文章目录
召回
- 定义:“推荐”其实就是没有检索词输入时的搜索,推荐系统的召回就是要根据用户画像、内容画像等各种信息,为用户提供他感兴趣的相关内容。
- 召回策略:
- 基于内容的召回:将用户画像和内容画像进行匹配,比如用户画像是“杨幂的粉丝”,可以给他推荐杨幂主演的电影;
- 基于知识匹配(升级版):喜欢绣春刀1,根据知识图谱,推荐绣春刀2
- 评价:召回率高,但准确率较低(标签匹配不一定表明用户感兴趣),推荐的内容比较单一,适合冷启动场景;
协同过滤 (collaborative filtering CF)
- 定义:目前业内常用
- 分类:
- 基于用户的协同推荐(userCF):相似的人会有相同的喜好
- 用户相似度计算:余弦相似度、皮尔逊相关系数, etc; 理论上任何合理的相似度计算方法都可以使用(比如考虑不同用户、不同物品的权重)
- 最终结果排序:拿到和当前用户最为相似的top n用户以后,对于某个特定的商品,对top n用户的喜好进行综合评价,进而预测当前用户对该物品的喜好;
- 问题:(1)需要维护用户相似度矩阵以计算出top n用户,而随着用户数大量增长,用户矩阵n^2增长,消耗大量的存储和计算资源;(2)对于历史信息很少的用户,比较难计算到他的相似用户;
- 适用场景:社交属性明确;适用于新闻热点推荐;
- 基于项目的协同推荐(itemCF):喜欢一个物品的用户会喜欢相似的物品,过往的相似记录信息给当前用户推荐
- 计算过程:
- 构建用户m物品n的共现矩阵;计算共现矩阵中两两列向量的相似性,构建物品nn的物品相似度矩阵;获得用户历史行为数据的正反馈物品列表;找出相似物集合top k;相似物集合中的物品进行打分排序,生成最终的推荐列表;
- 适用场景:兴趣变化比较稳定的场景,电商购物,兴趣视频推荐;
- 计算过程:
- 基于模型的协同过滤(model-based):基于样本的用户喜好信息,训练一个推荐模型,然后根据实时的用户喜好的信息进行预测推荐。
- 评价:实际运用中,采用单一召回策略的推荐结果实际会非常粗糙,通用的解决方法是将规则打散,将上述几种召回方式中提炼到的各种细小特征赋予权重,分别打分,并计算总分值,预测CTR(click through rate, 广告系统的推荐点击率)。
- 协同过滤的缺点:头部效应比较明显(热门商品容易被推荐给更多的人),尾部商品由于特征稀疏,很少被推荐。
- 基于用户的协同推荐(userCF):相似的人会有相同的喜好
矩阵分解算法
- 定位:解决协同过滤头部效应的问题
- 步骤:
- 把CF的“共现矩阵” 进行分解,用户m物品n的矩阵被拆分成用户矩阵U(mk)和物品矩阵(kn);计算用户u对于物品i的预估评分;得到一个空间隐向量表示(kk),则空间中相邻的向量对应用户喜欢的物品生成推荐列表;
- 根据真实场景和业务,会加入更多的bias,因而改变了目标函数;
- k值:k是需要反复计算,找到推荐准确度和工程开销的折衷点;k值越大,隐向量表征能力越强,但模型的泛化能力减弱;而且k取值大小和矩阵分解的求解复杂度正相关;
- 矩阵分解算法:
- 特征值分解:只能用于方阵,不适合用户*物品的场景;
- 奇异值分解:要求共现矩阵稠密,而互联网场景下用户-物品的矩阵非常稀疏;计算复杂度O(mn^2),不适合海量商品的场景
- 梯度下降
- 目标函数:U*I逼近原始共现矩阵
- 正则化:避免模型过拟合,减少波动;在模型损失函数的基础上+ lambda*W―模型权重越大,损失函数越大,不是模型的收敛方向,因此良好的收敛方向是 损失函数变小(拟合数据集)+模型权重比较小(输出波动比较小),从而让模型更稳定。
- 梯度下降求得用户矩阵U和物品矩阵I,对某个用户进行推荐时,将该用户的隐向量与所有物品的隐向量求积,得到该用户对所有物品的打分,然后排序得到最终的列表。
- 优点:
- 更强的泛化性:隐向量是用共现矩阵的全局信息生成的;对于协同过滤而言,如果两个人没有相同的历史行为,或者两个物品没有相同的人购买,那么计算的人和物品的相似度都是0;而矩阵分解可以将人对所有物品计算相关度(还是更好的泛化全局信息);
- 空间复杂度低:只需要存储用户和空间隐向量,复杂度由n^2降低为(n+m)*k
- 更好的扩展性和灵活性:矩阵分解产生了用户隐向量和物品隐向量,便于与其他特征进行拼接组合;
- 缺点:
- 不方便加入用户、物品、上下文特征;(CF也是)
- 缺乏用户历史行为;
逻辑回归
- 定位:能够综合用户、物品、上下文等多种特征;将推荐问题转换为分类问题;
- 步骤:
- 用户的年龄、性别、物品属性、描述等转化成特征向量;
- 确定模型的优化目标,比如“点击率”,(CTR, click throgh rate);
- 训练模型,在infer阶段输入特征向量,预测用户对某种物品点击的概率;
- 根据点击概率对候选物品排序,得到推荐列表;
- 优点:
- 数学含义明确:用户是否点击是一个伯努利分布,而逻辑回归符合CTR模型的假设;
- 可解释强:加权+sigmoid
- 工程化简单:易于并行,模型简单,训练开销小;
- 缺点:表达能力不强,无法进行特征交叉、特征筛选等高级操作,因此会造成特征的浪费;
自动特征交叉
POLY
-
定义:对所有特征进行两两交叉,并赋予权重;
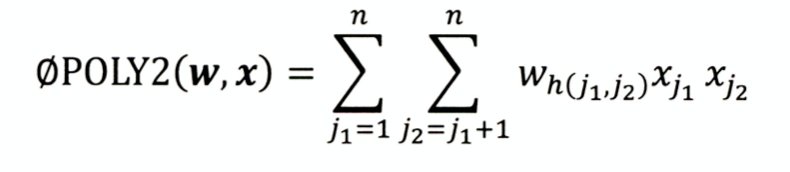
-
缺点:onehot编码的特征本身很稀疏,特征交叉后矩阵更加稀疏,难以训练收敛;权重参数n―n^2,复杂度大大增加;
-
W个数= n*(n-1)/2 ~n^2
FM模型(Factorization Machines,因式分解机)
- 用两个向量内积代替单一权重参数
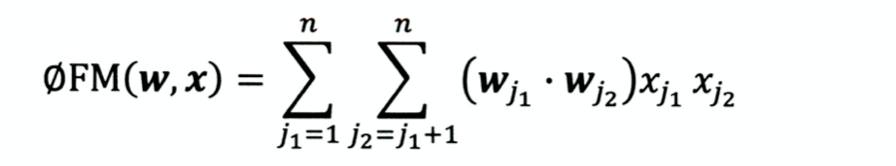
- 权重个数 W=n*k(k是隐向量维度),类似于将共现矩阵分解为说话人矩阵和物品矩阵;
- 优点:更好的解决了矩阵稀疏的问题;泛化能力大大提高;丢失了部分具体特征组合的表示能力;
FFM模型(Field-aware Factorization Machines)
- 定义:引入域(field)的概念,模型的表达能力更强;
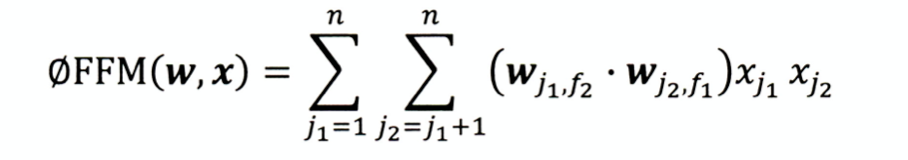

- 复杂度 k n 2 kn^2 kn2




- 由于组合爆炸的问题,三阶FM无论在权重数量和训练复杂度上都非常大,工程难以实现
组合模型
- 定义:解决FM/FFM只能做二阶特征交叉的痛点;
GBDT(Gradient Boosting Decision Tree)梯度提升决策树
- 定义:基本结构是决策树组成的森林,学习方式是梯度提升
- 步骤:
- 利用GBDT进行特征筛选和组合,进而生成新的离散特征;
- 一个样本输入决策树,每个子树最终只会有一个叶子节点置为1,其他都是0;所有子树的特征向量拼接形成后续使用的离散特征向量;
- 特征向量当作LR模型输入,预估CTR

- 利用GBDT进行特征筛选和组合,进而生成新的离散特征;
- 决策树的深度决定了特征交叉的阶数,比如决策树深度为4,则经过三次节点分裂,实际对应三阶特征融合;
- 缺点: 容易过拟合,这种处理方式丢失了大量的特征数值信息,因此交叉能力强不代表着效果好;
- 优点: 特征工程完全交给模型完成,实现真正的end-to-end;是现在embedding层方法的起源;
- 之前的方法:
- 人工/半人工的特征组合和筛选:人力要求高;
- 改进模型结构+增加特征交叉项:模型设计能力门槛;
LS-PLM (Large scale piece-wise linear model)大规模分段线性模型 阿里
-
又叫MLR(mixed logistic regression,混合逻辑回归)
-
做法:先用pai函数对样本进行聚类,再对每个分类进行逻辑回归预测CTR,然后将两者相乘后求和
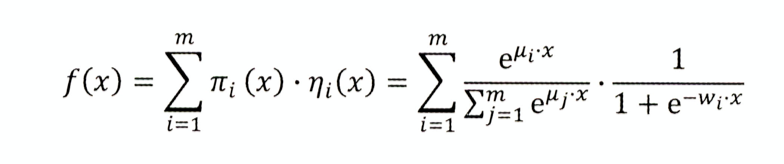
-
分类数m: m=1,退化为基本的LR模型;m越大,模型的拟合能力越强,参数规模也线性增长;

-
优点:
- 端到端的非线性学习能力:样本分片的设计挖掘出数据中存在的非线性模式,节省样本处理时间;端到端的训练模式,可以用一个全局模型对不同领域、业务场景统一建模。
- 模型稀疏能力强:引入L1/L2范数进行稀疏化,使得模型具有较高的稀疏度,模型部署更加轻量级,推断效率也更高;
L1范数比L2范数更容易产生稀疏解
- 损失函数
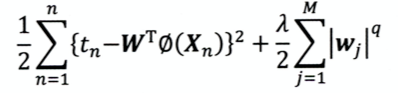
- 令loss=0,绘制曲线

排序
补充策略与算法(再排序)