全文总结于哔哩大学的视频:李宏毅2020机器学习深度学习(完整版)国语
2020版课后作业范例和作业说明在github上:点击此处
李宏毅上传了2020版本的机器学习视频和吴恩达的CS229机器学习相比,中文版本的机器学习显得亲民了许多,李宏毅的机器学习是英文的ppt+中文讲解,非常有利于大家入门。吴恩达的CS229中偏向于传统机器学习(线性回归、逻辑回归、Naive Bayes、决策树、支持向量机等),李宏毅2020版本的机器学习中除了最前面的回归、分类,后面更多篇幅涉及卷积神经网络(CNN)、循环神经网络(RNN)、强化学习(RL)等深度学习的内容。
博客内容多为转载。结合哔哩大学的视频观看效果更佳。

文章目录
Gradient Descent
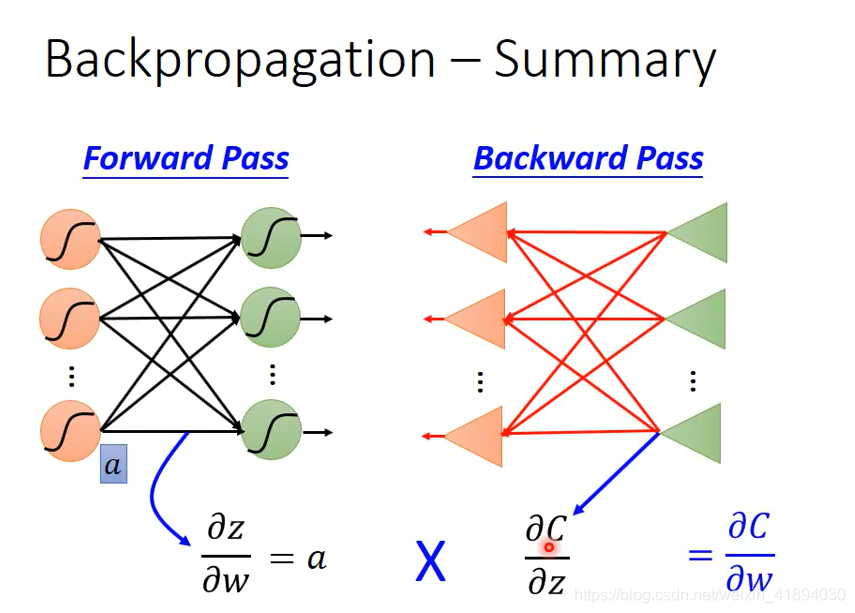
BP只是为了更加高效地进行梯度计算。

Chain Rule链式法则

输入一个
x
n
x^n
</span><span class="katex-html"><span class="base"><span class="strut" style="height: 0.664392em; vertical-align: 0em;"></span><span class="mord"><span class="mord mathdefault">x</span><span class="msupsub"><span class="vlist-t"><span class="vlist-r"><span class="vlist" style="height: 0.664392em;"><span class="" style="top: -3.063em; margin-right: 0.05em;"><span class="pstrut" style="height: 2.7em;"></span><span class="sizing reset-size6 size3 mtight"><span class="mord mathdefault mtight">n</span></span></span></span></span></span></span></span></span></span></span></span>,经过神经网络后,得到 <span class="katex--inline"><span class="katex"><span class="katex-mathml">
loss L,对某一个参数进行计算微分。
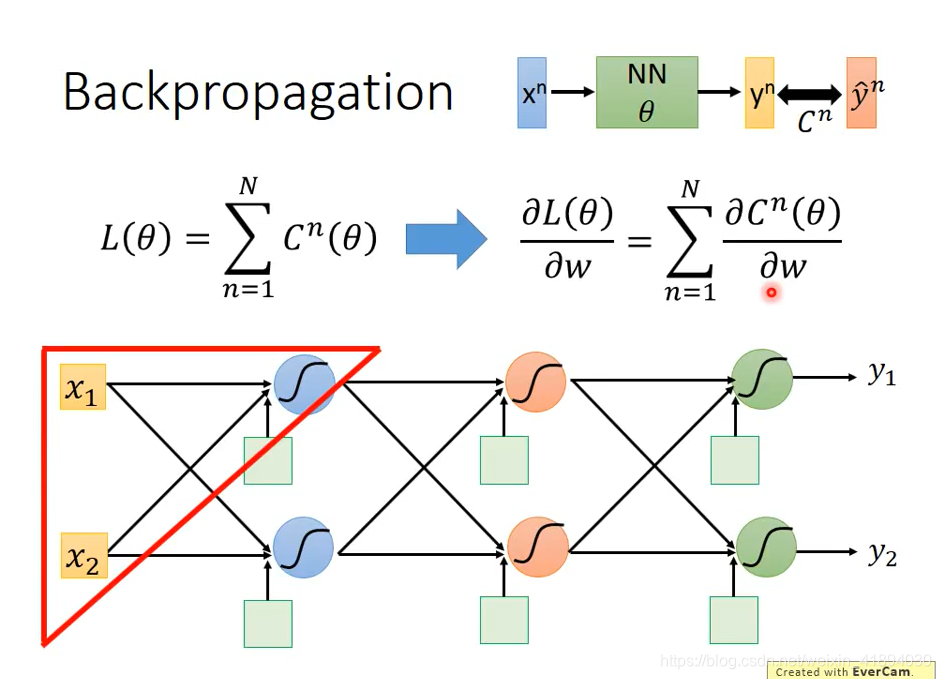
前向传播
先考虑一个单独的neural
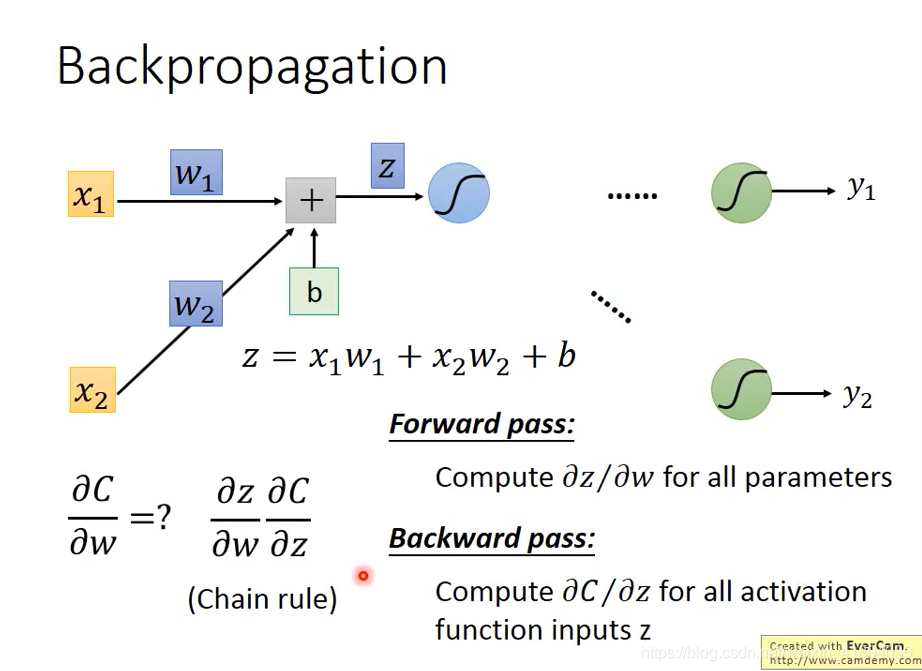
如何计算
a
l
t
=
"
在
这
里
插
入
图
片
描
述
"
>
alt="在这里插入图片描述">
alt="在这里插入图片描述">
在前馈时同时用变量存储了每层的梯度
反向传播
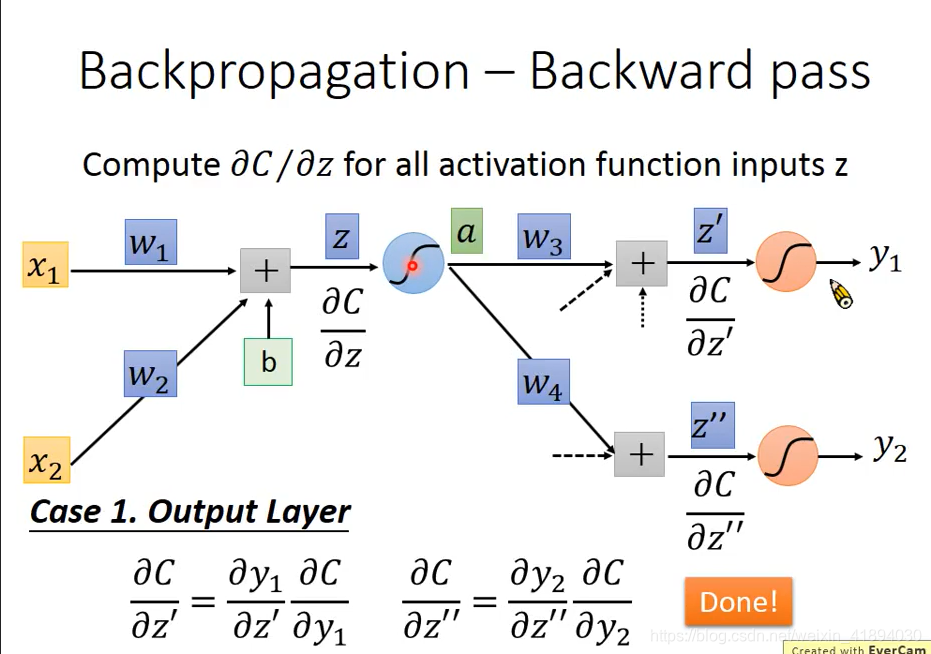
如何计算 ) ) ):知道损失函数、output和target之间是如何evaluate评价的(cross entropy或者mean square error)
在这种情况下(图中蓝色的激活函数是最后一个隐藏层的激活函数,后面就是输出层了),这样就已经完成了。
情况二:假设红色的neural并不是整个网络的output,后面还有其他的东西
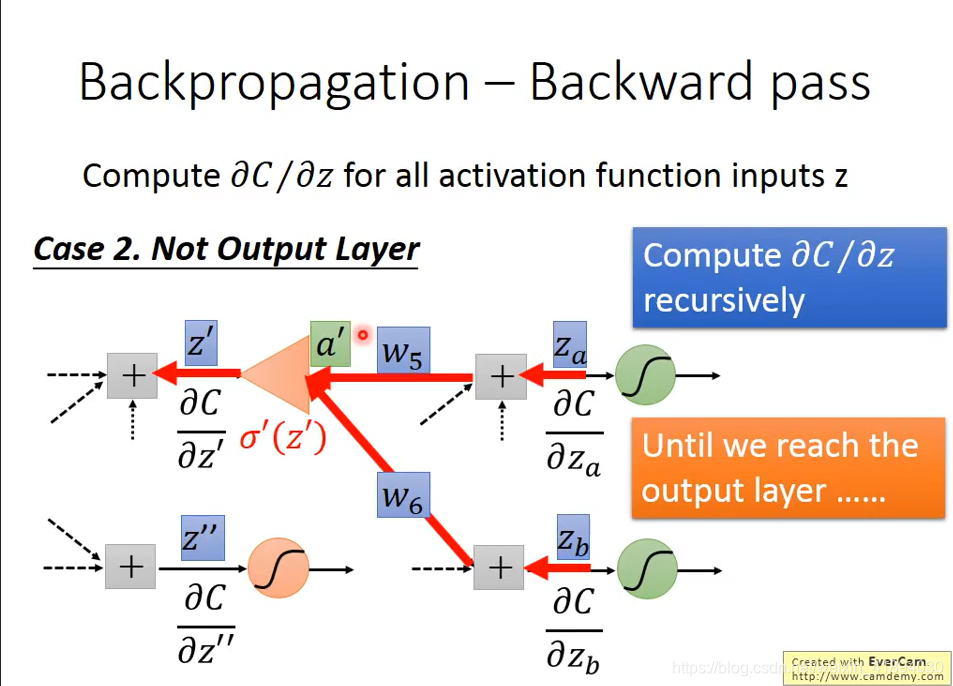
从前往后算没有效率,所以要从输出层开始倒着算
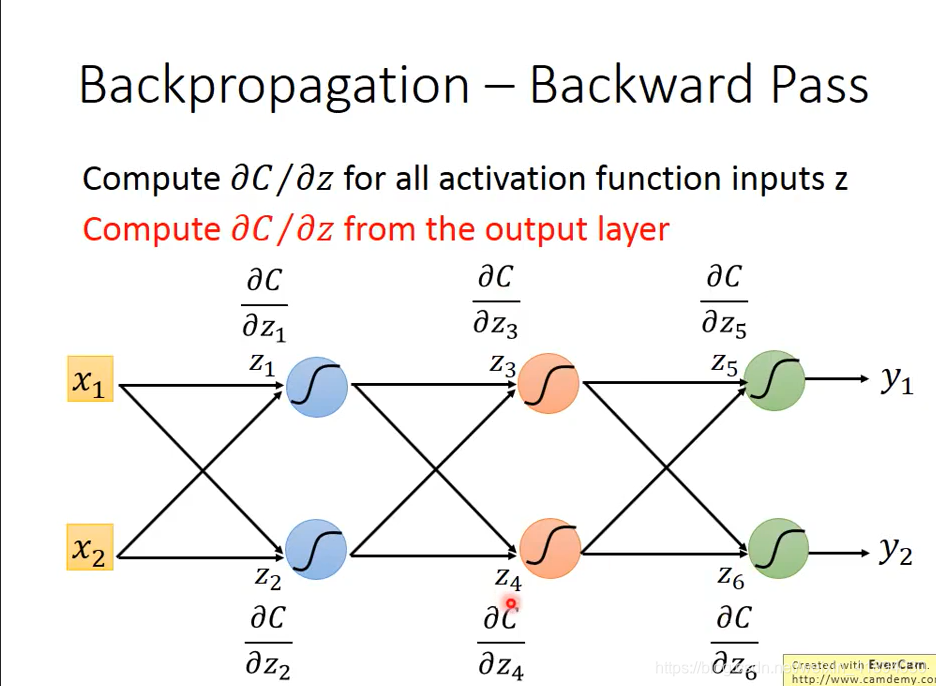
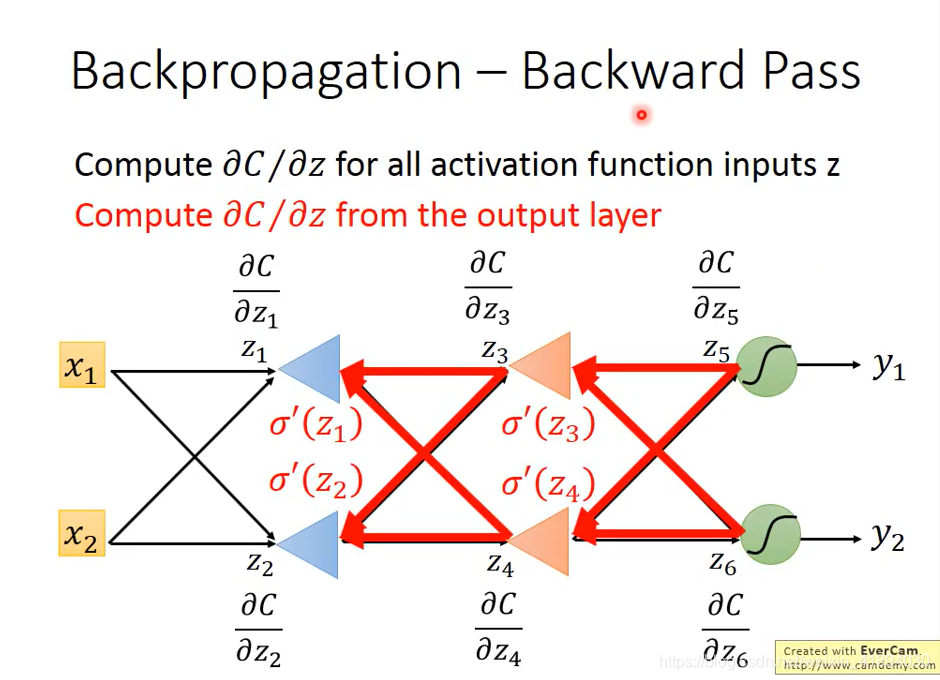
在做反向传播的时候,实际上是建立了另外一个神经网络,正向网络中的激活函数都是sigmoid函数;现在需要建立一个反向的神经网络,在前向传播之后,再计算反向传播的激活函数,反向传播神经网络的输入是
</span><span class="katex-html"><span class="base"><span class="strut" style="height: 1em; vertical-align: -0.25em;"></span><span class="mord" style="margin-right: 0.05556em;">?</span><span class="mord"><span class="mord mathdefault" style="margin-right: 0.07153em;">C</span></span><span class="mord">/</span><span class="mord" style="margin-right: 0.05556em;">?</span><span class="mord"><span class="mord mathdefault" style="margin-right: 0.02691em;">w</span></span></span></span></span></span>是什么了~</p>