
self.layer_scale_1 = nn.Parameter(
layer_scale_init_value * torch.ones((dim)), requires_grad=True)
self.layer_scale_2 = nn.Parameter(
layer_scale_init_value * torch.ones((dim)), requires_grad=True)
def forward(self, x):
if self.use_layer_scale:
x = x + self.drop_path(self.layer_scale_1.unsqueeze(-1).unsqueeze(-1) * self.token_mixer(self.norm1(x)))
x = x + self.drop_path(self.layer_scale_2.unsqueeze(-1).unsqueeze(-1) * self.mlp(self.norm2(x)))
else:
x = x + self.drop_path(self.token_mixer(self.norm1(x)))
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x