替换操作
????????替换操作可以同步作用于Series和DataFrame中
- 单值替换:普通替换:替换所有符合要求的元素:to_replace=15,value='e'
? ? ? ? ? ? ? ? ? 按列指定单值替换:to_replace={列标签:替换值},value='value' - 多值替换:列表替换:to_replace=[],value=[]
? ? ? ? ? ? ? ? ? 字典替换:to_replace={to_replace:value,to_replace:value}
df=DataFrame(data=np.random.randint(0,100,size=(5,6)))
df.replace(to_replace='1',value='wtf')
df.replace(to_replace=1,value='wtf') #要注意数据类型
df.replace(to_replace={10:'what’s up'}) #字典形式替换(推荐)
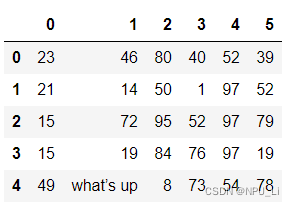
df.replace(to_replace={4:5},value='wtf') #替换指定列的5为wtf?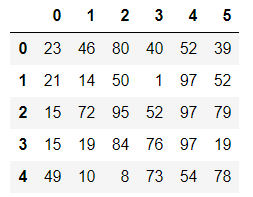

 ?
?
?映射操作
- 创建一个映射关系列表,把values元素和一个特定的标签或者字符串绑定(给一个元素提供不同的表现形式)
- 创建一个df,两列分别是姓名和薪资,然后给其名字起对应的英文名
dic={'name':['张三','李四','张三'],'salary':[15000,20000,15000]}
df=DataFrame(data=dic)
#映射关系表
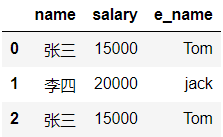
dicc={'张三':'Tom','李四':'jack'}
df['e_name']=df['name'].map(dicc) 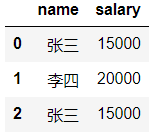
- map是属于Series的函数,只能通过Series来调用
- map还可以充当运算工具
? ? ? ? ?案例:超过3000的部分需要交纳50%的税,计算每个人的税后薪资。
#制定一个运算法则
def ssalary(s):
return s-(s-3000)*0.5
df['salary'].map(ssalary) #可以将df['salary']这个Series中的每一个元素作为参数传递给s
随机抽样
df=DataFrame(data=np.random.randint(0,100,size=(100,3)),columns=['A','B','C'])
#将原始数据打乱
df.take([2,0,1],axis=1) #只能用隐式索引,0是行,1是列
#生成随机的乱序序列
np.random.permutation(3) #生成0到2的乱序序列,(0,n-1)
#行列都打乱,取前50
df.take(np.random.permutation(3),axis=1).take(np.random.permutation(100),axis=0)[0:50]分类处理
? ? ? ? 数据分类核心:groupby()
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?groups属性查看分组情况
df = DataFrame({'item':['Apple','Banana','Orange','Banana','orange','Apple'],'price ':[4,3,3,2.5,4,2],'color':['red','yellow','yellow','green','green','green'],'weight':[12,20,50,30,20,44]})
#要对水果种类分类
df.groupby(by='item') #<pandas.core.groupby.generic.DataFrameGroupBy object at 0x000002986A8BF580>
#查看属性
df.groupby(by='item').groups #{'Apple': [0, 5], 'Banana': [1, 3], 'Orange': [2], 'orange': [4]}
? ? ? ? ?分组聚合
#计算出每一种水果的平均价值
df.groupby(by='item').mean() #这样是默认对所有数值型数据进行mean操作
df.groupby(by='item')['price'].mean() #这样是只对价格进行聚合
#及算每种颜色对应水果的平均重量
df.groupby(by='color')['weight'].mean()
#将计算出的平均重量汇总到数据中
dic=df.groupby(by='color')['weight'].mean().to_dict() #生成一个用来映射到每个颜色的重量的dic
df['mean_w']=df['color'].map(dic)? ? ? ? 高级数据聚合
- 使用groupby分组后,也可以使用transform和apply提供自定义函数实现更多的运算
- df.groupby('item')['price'].sum() <==> df.groupby(" item')['price'].apply(sum)
- transform和apply都会进行运算,在transform或者apply中传入函数即可
- transform和apply也可以传入一个lambda表达式
def my_mean(s): #这是传入的s是一个list
m_sum=0
for i in s:
m_sum+=i
return m_sum /len(s)
df.groupby(by='item')['price'].transform(my_mean) #左图,可以直接来汇总到源数据
#同
df.groupby(by='item')['price'].apply(my_mean) #右图,这个还要在映射一次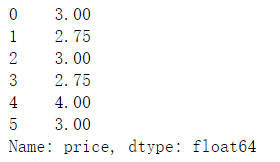

透视表、交叉表
- 透视表是一种可以对数据动态排布并且分类汇总的表格格式。或许大多数人都在Excel使用过数据透视表,也体会到它的强大功能,而在pandas中它被称作pivot_table。
- 透视表优点:灵活性高,可以随意定制你的分析计算要求
? ? ? ? ? ? ? ? ? ? ? 脉络清晰易于理解数据
? ? ? ? ? ? ? ? ? ? ? 操作性强,报表神器
看视频吧