ЕквЛВПЗж еЊвЊКЭв§Шы
етЦЊЮФеТЪєгкМфНгЙтдДЙРМЦЕФбеЩЋКуГЃадЫуЗЈ,ОЭЪЧЭЈЙ§ЙРМЦЭМЯёЙтееЕФбеЩЋ,дйНЋЙтеебеЩЋШЅГ§,ДгЖјЛёЕУУЛгаЩЋЦЋЕФЭМЯё(ПЩНсКЯЭМ1РэНт)ЁЃжївЊЫМЯыЪЧНЋЙтдДЙРМЦзЊЛЛГЩвЛИіХаБ№ШЮЮё(discriminate),ЖјВЛЪЧЩњГЩШЮЮё (generate)ЁЃ

ЭМ1
етРяОпЬхНтЪЭвЛЯТЩњГЩКЭХаБ№ЁЃдкДЋЭГЕФбеЩЋКуГЃадЗНЗЈРя,Р§Шчgray-worldЪЧМЦЫуЯёЫиЦНОљжЕзїЮЊЭМЯёЙтдДЕФбеЩЋ,max-RGBЪЧМЦЫуЯёЫизюДѓжЕзїЮЊЭМЯёЙтдДбеЩЋ,етаЉЖМЪЧЭЈЙ§ЭМЯёжаЕФЭГМЦбЇЬиеї,жБНгЩњГЩСЫЙтдДбеЩЋ,етбљЕФОЭЪЧЩњГЩШЮЮёЁЃЫљЮНХаБ№ШЮЮё,ОЭЪЧВЂВЛжИЖЈЙтдДбеЩЋвЊдѕУДжБНгМЦЫу,ЖјЪЧХаЖЯЭМЯёЪЧАзЦНКтЛЙЪЧЗЧАзЦНКтЁЃ(дкетРя,ЮвИіШЫЕФРэНтЪЧХаЖЯЩЋЖШжБЗНЭМЩЯФФаЉЕуЪЧНгНќЙтдДбеЩЋ,ФФаЉЕуЪЧКЭЙтдДбеЩЋВюОрКмДѓЁЃетбљЕФХаБ№ФЃаЭбЕСЗКУКѓ,ЪфШывЛеХЦЋЩЋЭМЯё,ОЭПЩвддкЩЋЖШжБЗНЭМЩЯевЕНзюНгНќЙтдДбеЩЋЕФЕу,зїЮЊЙРМЦЕФЙтеебеЩЋЁЃЙигкЩЋЖШжБЗНЭМКѓУцЛсОпЬхУшЪіЁЃ)
зїепжЎЫљвдгаетбљЕФЯыЗЈ,ЪЧвђЮЊПЩвдНЋЭМЯёзЊЛЛЕНЩЋЖШПеМф(ЩЋЖШжБЗНЭМ),дкетИіЖўЮЌЦНУцЩЯ,бАевФФвЛИіЩЋЖШЪЧЙтдДЕФбеЩЋ,етИіШУзїепЯыЕНФПБъЪЖБ№ЗНУцЕФЫуЗЈЁЃ
ЕкЖўВПЗж ЭМЯёзщГЩ

ЙЋЪН(1)жа,IЪЧЯрЛњХФЩуЕФЭМЯё,WЪЧЮяЬхЕФЗДЩфЪєад(ецЪЕбеЩЋ),LЪЧЙтдДЕФЪєадЁЃЯрЛњХФГіРДЕФЭМЯёЪЧЮяЬхКЭЙтдДЙВЭЌзїгУЕФНсЙћЁЃЖдгкЦЋЩЋЭМЯё,вбжЊЕФжЛгаI,ашвЊИљОнЦЋЩЋЭМЯёIЙРМЦЙтдДбеЩЋL,ДгЖјЕУЕНЮяЬхБОЩэЕФбеЩЋWЁЃ
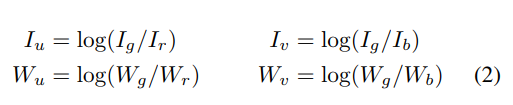
![]()
![]() ?
?
ЙЋЪН(2)(4)жаИјГіЕФЪЧДгrgbПеМфЯђuvЩЋЖШПеМфзЊЛЛЕФЙЋЪН (ВЛРэНтЕФПЩвдШЅПДПДLUVбеЩЋПеМф)ЁЃЙЋЪН(5)ЪЧЭЈЙ§2ЁЂ4ЭЦЕМРДЕФ,ПЩвдгУРДНтЪЭдкЩЋЖШПеМф,ЦЋЩЋЭМЯёЩЋЖШМѕШЅЙтдДЩЋЖШЕУЕНЮяЬхБОЩэбеЩЋЩЋЖШЁЃ
![]()
етРяЛЙИјСЫвЛИіССЖШМЦЫуЙЋЪН,дкЕкШ§ВПЗжМЦЫуЩЋЖШжБЗНЭМЕФЪБКђЛсЪЙгУЕНЁЃ
ЕкШ§ВПЗж Learning
ЪзЯШНјааЩЋЖШжБЗНЭМЕФЖЈвхЁЃ


ЙЋЪН(7)ЪЧЖдЯёЫиЕуЩЋЖШжЕНјааСЫЭГМЦ,ВЂМгЩЯЯёЫиЕуЕФССЖШзїЮЊШЈжиЁЃР§ШчM(u0, v0),КѓАыВПЗжЗНРЈКХРяУц,ЪЧжИЖдгкЯёЫиЕуi,ШчЙћЦфu, vжЕгыu0, v0КмНгНќ,ЯрВюдкІХ/2Фк,ОЭМЦЪ§ЮЊ1,ЗёдђМЦЪ§ЮЊ0ЁЃдкЧАУцГЫЩЯИУЯёЫиЕуЕФССЖШжЕзїЮЊШЈжиЁЃN(u, v)ЪЧЖдM(u, v)НјааЙщвЛЛЏдйПЊЦНЗНИљЁЃЫљЩњГЩЕФЩЋЖШжБЗНЭМЕФЭМаЮБэЪОШчЭМ2:

ЭМ2
ЕкЖўааЪЧЩЋЖШжБЗНЭМ,КсзнзјБъЗжБ№ЪЧu, v,ССЖШжЕДњБэИУu, vжЕЖдгІЕФЯёЫиЕуИіЪ§,ЯёЫиЕуИіЪ§дНЖр,ССЖШжЕдНДѓ,вВОЭЖдгІЯёЫиЕудНССЁЃдквЛИіЩЋЖШжБЗНЭМжа,ЛсПМТЧЫљгаЕФЩЋЖШжЕзщКЯ,ВЂЖдЫќУЧНјааДђЗж,ЕУЗжзюИпЕФЩЋЖШжЕМДЮЊдЄВтЙтдДЕФЩЋЖШжЕЁЃДђЗжКЏЪ§вВОЭЪЧЖдЩЋЖШжБЗНЭМНјааОэЛ§,ЪЧжБЗНЭМжаУПИіжЕЕФЯпадзщКЯЁЃДгa\b\cетШ§еХЭМжаЛЙПЩвдПДГі,дкrgbШ§ЭЈЕРЕФбеЩЋжЕЩЯЕФЫѕЗХ,дкЩЋЖШжБЗНЭМЩЯЛсБэЯжЮЊЕуЕФЦНвЦЁЃетШ§еХЭМаЮзДУЛгаВюБ№,жЛЪЧЙтдДбеЩЋВЛЭЌЕМжТетаЉЭМаЮдкЩЋЖШжБЗНЭМЩЯЮЛжУВЛЭЌЁЃ


ЙЋЪН(10)ЪЧЫ№ЪЇКЏЪ§ЕФЖЈвхЁЃЦфжа,N(u, v)ЪЧЙщвЛЛЏжЎКѓЕФЭМЯёЩЋЖШжБЗНЭМ;P(u, v)ЪЧN(u, v)ОЙ§ОэЛ§FжЎКѓЕУЕНЕФдЄВтЙтдДЩЋЖШжБЗНЭМ;C(u, v, u*, v*)ЖЈвхСЫЙтдДЩЋЖШжЎМфЕФВюОр,вВОЭЪЧДэЮѓЙРМЦЕФЙтдДЕМжТЕФЫ№ЪЇЁЃЯТУцетеХЭМЪЧCЕФПЩЪгЛЏ,дВШІШІГіРДЕФВПЗжЪЧецЪЕЙтдДЩЋЖШжЕ,дНССДњБэдННгНќецЪЕЙтдД,Ы№ЪЇCдНаЁ,дНАЕдђДњБэЫ№ЪЇCдМДѓЁЃЫљвдЫ№ЪЇКЏЪ§зюаЁЛЏПЩвдРэНтЮЊ,дННгНќецЪЕЙтдДЕФЕиЗН,CдНаЁ,ФЧУДШЈжиPПЩвдДѓвЛаЉ;ЖјдЖРыецЪЕЙтдДЕФЕиЗН,CдНДѓ,ШЈжиPдНаЁЁЃФЧУДбЕСЗКУФЃаЭКѓ,ЪфШывЛеХЦЋЩЋЕФЭМЯё,ЦфЩЋЖШжБЗНЭМОЙ§ОэЛ§ЕУЕНP,PжажЕзюДѓЕФЕу,ОЭЪЧзюНгНќецЪЕЙтдДЕФЕу,ЮвУЧНЋетИіЕуЕФЩЋЖШзїЮЊЙРМЦЙтдДЕФЩЋЖШЁЃетИіЗНЗЈвВЪЧРрЫЦгкЗжРрЮЪЬт,евЕНИХТЪзюДѓЕФвЛИіРрБ№,зїЮЊдЄВтЕФБъЧЉЁЃ

ЭМ3
Г§ДЫжЎЭт,зїепЛЙЪЙгУЩњГЩФЃаЭКЭетИіХаБ№ФЃаЭНјааСЫЖдБШ,ЩњГЩФЃаЭЕФЫ№ЪЇКЏЪ§МћЙЋЪН(12)ЁЃЪЙетИіКЏЪ§зюДѓЛЏ,ОЭЪЧЪЙдННгНќецЪЕЙтдДЕФЕиЗНШЈжидНДѓЁЃ(ЦфЪЕетРяЮвВЛЪЧКмРэНтЯТУцЕФЙЋЪН)ЁЃзїепЕУЕНЩњГЩЗНЗЈКЭХаБ№ЗНЗЈЕФFВЂНЋЫќУЧПЩЪгЛЏ,ПЩЪгЛЏЕФНсЙћдкЭМ4жаЁЃДгетИіНсЙћжаПЩвдПДГі,ЩњГЩЗНЗЈетЪЧПЩвдЭЛГізюССЕФФЧИіЕу,вВОЭЪЧФФИізюНгНќецЪЕЙтее,ЕЋЪЧХаБ№ЗНЗЈЛЙПЩвдРПЊВюОр,ВЛНіПЩвдЭЛГізюСС,ЛЙНјвЛВНХаБ№ФФаЉЕуПЩФмадМЋаЁ,вВОЭЪЧЭМжаКкЩЋАЕЩЋЕФЕуЁЃзюжеЕФФЃаЭбЕСЗКЭЙтдДЙРМЦЙ§ГЬМћЭМ5.


ЭМ4

ЭМ5
ЕкЫФВПЗж efficient filtering ИпаЇТЫВЈ
ЮФеТжаОэЛ§ВЩгУН№зжЫўНсЙЙ,вЛЙВга7Ву(ЯТВЩбљЪЙгУЫЋЯпадВюжЕ),УПвЛИіЖМгУ5*5ЕФаЁОэЛ§КЫНјааОэЛ§,дкжааФгаИпжЪСПЕФЯИНк,дЖРыжааФЕФЧјгђгаДжТдЕФФкШнЁЃ

ЭМ6
ЕкЮхВПЗж generalization
етИіЗНЗЈжа,ЪфШыЪЧЩЋЖШжБЗНЭМ,БОжЪЩЯЛЙЪЧЭМЯёЕФЭГМЦаХЯЂ,КЭgray-worldЕШЗНЗЈвЛбљ,ЖМНЋЭМЯёЪгзївЛАќЕФЯёЫи(ЁАbagЁБ of pixels),ЪЧУЛгаПеМфаХЯЂЕФЁЃЫљвдЯждкВЛдйНіНіЖддЭМЯёЕФЩЋЖШжБЗНЭМНјааОэЛ§,ЖјЪЧЙЙдьвЛЯЕСаIj , Nj , етаЉIj ЪЧдЭМвдМАЫќЕФдіЧПЭМЯё(ЁБaugmentedЁБ images),НЋетаЉЭМЯёОЙ§ОэЛ§КѓЕФНсЙћЧѓКЭ,дйЪфШыsoftmaxЁЃ
ЯТУцЫЕУїЪЙгУЕФЪЧФФаЉaugmented imagesЁЃгЩгкУПИіЭЈЕРЯёЫижЕЕФЫѕЗХБиаызМШЗгГЩфЕНЩЋЖШжБЗНЭМЩЯЕФЦЋвЦ,вђДЫвЊБЃСєБъСПГЫЗЈ,вВОЭЪЧЫЕscalingВйзїКЭfilteringВйзїЕФЯШКѓЫГађВЛгАЯьНсЙћЁЃВЂЧввђЮЊвЊМЦЫуlog,ЪфШыашвЊЪЧЗЧИКжЕЁЃ


ЙЋЪН(13)жа,blurЪЧКазгТЫВЈВйзї(box filter),етРяБэЪОЕФЪЧЧѓКЭжЎКѓдйЙщвЛЛЏЁЃІб=2 ЪБ,hБэЪОЕФМДЮЊОжВПБъзМВюЁЃ
ЕкСљВПЗж results
Ъ§ОнМЏгУЕФЪЧcolor checkerКЭchengЕШЬсГіЕФЪ§ОнМЏ,ЕквЛИіЪЧ1ИіЯрЛњХФЩуЕФ568еХЭМЦЌ,ЕкЖўИіЪ§ОнМЏЪЧ8ИіЯрЛњХФЩуЕФ1736еХЭМЦЌ(ЪЧЭЌвЛИіГЁОАБЛ8ИіЯрЛњХФ8ДЮ)ЁЃЪЙгУЕФЪЧ3елНЛВцбщжЄ(3-fold cross-validation),вВОЭЪЧНЋЪ§ОнМЏЗжЮЊ3Зн,2ЗнгУзїбЕСЗ,1ЗнгУзїбщжЄ,бЛЗ3ДЮЁЃ
 ?
?