��Ҫ��3��,��һ������ͨģ�ʹ���,��Ϥyolo v5����������;�ڶ���ѵ���Լ�������;�����½���ģ�Ͳ�������
����Ŀ¼
- һ����ͨģ��
- ����ѵ���Լ�������
- �������ĵIJ����������
- 1.����
- 2.�������
- 2.1--weights
- 2.2--cfg
- 2.3--data
- 2.4--hyp
- 2.5--epochs
- 2.6--batch-size
- 2.7--imgsz
- 2.8--rect
- 2.9--resume
- 2.10--nosave
- 2.11--notest
- 2.12--noautoanchor
- 2.13--evolve
- 2.14--bucket
- 2.15--cache
- 2.16--image-weights
- 2.17--device
- 2.18--multi-scale
- 2.19--single-cls
- 2.20--adam
- 2.21--sync-bn
- 2.22--workers
- 2.23--project
- 2.24--name
- 2.25--exist-ok
- 2.26--quad
- 2.27--linear-lr
- 2.28--label-smoothing
- 2.29--patience
- 2.30--freeze
- 2.31--save-period
- 2.32--local_rank
- 2.33--entity
- 2.34--upload_dataset
- 2.35--bbox_interval
- 2.36--artifact_alias
- �ο�
һ����ͨģ��
1����������
-
YOLOv5 ��Դ������Ŀ���ص�ַ:https://github.com/ultralytics/yolov5
-
yolov5s.pt �����ص�ַ,�ŵ�yolov5-master��Ŀ¼�¼��ɡ�
ps:����ǰ����Ҳ����,�����Զ�����
https://github.com/ultralytics/yolov5/releases/download/v6.0/yolov5s.pt
2����������
conda create -n ���������Զ��塿 python = 3.6
activate ���������Զ��塿
����pytorch����,ѡ���ƶ�Ӧ�汾��pytorch��װ����

conda install pytorch torchvision torchaudio cudatoolkit=10.2 -c pytorch
Ȼ��ȱʲô������ʲô������ˡ�����鿴��Ŀ¼�µ� requirements.txt

3������·������
Դ�����к���û��Ȩ�غ���Ƶ,���û���Զ����صĻ����������ز����浽��Ӧλ��
�ⲿ����Ҫ��Ҫȷ��Ȩ��·����������(ͼ�����Ƶ)·��
��Ƶ�Ļ���Ϊ·����ָ����Ƶ������


�����·��Ҳ��Ҫ��!

����֮ǰ����һ�� Edit Configurations --> ѡ�� detect -->��Parameters ������ --view-img ��ʵʱ�ۿ�������
ps:Ҳ���Բ�����,�˲�����Թ�


3������detect.py�ļ�
ѵ����������ڸ�Ŀ¼�µ�run�ļ��в鿴�����


����ѵ���Լ�������
1.������
1.1�����������ͱ�ǩ
-
���ݱ�ǩ��ʽ

-
�õ��Ĺ���:labelImg
a.��װlabelImg
pip install labelImg
b.ѡ���ļ�·����ѡ��·����ѡ��yoloģʽ������ View��ѡ�� �Զ�����ģʽ

2��·����������
2.1�������ݶ�ȡ·����
# �½��ļ��� #
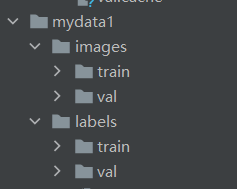
�ļ��������Զ���,��mydata1,�������ļ��а����¸�ʽ����
mydata1���ļ�Ŀ¼����,�ֱ�ǰ�����õġ�ѵ���������ŵ�images�µ�train,�������������ŵ�images�µ�val;��ѵ����ǩ���C> labes�µ�train,�����Ա�ǩ���C> labels�µ�val
2.2�½����������ļ�.yaml
- �ڸ�Ŀ¼data���½�xxx.yaml�ļ�

- ����ճ��������������,·���Զ���Ϊ������·��,������������Զ��岢��0��1��2��3��Ӧ����

2.3��train.py�ļ��е�data·������
ָ���Լ�������xxx.yaml�ļ�·��

3����������
�������ֶ��dz���ѵ��ʱ���ÿ��ĵ�,�������ݿ�����Ľ���
parser.add_argument(���Cweights��, type=str, default=ROOT / 'yolov5s.pt��, help=��initial weights path��) #ѡ��Ԥѵ��Ȩ��ģ��,��defaultΪ�����ó����Դ���ʼȨ��
parser.add_argument(���Ccfg��, type=str, default=��yolov5s.yaml��, help=��model.yaml path��) #ѡ��������ģ��
parser.add_argument(���Cdata��, type=str, default=ROOT / ��data/mydata.yaml��, help=��dataset.yaml path��) #��������·��,���뵽mydata.yaml�ļ�������
parser.add_argument(���Chyp��, type=str, default=ROOT / ��data/hyps/hyp.scratch.yaml��, help=��hyperparameters path��) #������:������˥���ʵȡ�һ���ò���
parser.add_argument(���Cepochs��, type=int, default=400) #ѵ������,�趨epoch����
parser.add_argument(���Cbatch-size��, type=int, default=32, help=��total batch size for all GPUs, -1 for autobatch��) #ÿ���ε�������,default=-1ʱ�Զ����ڴ�С
parser.add_argument(���Cimgsz��, ���Cimg��, ���Cimg-size��, type=int, default=640, help=��train, val image size (pixels)��)#ѵ�����Ͳ��Լ�ͼƬ�����ش�С,640*640
parser.add_argument(���Cdevice��, default=����, help=��cuda device, i.e. 0 or 0,1,2,3 or cpu��) #������������ pytorch ��ܵ�ʹ���豸,���� GPU cuda,���� cpu
parser.add_argument(���Cworkers��, type=int, default=0, help=��max dataloader workers (per RANK in DDP mode)��) #���߳�:���ィ�� default ����Ϊ 0��
parser.add_argument(���Cproject��, default=ROOT / ��runs/train��, help=��save to project/name��) #����ָ��ѵ���õ�ģ�͵ı���·����
parser.add_argument(���Cfreeze��, type=int, default=24, help=��Number of layers to freeze. backbone=10, all=24��) #�����������
4��train.py
����train.pyѵ������
ѵ����������ڸ�Ŀ¼������һ��run�ļ���,������ѵ�������Ȩ��

�������ĵIJ����������
1.����
�������ִ�������:
'''*****************��������*****************'''
def parse_opt(known=False):
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s.pt', help='initial weights path') #ѡ��Ԥѵ��Ȩ��ģ��,��defaultΪ�����ó����Դ���ʼȨ��
# parser.add_argument('--weights', type=str, default='', help='initial weights path')
# parser.add_argument('--cfg', type=str, default='', help='model.yaml path') #ѡ��������ģ��
parser.add_argument('--cfg', type=str, default='yolov5s.yaml', help='model.yaml path')
parser.add_argument('--data', type=str, default=ROOT / 'data/mydata.yaml', help='dataset.yaml path') #��������·��,���뵽mydata.yaml�ļ�������
parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch.yaml', help='hyperparameters path') #������:������˥���ʵȡ�һ���ò���
# parser.add_argument('--epochs', type=int, default=300)
parser.add_argument('--epochs', type=int, default=400) #ѵ������,�趨epoch����
parser.add_argument('--batch-size', type=int, default=32, help='total batch size for all GPUs, -1 for autobatch') #ÿ���ε�������,default=-1ʱ�Զ����ڴ�С
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='train, val image size (pixels)')#ѵ�����Ͳ��Լ�ͼƬ�����ش�С,640*640
parser.add_argument('--rect', action='store_true', help='rectangular training') #��ȥһЩ����Ҫ��Ϣ,����ģ����������
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training') #�����ѵ����һ��ģ�ͻ����ϼ���ѵ��
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint') #��Ч��ֻ�������һ�� pt �ļ�
parser.add_argument('--noval', action='store_true', help='only validate final epoch') #��Ч��ֻ�����һ�β���
parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')
parser.add_argument('--evolve', type=int, nargs='?', const=300, help='evolve hyperparameters for x generations') #��x�������������Ż�
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache', type=str, nargs='?', const='ram', help='--cache images in "ram" (default) or "disk"') #����ͼƬ���л���,�Ա���õؽ���ѵ��
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training') #������Щѵ�����õ�ͼƬ,������һ��������һЩȨ�ء�
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu') #������������ pytorch ��ܵ�ʹ���豸,���� GPU cuda,���� cpu
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%') #��ͼƬ�߶Ƚ��б任
parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class') # �����趨ѵ�����ݼ��ǵ�����Ƕ����Ĭ��Ϊ false,��ζ���Ƕ��
parser.add_argument('--adam', action='store_true', help='use torch.optim.Adam() optimizer') #�Ż���:���뵽 Edit Configuration --> Parameters
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode') #���ж� GPU ���зֲ�ʽѵ����
# parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)')
parser.add_argument('--workers', type=int, default=0, help='max dataloader workers (per RANK in DDP mode)') #���߳�:���ィ�� default ����Ϊ 0��
parser.add_argument('--project', default=ROOT / 'runs/train', help='save to project/name') #����ָ��ѵ���õ�ģ�͵ı���·����
parser.add_argument('--name', default='exp', help='save to project/name') # �����趨�����ģ���ļ�����
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment') #�����趨Ԥ�����ı������λ�������
parser.add_argument('--quad', action='store_true', help='quad dataloader') #quad ���ݼ��ص��������
parser.add_argument('--linear-lr', action='store_true', help='linear LR') #ѧϰ�ʷ�ʽ����
parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon') #ƽ��������ֹ�����
parser.add_argument('--patience', type=int, default=100, help='EarlyStopping patience (epochs without improvement)') #��epochû����������ǰ����
parser.add_argument('--freeze', type=int, default=24, help='Number of layers to freeze. backbone=10, all=24') #�����������
parser.add_argument('--save-period', type=int, default=-1, help='Save checkpoint every x epochs (disabled if < 1)') #���ڼ�¼ѵ����־��Ϣ,int ��,Ĭ��Ϊ -1��
parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify') #DistributedDataParallel �����ѵ��,һ�㲻�Ķ���
# Weights & Biases arguments #wandb���ӻ���һЩ����
parser.add_argument('--entity', default=None, help='W&B: Entity')
parser.add_argument('--upload_dataset', action='store_true', help='W&B: Upload dataset as artifact table')
parser.add_argument('--bbox_interval', type=int, default=-1, help='W&B: Set bounding-box image logging interval')
parser.add_argument('--artifact_alias', type=str, default='latest', help='W&B: Version of dataset artifact to use') #������,��ע�͵�
opt = parser.parse_known_args()[0] if known else parser.parse_args()
return opt
2.�������
2.1�Cweights
parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s.pt', help='initial weights path')
ѡ��Ԥѵ��Ȩ��ģ��,��defaultΪ�����ó����Դ���ʼȨ��
2.2�Ccfg
parser.add_argument('--cfg', type=str, default='yolov5s.yaml', help='model.yaml path')
ѡ��������ģ��,defaultΪ�� 'ʱʹ�ó����Դ�ģ��
2.3�Cdata
parser.add_argument('--data', type=str, default=ROOT / 'data/mydata.yaml', help='dataset.yaml path')
��������·��,���뵽mydata.yaml�ļ�������
2.4�Chyp
parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch.yaml', help='hyperparameters path')
������:������˥���ʡ�box���õȵ�,һ��������ò���
2.5�Cepochs
parser.add_argument('--epochs', type=int, default=400)
ѵ��������:ѵ������,�趨epoch������Դ���� default ֵΪ 300,ѵ���ִ�����ʾΪ 0~299
2.6�Cbatch-size
parser.add_argument('--batch-size', type=int, default=32, help='total batch size for all GPUs, -1 for autobatch')
ÿ����·�����������:ÿ���ε�����������,default=-1ʱ�Զ����ڴ�С
2.7�Cimgsz
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='train, val image size (pixels)')
ͼƬ��С:ѵ�����Ͳ��Լ�ͼƬ�����ش�С,����Ĭ��640*640
2.8�Crect
parser.add_argument('--rect', action='store_true', help='rectangular training')
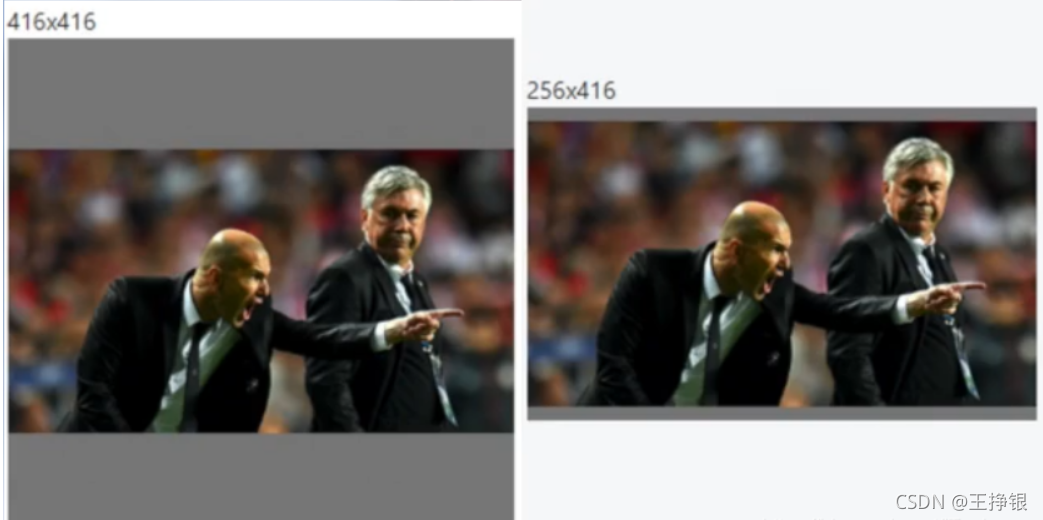
���þ����ѵ����ʽ:�����Ǽ�ȥһЩ����Ҫ��Ϣ,����ģ���������̡�
2.9�Cresume
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
�Ƿ������ѵ����һ��ģ�ͻ����ϼ���ѵ��:default ֵĬ���� false,����Ҫ default Ϊ true ʱ����ָ�����ĸ�ģ���ϼ���ѵ����ָ����ģ��·�����ַ�����ʽ��ֵ�� default��
2.10�Cnosave
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
ֻ�������һ�� pt �ļ�
2.11�Cnotest
parser.add_argument('--noval', action='store_true', help='only validate final epoch')
��Ч��ֻ�����һ�ν��в��ԡ�
�����������������������뵽 Edit Configuration --> Parameters ��,���ж�����������,�м��ÿո�������ɡ�


2.12�Cnoautoanchor
parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')
����������Ŀ�����������Ƿ����ê�� / ê��
��������ͼ�������п��ܵ����ؿ�,Ȼ��ѡ����ȷ��Ŀ���,����λ�úʹ�С���е����Ϳ������Ŀ��������
Ĭ�Ͽ���,�����ַ�ʽ����ģ��ѵ�����̡�
2.13�Cevolve
parser.add_argument('--evolve', type=int, nargs='?', const=300, help='evolve hyperparameters for x generations')
��x�������������Ż���
������Ѱ�����ų������ķ�ʽ,�����������Ŵ��㷨�Զ�������������
Ĭ�˲�����
2.14�Cbucket
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
��������� yolov5 ���߽�һЩ�������ڹȸ�����,���Խ������ء�
2.15�Ccache
parser.add_argument('--cache', type=str, nargs='?', const='ram', help='--cache images in "ram" (default) or "disk"')
��Ч��ͼƬ���л���,�Ա���õؽ���ѵ����
2.16�Cimage-weights
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
��Ч�������Щѵ�����õ�ͼƬ,������һ��������һЩȨ�ء�
2.17�Cdevice
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
������������ pytorch ��ܵ�ʹ���豸,���� GPU cuda,���� cpu
2.18�Cmulti-scale
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
��ͼƬ�߶Ƚ��б任
2.19�Csingle-cls
parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
�����趨ѵ�����ݼ��ǵ�����Ƕ����
Ĭ��Ϊ false,��ζ���Ƕ����
2.20�Cadam
parser.add_argument('--adam', action='store_true', help='use torch.optim.Adam() optimizer')
�Ż���:���뵽 Edit Configuration --> Parameters �м�Ϊ true ,��ζ��Ҫ�ô��Ż���;����Ϊ false,Ϊ false ʱ�õ�������ݶ��½�(SGD)�Ż��㷨��
2.21�Csync-bn
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
���ж� GPU ���зֲ�ʽѵ����
2.22�Cworkers
parser.add_argument('--workers', type=int, default=0, help='max dataloader workers (per RANK in DDP mode)')
���߳�:���ィ�� default ����Ϊ 0��
2.23�Cproject
parser.add_argument('--project', default=ROOT / 'runs/train', help='save to project/name')
����ָ��ѵ���õ�ģ�͵ı���·����
2.24�Cname
parser.add_argument('--name', default='exp', help='save to project/name')
�����趨�����ģ���ļ�����
2.25�Cexist-ok
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
�����趨Ԥ�����ı������λ�������
������ʱΪ true,�� name ָ���ļ����±���,Դ���б����� exp �ļ�����
��������ʱΪ false,�����������ļ����±��档
2.26�Cquad
parser.add_argument('--quad', action='store_true', help='quad dataloader')
����Ϊ quad ���ݼ��ص�������á�
������,��Ч������ڱ�ǰ�� ���Cimg-size�� �������õ�ѵ���������ݼ���������ݼ���ѵ����
- �ô����ڱ�Ĭ�� 640 ������ݼ���ѵ��Ч������
- ���������� 640 ��С�����ݼ���ѵ��Ч�����ܻ��һЩ
2.27�Clinear-lr
parser.add_argument('--linear-lr', action='store_true', help='linear LR')
���ڶ�ѧϰ���ʽ��е���
Ĭ��Ϊ false,������ͨ�����Һ���������ѧϰ�ʡ�
ע:������ʹ���ݶ��½��㷨���Ż�Ŀ�꺯����ʱ��,��Խ��Խ�ӽ�Lossֵ��ȫ����Сֵʱ,ѧϰ��Ӧ�ñ�ø�С��ʹ��ģ�;����ܽӽ���һ��,�������˻�(Cosine
annealing)����ͨ�����Һ���������ѧϰ�ʡ�
2.28�Clabel-smoothing
parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
���ڶԱ�ǩ����ƽ��������
�����Ƿ�ֹ�ڷ����㷨�й��������IJ�����
2.29�Cpatience
parser.add_argument('--patience', type=int, default=100, help='EarlyStopping patience (epochs without improvement)')
��ǰ����:��epochû����������ǰ����
2.30�Cfreeze
parser.add_argument('--freeze', type=int, default=24, help='Number of layers to freeze. backbone=10, all=24')
�����:���ʵ����ٶ������
2.31�Csave-period
parser.add_argument('--save-period', type=int, default=-1, help='Save checkpoint every x epochs (disabled if < 1)')
���ڼ�¼ѵ����־��Ϣ,int ��,Ĭ��Ϊ -1��
2.32�Clocal_rank
parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')
DistributedDataParallel �����ѵ��,һ�㲻�Ķ���
2.33�Centity
parser.add_argument('--entity', default=None, help='W&B: Entity')
�� wandb ����صIJ�������,���ò���,���ԡ�
2.34�Cupload_dataset
parser.add_argument('--upload_dataset', action='store_true', help='W&B: Upload dataset as artifact table')
wandb ���Ӧ�Ķ���,���ò���,���ؿ��ǡ�
2.35�Cbbox_interval
parser.add_argument('--bbox_interval', type=int, default=-1, help='W&B: Set bounding-box image logging interval')
�� wandb ����صIJ�������,���ò���,���ԡ�
2.36�Cartifact_alias
parser.add_argument('--artifact_alias', type=str, default='latest', help='W&B: Version of dataset artifact to use')
��һ�в������������ʵ�ֵ���δʵ�ֵ�һ������,���Լ��ɡ��ײ�ע�͵���������Ҳ�����С�
�ο�
https://blog.csdn.net/IT_charge/article/details/119177578