本文来自JVET-X0023《EE1: Summary of Exploration Experiments onNeural Network-based Video Coding》
本提案是JVET-X EE1的实验总结,EE1是基于神经网络的视频编码的实验。包含了在W次会议到X次会议间完成了11个NNVC的技术实验,及它们的性能和复杂度分析。基于NN的环路滤波的几种变种技术在RA配置下码率节省2~10%,复杂度30~800kMAC/pxl(每个像素的平均累加乘法操作数)。几种基于NN的超分辨技术对4K内容在RA配置下平均节省1~6%。完成了基于NN的帧内预测跨平台实现和交叉验证,帧内编码性能提升3%以上。
测试条件和评价指标
EE1的实验条件和评价指标和AGH11相同。anchor是VTM11.0,开启基于GOP的时域滤波。QP={22,27,32,37,42}。需要注意的是,超分辨的技术离目标码率还很远,所以其RD曲线相比其他技术的没那么可靠。
客观实验结果总结
表1是RA配置下的客观实验结果。
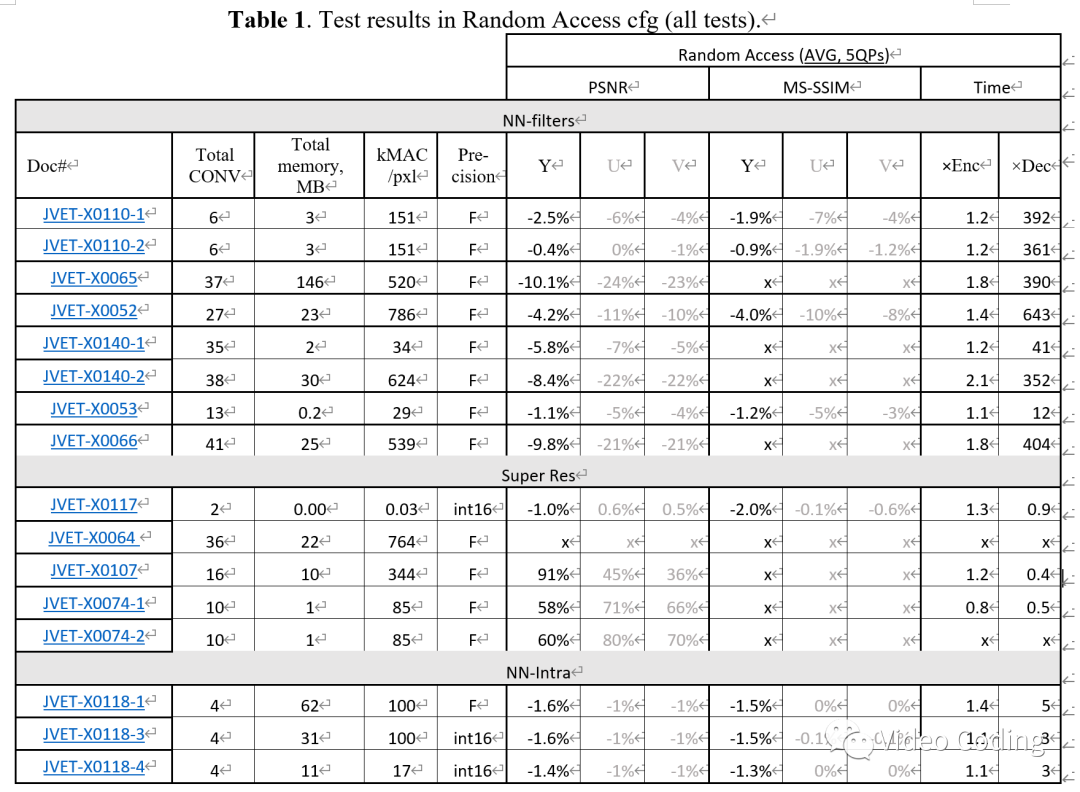
其中NN-filters表示基于NN的滤波技术提案的结果,Super Res表示基于NN的超分辨提案的结果,NN-Intra表示基于NN的帧内预测提案的结果。各列的含义为,Total CONV表示卷积层数,Total memory MB表示模型占用空间大小,kMAC/pxl表示平均每个像素累加乘法操作数用于衡量复杂度,Precision表示模型精度F表示浮点精度、int16表示16位整数精度。
由表1实验结果可得出以下结论:
结论1
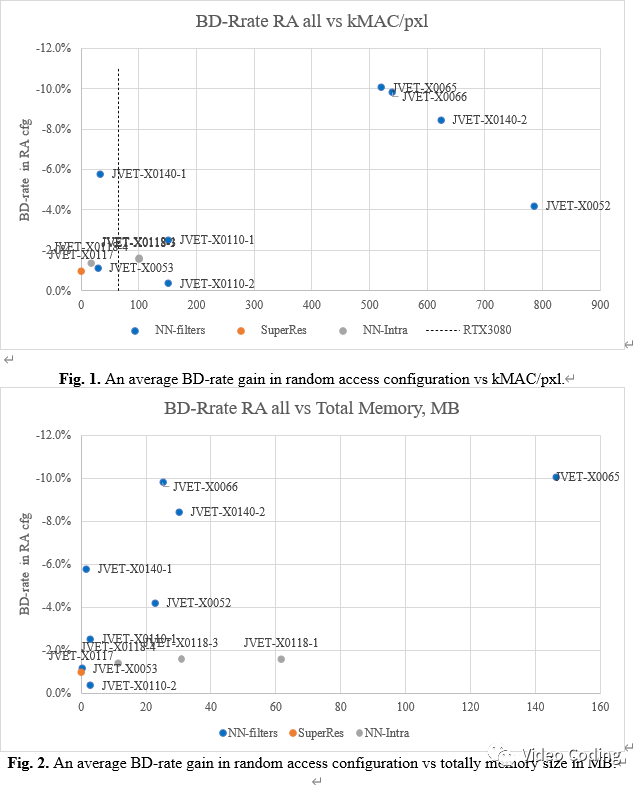
图1和图2分别是BD-Rate vs kMAC/pxl和BD-Rate vs Total Memory MB的曲线图。虚线表示NVIDIA RTX3080达到4K@60fps的处理能力时对应的kMAX/pxl。图1中最复杂提案的复杂度也在100kMAC/pxl以下,且相当于VTM增益在10%左右。
图2中模型大小也是反映复杂度的重要指标,寻找模型大小和性能间的平衡很重要。例如JVET-X0065和JVET-X0066在图1中很接近,但在图2中模型大小却相差很多。
结论2
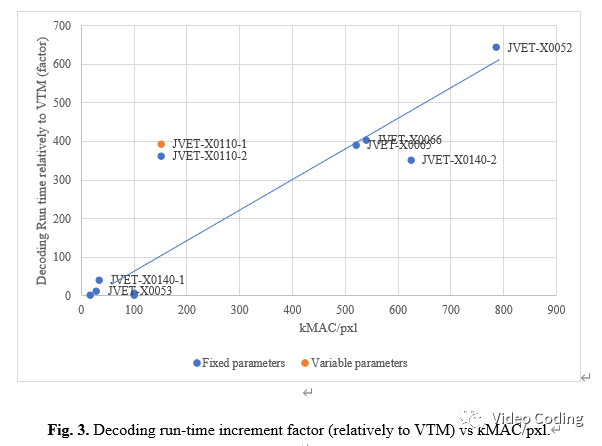
在kMAC/pxl和解码时间增长因子间有很强的相关性,如图3所示。使用微调的模型参数会导致解码时间稍长,可能是其导致更频繁的NN滤波引起的。
结论3
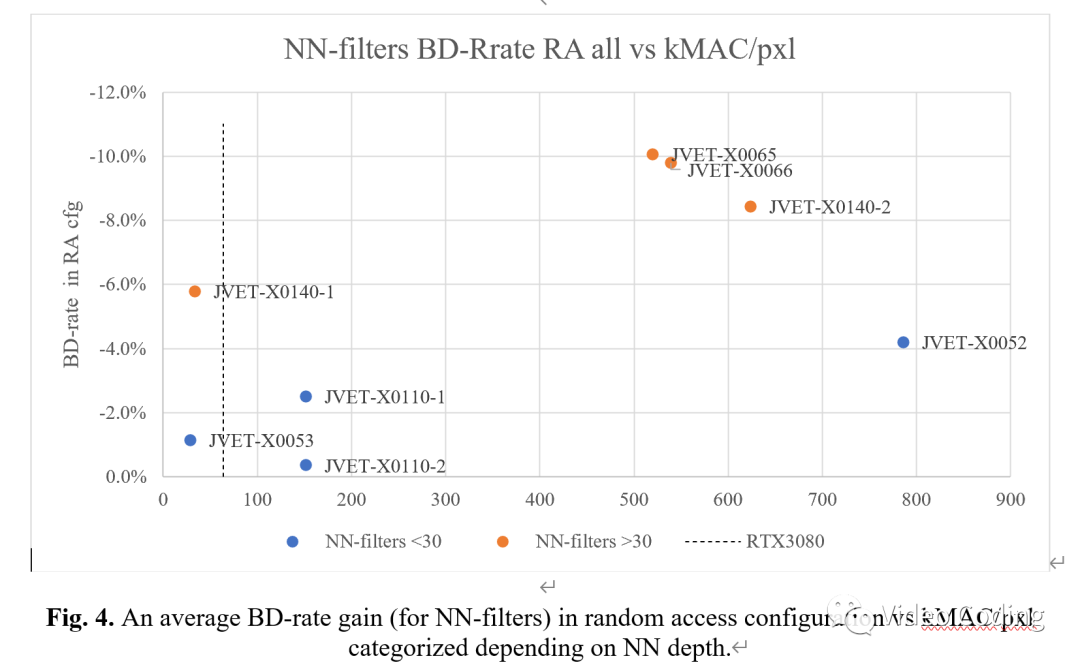
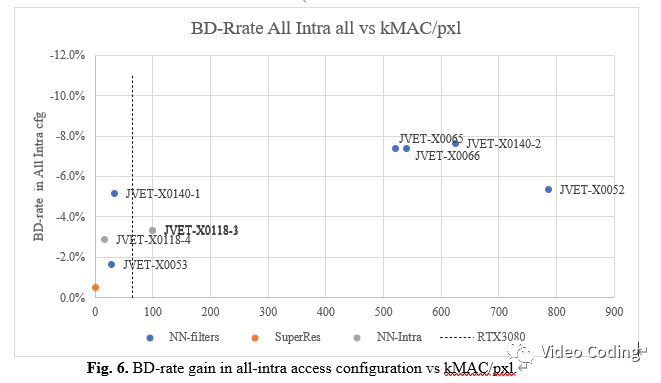
卷积层数更多的神经网络在复杂度和性能间有更好的平衡,如图4所示。图4中仅包含基于NN的滤波的技术,基于NN的帧内预测技术也类似。
结论4
基于NN的滤波和基于NN的帧内预测技术的基于PSNR BD-Rate和基于MS-SSIM BD-Rate增益很接近,而基于NN的超分辨结果中基于MS-SSIM的增益几乎了PSNR的两倍,表明MS-SSIM对于分辨率的改变不敏感。
超分辨技术提案
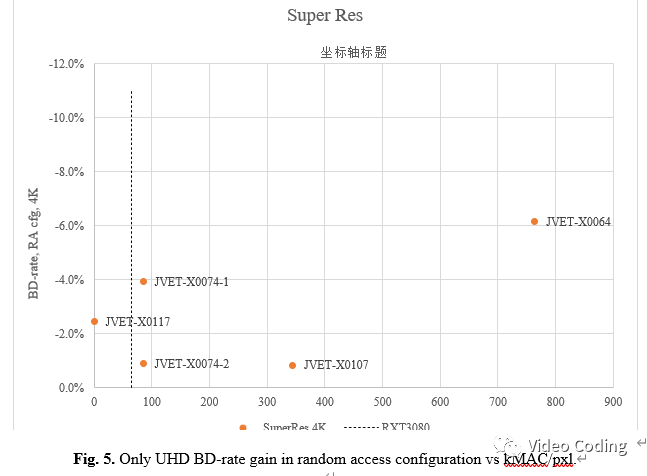
由于本类实验中并不是所有提案都对针对所有测试序列给出结果,所以图1中会缺失部分结果。超分辨提案在高分辨率序列上效果更好。表2和图5显示了在UHD序列(A1,A2类)上的结果。

NN-Intra技术提案
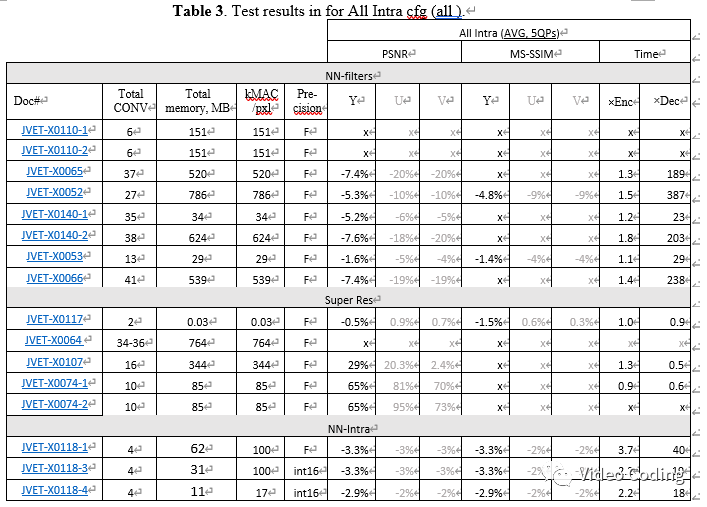
帧内预测技术在all intra配置下效果更好,表3是all intra配置的结果。在all intra配置下,相比于NN-filter,NN-intra卷积层数更少kMAC/pxl复杂度更低,且结果非常有竞争力。
感兴趣的请关注微信公众号Video Coding
