跨模态广义蒸馏的文本-视频检索
摘要
近年来,通过对视频和音频数据集进行大规模的预训练来构建强大的视频编码器,文本视频检索的任务取得了长足的进展。相比之下,尽管存在自然对称性,但开发大规模语言预训练的有效算法的设计仍有待探索。在这项工作中,我们首先研究了此类算法的设计,并提出了一种新的广义提取方法TEACHTEXT,该方法利用来自多个文本编码器的互补线索为检索模型提供增强的监控信号。此外,我们将我们的方法扩展到视频端模式,并表明我们可以在不影响性能的情况下有效地减少测试时使用的模式数量。我们的方法大大提高了几种视频检索基准的技术水平,并且在测试时不增加计算开销。最后,我们展示了我们的方法在从检索数据集中消除噪声方面的有效应用。
介绍
这项工作的重点是文本-视频检索,即在候选视频池中识别哪一个视频最匹配描述其内容的自然语言查询。
最近提出的检索方法的一个中心主题是研究如何最好地使用多种视频模式来提高性能。特别是,基于专家[36,42]和多模 transformers[20]混合的体系结构显示了在相关任务(如图像分类、动作识别和环境声音分类)中使用不同的预训练模型集作为训练和测试期间视频编码基础的好处。
在这项工作中,我们探讨了是否可以通过利用在大规模书面语料库上学习到的多种文本嵌入来获得相应的收益。与使用多种模式和预训练任务的视频嵌入不同,文本嵌入集合之间存在足够的多样性以实现有意义的性能提升并不明显。事实上,我们的灵感来源于对一系列检索基准中不同文本嵌入性能的仔细调查(图2)。引人注目的是,我们不仅观察到文本嵌入的性能差异很大,而且它们的排名也不一致,这有力地支持了使用多个文本嵌入的想法。
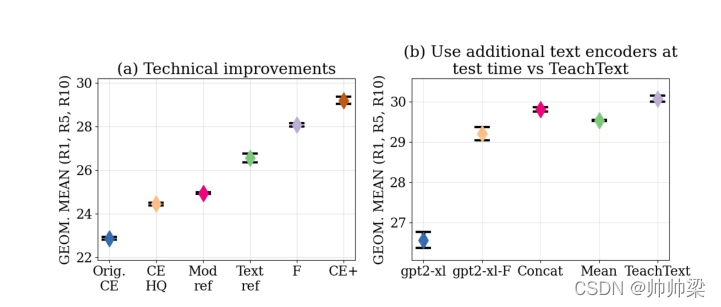
基于这一发现,我们提出了一个简单的算法TEACHTEXT,以有效地利用由文本嵌入集合捕获的知识。我们的方法需要一个“学生”模型从一个或多个“教师”检索模型中学习,通过将其文本-视频相似性矩阵提取为增强的监控信号来访问不同的文本嵌入。如图1所示,TeachText能够提供显著的性能增益。此外,该增益与向视频编码器添加更多视频模式的增益是互补的,但重要的是,与添加视频模式不同,在推断期间不会产生额外的计算成本。
我们的主要贡献可以总结如下:
(1)我们提出了teachtext算法,它利用了使用多个文本编码器提供的额外信息;
(2)我们证明了直接学习联合查询视频嵌入之间的检索相似矩阵是一种有效的广义蒸馏技术,
就我们的知识而言,这是一种新颖的方法(并将我们的方法与之前的工作进行了比较,如单模关系蒸馏[47]);
(3)在文本-视频检索任务中,应用该方法消除现代训练数据中的噪声;
(4)通过实验验证了该方法的有效性,在6个文本-视频检索基准上取得了良好的性能。
动机
我们观察到,数据集内部和数据集之间都存在显著差异,这表明每个嵌入捕获不同类型的信息。我们的直觉是,这些信息来自不同的体系结构、预培训数据集和预培训目标,它们在文本嵌入中有所不同。
文本嵌入集合展示
接下来,我们将详细介绍所使用的文本嵌入,并根据我们的发现总结它们之间的主要差异。Word2vec(w2v)[44]是一种轻量级文本嵌入,广泛用于视觉任务[11,35,68]。多任务GrOVLE(mtgrovle)[8]是w2v的一个扩展,专门为视觉语言任务设计(但是,在我们的实验中,我们发现它的性能略低于w2v)。精细调整的transformer语言模型(openai gpt)[50]嵌入是在包含大量连续文本的图书语料库上进行训练的。我们观察到,它在具有较长文本查询的数据集(如ActivityNet)上表现良好。RoBERTa和ALBERT[33,37]基于BERT架构[16],并根据相同的数据进行培训,这些数据包括未出版的书籍和维基百科文章。RoBERTa[37]专注于超参数优化,并表明模型容量越大,性能越好,而ALBERT[33]提出了一些参数缩减技术,以减少内存消耗并提高训练速度。在我们的实验中,我们观察到在比较两者时,性能有很大的变化。与其他嵌入不同,gpt2[51]是在设计为尽可能多样化的爬网数据集上进行训练的。我们观察到gpt2在我们的实验中表现最为强劲,尤其是在较小的数据集上,如MSR-VTT和MSVD。然而,它与每个语料库之间仍存在一个领域差距(突出的是,在对文本视频检索数据集的查询进行微调时,gpt2 xl(本文通篇称为gpt2-xl-F)的性能会提高)。
方法
TEACHTEXTteacher-student框架概述:
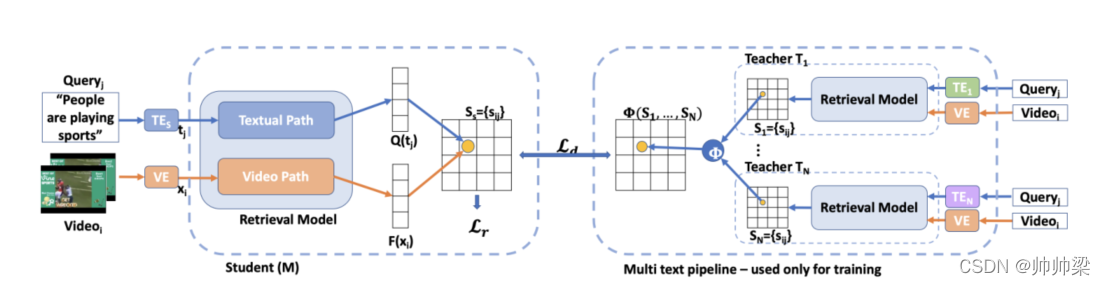
在训练过程中,给定一批输入视频和自然语言查询,学生模型M(左)和教师模型st1,…, TN(右)每个产生相似矩阵(可视化为正方形网格)。
除检索损失外,还通过蒸馏损失鼓励生成的相似矩阵与教师的聚合矩阵相匹配,注意,学生和老师使用相同的视频嵌入(VE),但使用不同的文本嵌入(TE).
方法:
采用多模态专家方法,对于每个视频,我们都可以访问一个视频嵌入集合(有时被称为“专家”) x i x_i xi?,除了每个标题/查询 c i c_i ci?的文本嵌入 t i t_i ti?(使用一个文本编码器,TE)提取的文本外,还使用预训练的视频编码器(VE)从各种形式的视频 v i v_i vi?中提取。
文本-视频检索任务的目标是学习一个模型 m ( x i , t j ) m (x_i, t_j) m(xi?,tj?),该模型m对对应的(即 i = j i=j i=j)视频和文本嵌入的配对 ( x i , t j ) (x_i, t_j) (xi?,tj?)赋高相似度值,否则赋低相似度值。
我们将模型参数化为在共享空间中产生联合嵌入的双编码器,,这样它们就可以直接进行比较。
为了训练视频和文本编码器的检索任务,我们采用了对比损失。
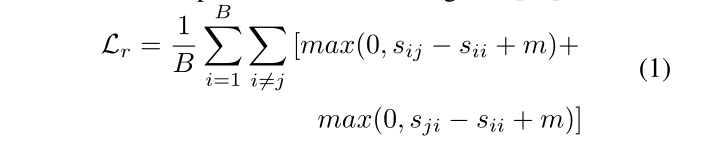
我们方法背后的关键思想是学习一个检索模型M,该模型除了上面描述的损失之外,还可以访问由一组预先训练的“教师”检索模型提供的信息,这些模型是在相同的任务上训练的,但吸收了不同的文本嵌入。
TEACHTEXT 算法
teachtext算法,该算法旨在利用来自多个文本嵌入的线索。我们的方法概述如图4所示。
最初,我们培训了一组教师模型 T k : k ∈ { 1 , … , N } {T_k:k∈ \{{1,…,N}}\} Tk?:k∈{1,…,N}用于使用第节中描述的方法进行文本视频检索任务。
教师共享相同的体系结构,但每个模型使用不同的文本嵌入作为输入(使用预先训练的文本编码器提取)。在第二阶段,教师的参数被冻结。
然后,我们对一批视频和字幕进行采样,并计算相应的相似矩阵 S k ∈ R B × B S_k∈R^{B×B} Sk?∈RB×B用于每个教师 T k T_k Tk?(图4右侧)。
然后将这些相似矩阵通过聚合函数 Φ : R N × B × B → R B × B Φ:R^{N×B×B}→R^{B×B} Φ:RN×B×B→RB×B,形成单一监督相似矩阵(图4,右中)
同时,这批视频和字幕同样由学生模型M处理,M生成另一个相似矩阵 S s ∈ R B × B S_s∈R^{B×B} Ss?∈RB×B。最后,除了标准检索损失(方程式1)外,蒸馏损失 L d L_d Ld?促使 S s S_s Ss?靠近聚合函数 Φ ( S 1 , … , S N ) Φ(S_1,…,S_N) Φ(S1?,…,SN?)。
对于学生模型
使用VE和
T
E
s
TE_s
TEs?提取视频特征和文本特征。
4.3.相似矩阵的学习
检索任务的本质是创建一个模型,该模型能够在视频和文本/查询之间建立跨模式的对应关系,为查询准确描述视频的配对分配高相似度值,否则为低相似度值。这使得相似矩阵成为关于模型所持有知识的丰富信息源。为了能够将知识从教师传递给学生,我们鼓励学生生成一个相似度矩阵,该矩阵与教师生成的相似度矩阵的总和相匹配。通过这种方式,我们传递有关文本和视频通信的信息,而不严格要求学生生成与教师完全相同的嵌入。为此,我们将相似矩阵蒸馏损失定义为:
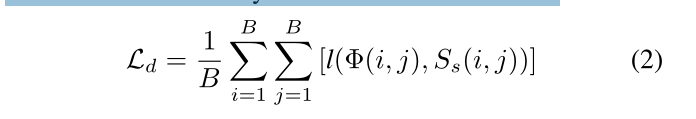
Huber loss损失定义为:
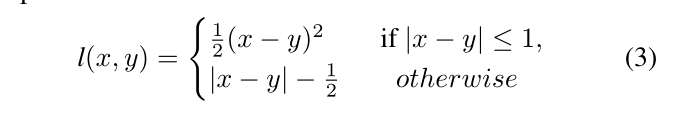
学生模型
我们的方法的一个关键优势是,它与学生和教师的建筑形式无关,因此学生(和教师)可以使用当前文献中的任何方法。我们使用三种不同的最新作品MoEE、CE、MMT作为学生和教师基础架构来测试我们的TEACHTEXTalgorithm。所有这些工作都采用了多模式视频编码器来完成文本视频检索任务。
因此,总的来说,我们为学生模型使用了四种([20,36,42]和CE+)不同的基础架构。(以下四种)
老师模型
教师模型使用与学生模型相同的架构。我们创建了一个由多个教师组成的池,每个教师使用嵌入的不同的预先训练过的文本作为输入。我们考虑的候选文本嵌入是:mtgrovle [8], openai-gpt [50], gpt2-large [51], gpt2xl [51], w2v[44]。因此,我们获得了一组多达5个模型,构成teachersTk
在使用TEACHTEXT训练学生时,只添加了额外的损失项,其他超参数保持不变。
结论
本文提出了一种新的文本视频检索算法TEACHTEXT。我们使用师生模式,学生学习利用一个或多个教师提供的附加信息,共享架构,但每个教师在输入时使用不同的预训练文本嵌入。通过这种方式,我们在六个基准上取得了最先进的成果。最后,我们提出了一个应用我们的方法去噪视频检索数据集。