ОэЛ§ЩёОЭјТчжаnn.Conv2d()КЭnn.MaxPool2d()
ОэЛ§ЩёОЭјТчжЎPythorchЪЕЯж:
nn.Conv2d()ОЭЪЧPyTorchжаЕФОэЛ§ФЃПщ
ВЮЪ§СаБэ
| ВЮЪ§ | зїгУ |
|---|---|
| in_channels | ЪфШыЪ§ОнЬхЕФЩюЖШ |
| out_channels | ЪфГіЪ§ ОнЬхЕФЩюЖШ |
| kernel_size | ТЫВЈЦї(ОэЛ§КЫ)ЕФДѓаЁ зЂ1 |
| stride | ЛЌЖЏЕФВНГЄ |
| padding | СуЬюГфЕФШІЪ§ зЂ2 |
| bias | ЪЧЗёЦєгУЦЋжУ,ФЌШЯЪЧTrue,ДњБэЦєгУ |
| groups | ЪфГіЪ§ОнЬхЩюЖШЩЯКЭЪфШыЪ§ ОнЬхЩюЖШЩЯЕФСЊЯЕ зЂ3 |
| dilation | ОэЛ§ЖдгкЪфШыЪ§ОнЬхЕФПеМфМфИє зЂ4 |
зЂ:1. ПЩвдЪЙгУвЛ ИіЪ§зжРДБэЪОИпКЭПэЯрЭЌЕФОэЛ§КЫ,БШШч kernel_size=3,вВПЩвдЪЙгУ ВЛЭЌЕФЪ§зжРДБэЪОИпКЭПэВЛЭЌЕФОэЛ§КЫ,БШШч kernel_size=(3, 2);
-
padding=0БэЪОЫФжмВЛНјааСуЬюГф,Жј padding=1БэЪОЫФжмНјаа1ИіЯёЫиЕуЕФСуЬюГф;
-
groupsБэЪОЪфГіЪ§ОнЬхЩюЖШЩЯКЭЪфШыЪ§ ОнЬхЩюЖШЩЯЕФСЊЯЕ,ФЌШЯ groups=1,вВОЭЪЧЫљгаЕФЪфГіКЭЪфШыЖМЪЧЯр ЙиСЊЕФ,ШчЙћ groups=2,етБэЪОЪфШыЕФЩюЖШБЛЗжИюГЩСНЗн,ЪфГіЕФЩю ЖШвВБЛЗжИюГЩСНЗн,ЫќУЧжЎМфЗжБ№ЖдгІЦ№РД,ЫљвдвЊЧѓЪфГіКЭЪфШыЖМ БиаывЊФмБЛ groupsећГ§ЁЃ
-
ФЌШЯdilation=1ЯъЧщМћ nn.Conv2d()жаdilationВЮЪ§ЕФзїгУЛђепCSDN
nn.MaxPool2d()БэЪОЭјТчжаЕФзюДѓжЕГиЛЏ
ВЮЪ§СаБэ:
| ВЮЪ§ | зїгУ |
|---|---|
| kernel_size | гыЩЯУцnn.Conv2d()ЯрЭЌ |
| stride | гыЩЯУцnn.Conv2d()ЯрЭЌ |
| padding | гыЩЯУцnn.Conv2d()ЯрЭЌ |
| dilation | гыЩЯУцnn.Conv2d()ЯрЭЌ |
| return_indices | БэЪОЪЧЗёЗЕЛизюДѓжЕЫљДІЕФЯТБъ,ФЌШЯ return_indices=False |
| ceil_mode | БэЪОЪЙгУвЛаЉЗНИёДњЬцВуНсЙЙ,ФЌШЯ ceil_mode=False |
зЂ:вЛАуВЛЛсШЅЩшжУreturn_indicesКЭceil_modeВЮЪ§
import torch.nn as nn
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
layer1 = nn.Sequential()
# АбвЛИіШ§ЭЈЕРЕФееЦЌRGBШ§ИіЪЙгУ32зщОэЛ§КЫОэЛ§,УПзщШ§ИіОэЛ§КЫ,зщФкОэЛ§КѓЯрМгЕУГі32зщЪфГі
layer1.add_module('conv1', nn.Conv2d(3, 32, (3, 3), (1, 1), padding=1))
layer1.add_module('relu1', nn.ReLU(True))
layer1.add_module('pool1', nn.MaxPool2d(2, 2))
self.layer1 = layer1
layer2 = nn.Sequential()
layer2.add_module('conv2', nn.Conv2d(32, 64, (3, 3), (1, 1), padding=1))
layer2.add_module('relu2', nn.ReLU(True))
layer2.add_module('pool2', nn.MaxPool2d(2, 2))
self.layer2 = layer2
layer3 = nn.Sequential()
layer3.add_module('conv3', nn.Conv2d(64, 128, (3, 3), (1, 1), padding=1))
layer3.add_module('relu3', nn.ReLU(True))
layer3.add_module('pool3', nn.MaxPool2d(2, 2))
self.layer3 = layer3
layer4 = nn.Sequential()
layer4.add_module('fc1', nn.Linear(2048, 512))
layer4.add_module('fc_relu1', nn.ReLU(True))
layer4.add_module('fc2', nn.Linear(512, 64))
layer4.add_module('fc_relu2', nn.ReLU(True))
layer4.add_module('f3', nn.Linear(64, 10))
self.layer4 = layer4
def forward(self, x):
conv1 = self.layer1(x)
conv2 = self.layer2(conv1)
conv3 = self.layer3(conv2)
fc_input = conv3.view(conv3.size(0), -1)
fc_out = self.layer4(fc_input)
return fc_out
model = SimpleCNN()
print(model)
ЪфГі
SimpleCNN(
(layer1): Sequential(
(conv1): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(relu1): ReLU(inplace=True)
(pool1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(layer2): Sequential(
(conv2): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1))
(relu2): ReLU(inplace=True)
(pool2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(layer3): Sequential(
(conv3): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(relu3): ReLU(inplace=True)
(pool3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(layer4): Sequential(
(fc1): Linear(in_features=2048, out_features=512, bias=True)
(fc_relu1): ReLU(inplace=True)
(fc2): Linear(in_features=512, out_features=64, bias=True)
(fc_relu2): ReLU(inplace=True)
(f3): Linear(in_features=64, out_features=10, bias=True)
)
)
ЬсШЁФЃаЭЕФВуМЖНсЙЙ
ЬсШЁВуМЖНсЙЙПЩвдЪЙгУвдЯТМИИіnn.ModelЕФЪєад,ЕквЛИіЪЧchildren()Ъєад,ЫќЛсЗЕЛиЯТвЛМЖФЃПщЕФЕќДњЦї,дкЩЯУцетИіФЃаЭжа,ЫќЛсЗЕЛидкself.layer1,self.layer2,self.layer4ЩЯЕФЕќДњЦїЖјВЛЛсЗЕЛиЫќУЧФкВПЕФЖЋЮї;modules()
ЛсЗЕЛиФЃаЭжаЫљгаЕФФЃПщЕФЕќДњЦї,етбљЫќОЭФмЗУЮЪЕНзюФкВу,БШШчself.layer1.conv1етИіФЃПщ;ЛЙгавЛИігыЫќУЧЯрЖдгІЕФЪЧname_children()ЪєадвдМАnamed_modules(),етСНИіВЛНіЛсЗЕЛиФЃПщЕФЕќДњЦї,ЛЙЛсЗЕЛиЭјТчВуЕФУћзжЁЃ
ЬсШЁГіmodelжаЕФЧАСНВу
nn.Sequential(*list(model.children())[:2])
ЪфГі:
Sequential(
(0): Sequential(
(conv1): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(relu1): ReLU(inplace=True)
(pool1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(1): Sequential(
(conv2): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(relu2): ReLU(inplace=True)
(pool2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
)
ЬсШЁГіmodelжаЕФЫљгаОэЛ§Ву
conv_model = nn.Sequential()
for layer in model.named_modules():
if isinstance(layer[1], nn.Conv2d):
conv_model.add_module(layer[0].split('.')[1] ,layer[1])
print(conv_model)
ЪфГі:
Sequential(
(conv1): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv2): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv3): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
ЬсШЁЭјТчВЮЪ§ВЂЖдЦфГѕЪМЛЏ
nn.MoudelРяУцгаСНИіЬиБ№живЊЕФЙигкВЮЪ§ЕФЪєад,ЗжБ№ЪЧnamed_parameters()КЭparameters()ЁЃЧАепЛсЪфГіЭјТчВуЕФУћзжКЭВЮЪ§ЕФЕќДњЦї,КѓепЛсИјГівЛИіЭјТчЕФШЋВПВЮЪ§ЕФЕќДњЦїЁЃ
for param in model.named_parameters():
print(param[0])
# print(param[1])
ЪфГі:
layer1.conv1.weight
layer1.conv1.bias
layer2.conv2.weight
layer2.conv2.bias
layer3.conv3.weight
layer3.conv3.bias
layer4.fc1.weight
layer4.fc1.bias
layer4.fc2.weight
layer4.fc2.bias
layer4.f3.weight
layer4.f3.bias
АИР§:ЪЙгУОэЛ§ЩёОЭјТчЪЕЯжЖдMinistЪ§ОнМЏЕФдЄВт
import matplotlib.pyplot as plt
import torch.utils.data
import torchvision.datasets
import os
import torch.nn as nn
from torchvision import transforms
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=(3, 3)),
nn.BatchNorm2d(16),
nn.ReLU(inplace=True),
)
self.layer2 = nn.Sequential(
nn.Conv2d(16, 32, kernel_size=(3, 3)),
nn.BatchNorm2d(32),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.layer3 = nn.Sequential(
nn.Conv2d(32, 64, kernel_size=(3, 3)),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True)
)
self.layer4 = nn.Sequential(
nn.Conv2d(64, 128, kernel_size=(3, 3)),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.fc = nn.Sequential(
nn.Linear(128 * 4 * 4, 1024),
nn.ReLU(inplace=True),
nn.Linear(1024, 128),
nn.Linear(128, 10)
)
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
data_tf = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize([0.5], [0.5])]
)
train_dataset = torchvision.datasets.MNIST(root='F:/ЛњЦїбЇЯА/pytorch/Ъщ/data/mnist', train=True,
transform=data_tf, download=True)
test_dataset = torchvision.datasets.MNIST(root='F:/ЛњЦїбЇЯА/pytorch/Ъщ/data/mnist', train=False,
transform=data_tf, download=True)
batch_size = 100
train_loader = torch.utils.data.DataLoader(
dataset=train_dataset, batch_size=batch_size
)
test_loader = torch.utils.data.DataLoader(
dataset=test_dataset, batch_size=batch_size
)
model = CNN()
model = model.cuda()
criterion = nn.CrossEntropyLoss()
criterion = criterion.cuda()
optimizer = torch.optim.Adam(model.parameters())
# НкдМЪБМф,Ш§ДЮЙЛСЫ
iter_step = 3
loss1 = []
loss2 = []
for step in range(iter_step):
loss1_count = 0
loss2_count = 0
for images, labels in train_loader:
images = images.cuda()
labels = labels.cuda()
images = images.reshape(-1, 1, 28, 28)
output = model(images)
pred = output.squeeze()
optimizer.zero_grad()
loss = criterion(pred, labels)
loss.backward()
optimizer.step()
_, pred = torch.max(pred, 1)
loss1_count += int(torch.sum(pred == labels)) / 100
# ВтЪд
else:
test_loss = 0
accuracy = 0
with torch.no_grad():
for images, labels in test_loader:
images = images.cuda()
labels = labels.cuda()
pred = model(images.reshape(-1, 1, 28, 28))
_, pred = torch.max(pred, 1)
loss2_count += int(torch.sum(pred == labels)) / 100
loss1.append(loss1_count / len(train_loader))
loss2.append(loss2_count / len(test_loader))
print(f'Ек{step}ДЮбЕСЗ:бЕСЗзМШЗТЪ:{loss1[len(loss1)-1]},ВтЪдзМШЗТЪ:{loss2[len(loss2)-1]}')
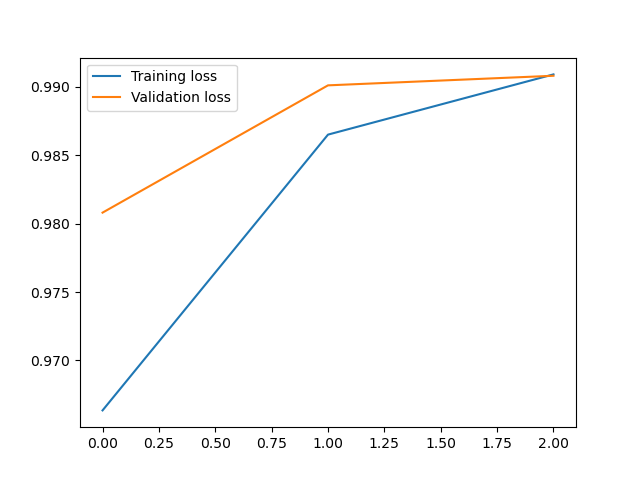
plt.plot(loss1, label='Training loss')
plt.plot(loss2, label='Validation loss')
plt.legend()
ЪфГі:
Ек0ДЮбЕСЗ:бЕСЗзМШЗТЪ:0.9646166666666718,ВтЪдзМШЗТЪ:0.9868999999999996
Ек1ДЮбЕСЗ:бЕСЗзМШЗТЪ:0.9865833333333389,ВтЪдзМШЗТЪ:0.9908999999999998
Ек2ДЮбЕСЗ:бЕСЗзМШЗТЪ:0.9917000000000039,ВтЪдзМШЗТЪ:0.9879999999999994
<matplotlib.legend.Legend at 0x21f03092fd0>