原文链接:http://tecdat.cn/?p=24511
原文出处:拓端数据部落公众号
本文通过一些指数对散点图矩阵和平行坐标显示中的面板进行排序,并根据其数值水平对面板进行着色。
显示相关矩阵
cor <- cor(ley)
leclr <- mat.colr(cor)mtcolr?根据相关性大小为相关性分配三种颜色。高相关性为红色,中间三分之一为蓝色,底部三分之一为天蓝色。
plclrs(lolr,label=ronms(coor)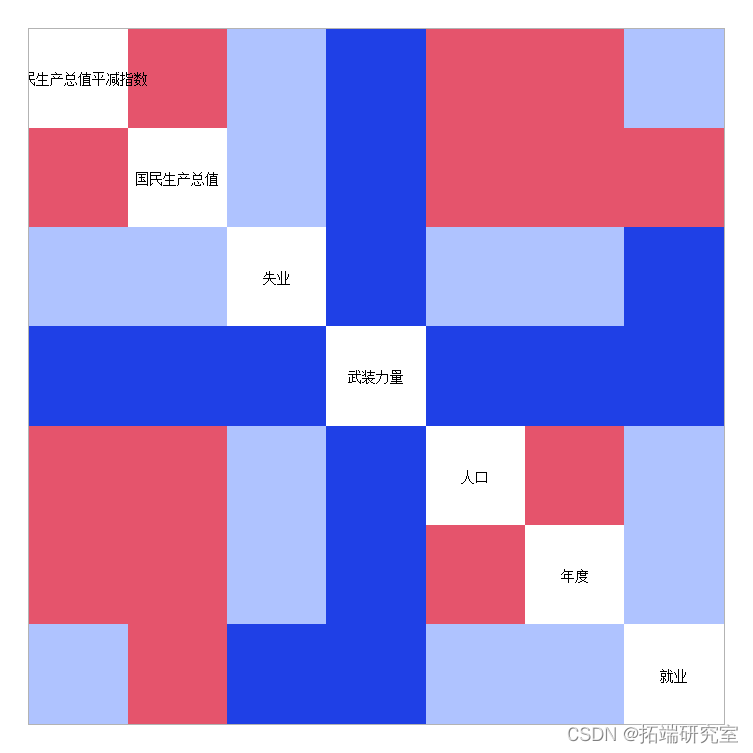
如果要更改配色方案:
leolo <- colr(cor, brak=FALE)
lecor <- tcor(cor, bes,
c.cr(4))如果在绘图之前重新排列变量,则绘图更容易解释。
oge <- rdclust(lnlcor)
lgeolor1 <- nlclor[lne.,lo.]
plot(lnco1,dlbls=rwe(ngyr1))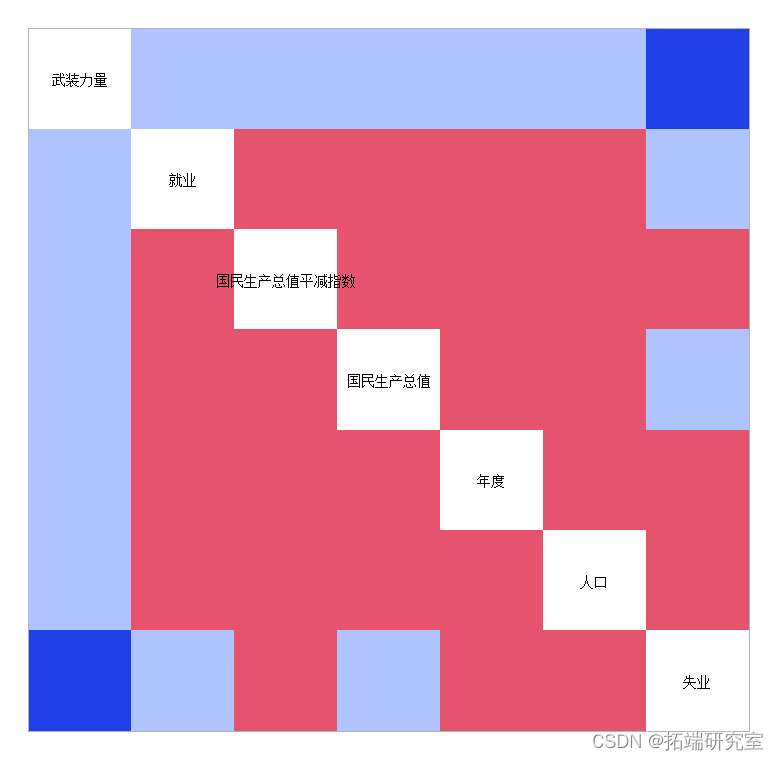
显示带有彩色面板的配对图
?所有高相关面板一起出现在一个块中的一个版本。
pais(loly, orr= lolo,acor= lgy.or)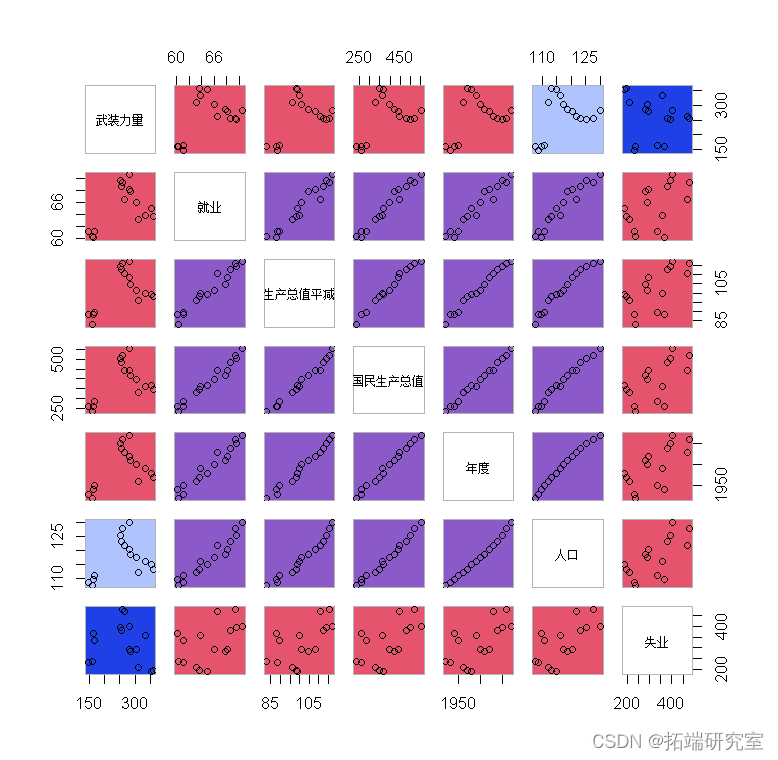
如果?order?未提供 ,则按默认数据集顺序绘制变量。
用彩色面板显示平行坐标图
平行坐标图面板可以着色的版本?。同样,红色面板具有高相关性,蓝色面板具有中等相关性,天蓝色面板具有低相关性。
pard(lng, ordr= loyo,color= colr,
horol=TRUE)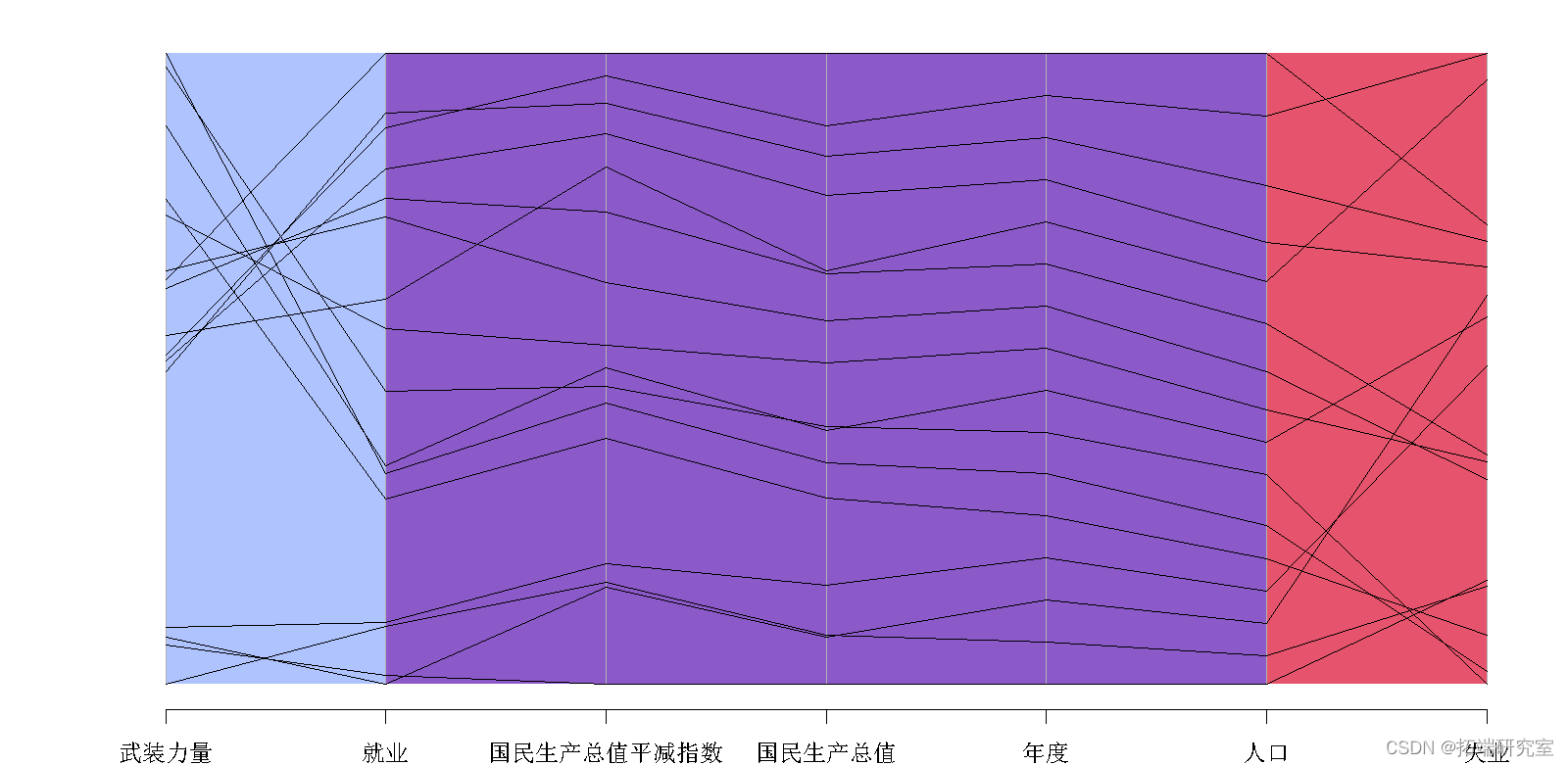
绘制重新排序的树状图
dist?是一个内置的距离矩阵,给出了城市之间的距离。
hclst(dis, "ave")
plt(hc)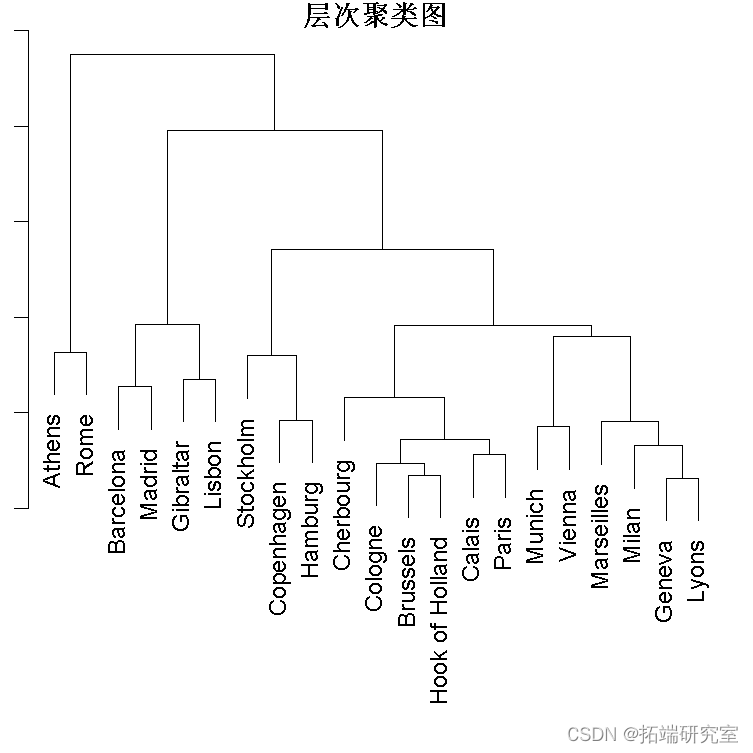
重新排序树状图以提高附近分支之间的相似性。将其应用于?hc?对象:
ordeu(hc, dis)
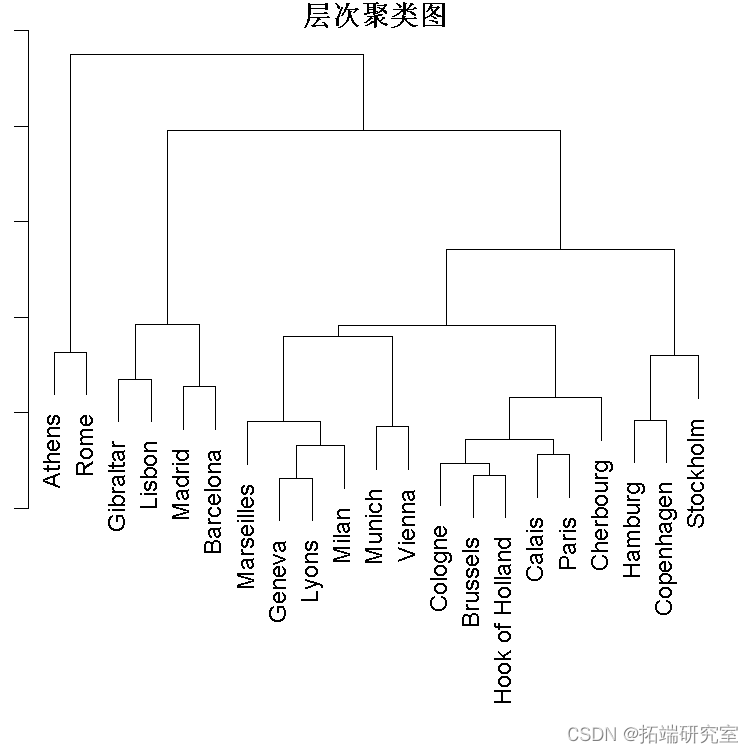
两个树状图对应于相同的树结构,但第二个树状图显示巴黎和瑟堡比离慕尼黑更近,罗马离直布罗陀比离巴塞罗那更近。
我们还可以将两种排序与颜色的图像图进行比较。第二个排序似乎将附近的城市彼此靠近。
ct <- dor(edt, rev(cs(5)))
pltcl(cma, rles=lals)
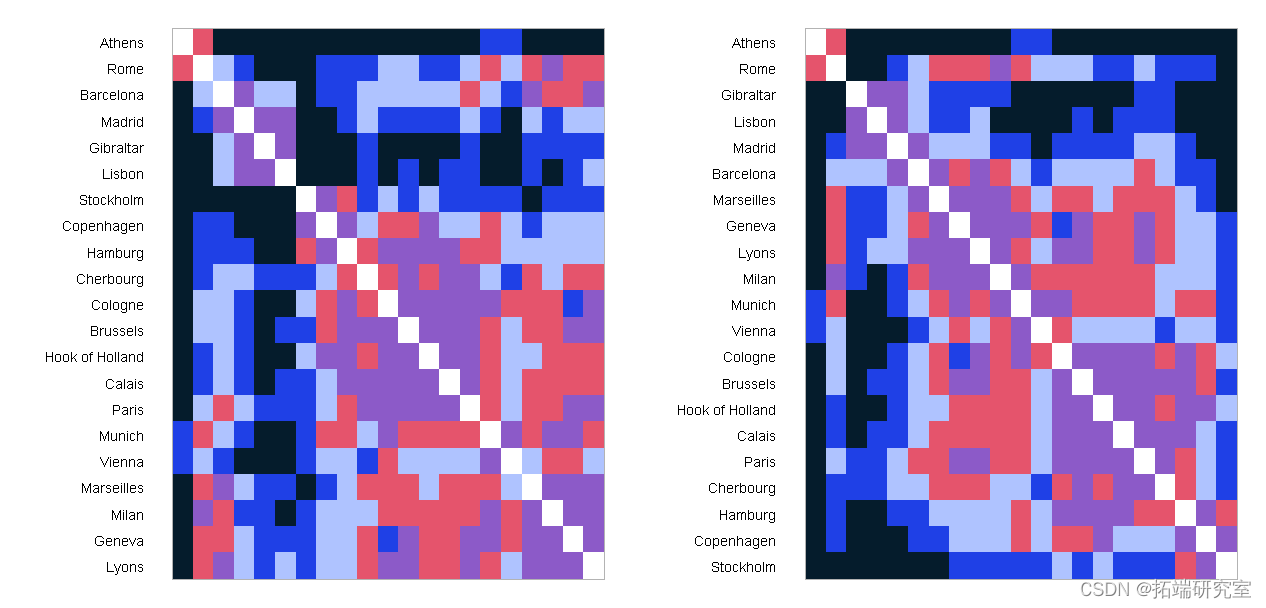

最受欢迎的见解
3.R语言对用电负荷时间序列数据进行K-medoids聚类建模和GAM回归
5.Python Monte Carlo K-Means聚类实战