����
�������úõ���һ�۽�������ʧ(Cross Entropy Loss)��
����Ϣ������,�ٵ�������Ȼ����,Ȼ������KLɢ��,�������KLɢ���뽻���صĹ�ϵ��
��Ȼ�����е㳤,�����ſ��걾��,��һ����Խ�������ʧ�и���һ�������
��Ϣ��
��Ϣ�ļ�ֵ���������¼��IJ�ȷ����,���¼��IJ�ȷ����Ҫ��ô������?�𰸾�����Ϣ��(information entropy)��
��������߱���������500���Ʊ,���˻���һ��,��Ϊ���������˴����IJ�ȷ���ԡ����������߱�����û�в�Ʊ,���˻�����û�з�Ӧ,��Ϊ����������С��ʮ�а˾Ų����в�Ʊ���൱���㼸��û������������û���в�Ʊ����µIJ�ȷ���ԡ�����˵�㴫�����Ϣ��̫�١�����֪������ֻ����0��1֮��,Ҳ����˵,����ڸ���Ϊ1��ʱ��,��Ϣ��Ϊ0,�Ҹ���ԽС,��Ϣ��Խ�������Ƿ���,���������ܷ��������Ĺ���,ij���¼�����Ϣ������ʵĹ�ϵ�� i = log ? ( 1 p ) i = \log(\frac{1}{p}) i=log(p1?),����Ķ�������2Ϊ��, p p p���¼������ĸ��ʡ�
����������ʽ������ô������?����Ӳ����ϷΪ��,�����һö�����Ӳ��,���������ͷ���ĸ������,�������������Զ,ֻ��ͨ����λ�ź�(0��1)���н���,��ΰ����Ӳ�ҵĽ���������ء���Ȼ,��ʱֻ��Ҫ����һ���źžͿ���,��1��ʾ����,��0��ʾ���档��Ϣ�ļ�ֵ���������¼��IJ�ȷ����,����һöӲ�ҽ������Ϣ,������������������һ����IJ�ȷ���ԡ�
����������һ��ת����Ϸ,���ת�̱����ȵط�Ϊ8������,�������Ҫ��ת�̵Ľ�����ͳ�ȥ,��ô��Ҫ���ٸ��ź���?����3���źš�
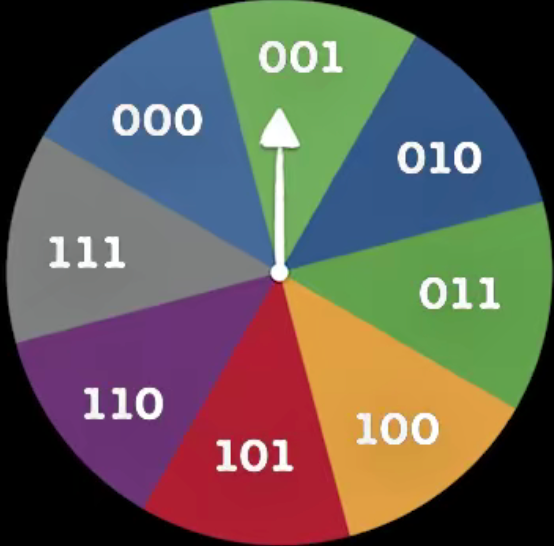
��������������,���Ƿ���һ������,��һ����Ϸϵͳ�����п��ܳ��ֵĵȸ����¼�����ȡ��2Ϊ�Ķ���,��������Ҫ�����¼��������Ҫ���ź���������������Ӳ����Ϸ���� log ? 2 ( 2 ) = 1 \log_2(2)=1 log2?(2)=1,��ת����Ϸ���� log ? 2 ( 8 ) = 3 \log_2(8)=3 log2?(8)=3??���������������Ϣ����
�� ��Ϣ�� = log ? ( N ) \text{��Ϣ��}=\log(N) ��Ϣ��=log(N),����� N N N�ǵȿ����¼�������
�������ֶ�����ȷ���Ե���Ϣ����Ϊ��Ϣ��,���ϸ���˵�Ⲣ������ũ��˵����Ϣ��,��ֻ����Ϣ�ص�һ������,�����е��¼��ǵȿ��ܵġ����������ĸ���������¼������Ŀ����Բ�һ����ϵͳ�� ������ʵ�����о�������������������ʶ���50%��Ӳ�ҡ�
ʵ����,�������ǿ���һ���¼��ĸ���ֵת��Ϊһ���ȿ����¼�ϵͳ�з���ij���¼��ĸ��ʡ�������˵,�������ǿ���һ������ֵת��Ϊ����N�����������һ��������ȿ����¼�ϵͳ������ij����ĸ��ʡ�
�����в�Ʊ�ĸ��ʺܵ�,ֻ����ǧ���֮һ,���ǿ����������ֵת��Ϊ����ǧ������������н���ĸ��ʡ����������ϵͳ��,������ǧ����ȿ����¼�������ֻ��Ҫ��1���Ը���ֵ�Ϳ���������ȿ����¼�ϵͳ���¼�������,�� N = 1 p N=\frac{1}{p} N=p1??��
����������һ�������ֽŵIJ�����Ӳ��,�����泯�ϵĸ�����0.8,���泯�ϵĸ�����0.2��

����ͼ,���泯��0.2�ĸ��ʿ���������5���������ϵͳ������ij����ĸ��ʡ�

�����泯��0.8�ĸ��ʿ������������1.25�����ϵͳ������ij����ĸ��ʡ�����ͨ�������һ���ǵȸ����¼���ϵͳ����������ȸ����¼���ϵͳ��
����Եȸ����¼�ϵͳ,���ǾͿ��Ժ����ؼ������ǵ���Ϣ�����ٰ��������������������ϵͳ����Ϣ��������,�������������Ӳ�ҵ���Ϣ��: log ? 5 + log ? 1.25 \log 5 + \log 1.25 log5+log1.25,����������������������ĵȸ���ϵͳ�������ֵĸ���Ҳ��һ��,���������Ҫ�ֱ�������dz��ֵĸ���,�� 0.2 ? log ? 5 + 0.8 ? log ? 1.25 0.2 \cdot \log 5 + 0.8 \cdot \log 1.25 0.2?log5+0.8?log1.25��
��������÷���ȥ������Щ�����ֵ,����
p
1
?
log
?
1
p
1
+
p
2
?
log
?
1
p
2
(1)
p_1 \cdot \log \frac{1}{p_1} + p_2 \cdot \log \frac{1}{p_2} \tag{1}
p1??logp1?1?+p2??logp2?1?(1)
�����и����¼���һ�����,���ǿ�����ô��ʾ:
��
i
p
i
log
?
1
p
i
(2)
\sum_i p_i \log \frac{1}{p_i} \tag{2}
i��?pi?logpi?1?(2)
�������������ʽ��
��
i
p
i
log
?
1
p
i
=
��
i
(
p
i
?
(
log
?
1
?
log
?
p
i
)
)
=
��
i
?
p
i
log
?
p
i
=
?
��
i
p
i
log
?
p
i
(3)
\begin{aligned} \sum_i p_i \log \frac{1}{p_i} &= \sum_i (p_i \cdot (\log1 - \log p_i)) \\ &= \sum_i - p_i \log p_i \\ &= - \sum_i p_i \log p_i \end{aligned} \tag{3}
i��?pi?logpi?1??=i��?(pi??(log1?logpi?))=i��??pi?logpi?=?i��?pi?logpi??(3)
�͵õ�����ũ���������Ϣ����ʽ ? �� i p i log ? p i -\sum_i p_i \log p_i ?��i?pi?logpi?
���ǿ��Կ���,��Ϣ��ʵ���ؾ������Ǹ�ÿ������ֵ���������ij��ϵͳ����Ϣ����ƽ��ֵ,����˵����Ϣ����������
�������Ҫ�Ƚ���������ģ�͵ľ���,��İ취���ǰ����ǵ���Ϣ�ض������,ֱ�ӱȽ���������ͺ��ˡ�����������,�ڻ���ѧϰ��,����������֪��ѵ�������ĸ���ģ�͡���ʱ��,���Ǿ���Ҫ�õ������,Ҳ��ΪKLɢ��(KL Divergence)��
��������֮ǰ,Ϊ��֪ʶ��������,������Ҫ�˽⼫����Ȼ���Ƶĸ��
������Ȼ����
������Ȼ������������������,������Ȼ���ơ�ͨ����˵,��������֪�����������Ϣ,ȥ�������п��ܵ�����Щ����������ֵ�ģ�Ͳ���ֵ��
����˵����һ������������,��������֤��ȫ�ܴ���֪����ȥ�Ƴ�������Щ�����ĸ��ʷֲ�,ֻ��˵��һ����������Ȼֵ˵����,��ʵ�����Ѿ�����,�����кܶ�(����)ģ��,ÿ��ģ�Ͳ�����Щ��ʵ�����Ŀ����Ծͽ���Ȼֵ��������Ȼ���ƾ���ѡ����Ȼֵ��ߵ�ģ����������ʵ(����)ģ�͡�
��������Ӳ��Ϊ��,���Ǽ�Ӳ�ҵ�����ΪH(Head),����ΪT(Tail)��
�������Dz�֪�����Ӳ�Ҳ���������ĸ���,�������ǿ�����10��ʵ��,�����������һ����:HHHHHHHTTT����ǰ7��������,��3���Ƿ��档
����������������������ģ��(���ʷֲ�),
- ģ��A��������ĸ��� p = 0.1 p=0.1 p=0.1,��������ĸ��ʾ��� 1 ? p = 0.9 1-p=0.9 1?p=0.9?
- ģ��B��������ĸ��� p = 0.7 p=0.7 p=0.7,��������ĸ����� 1 ? p = 0.3 1-p=0.3 1?p=0.3
- ģ�� C C C��������ĸ��� p = 0.8 p=0.8 p=0.8,��������ĸ����� 1 ? p = 0.2 1-p=0.2 1?p=0.2
����ij������ģ�Ͳ����������Ŀ������ǿ��Լ��������,��ʽΪ:
P
(
C
1
,
C
2
,
?
?
,
C
10
�O
��
)
=
��
i
=
1
10
P
(
C
i
�O
��
)
(4)
P(C_1,C_2,\cdots,C_{10}|\theta) = \prod_{i=1}^{10} P(C_i|\theta) \tag{4}
P(C1?,C2?,?,C10?�O��)=i=1��10?P(Ci?�O��)(4)
����
C
i
��
{
0
,
1
}
C_i \in \{0,1\}
Ci?��{0,1}�ǵ�
i
i
i����Ӳ�ҵĽ��,����ʽ��˵�����ɲ���
��
\theta
��ȷ����ģ��ͬʱ����
C
1
,
C
2
,
?
?
,
C
10
C_1,C_2,\cdots,C_{10}
C1?,C2?,?,C10?�ĸ��ʡ�
ͬʱ�����������ˡ�
�����Ŀ����Ծͽ���Ȼֵ��
�������ֻ��Ҫ����ÿ��ģ�͵���Ȼֵ,Ȼ��ѡ����Ȼֵ����ģ����������ʵģ�͡�
ģ�� A A A����Ȼֵ: 0. 1 7 0. 9 3 �� 7.29 e ? 08 0.1^70.9^3 \approx 7.29e-08 0.170.93��7.29e?08
ģ�� B B B����Ȼֵ: 0. 7 7 0. 3 3 �� 0.00222 0.7^70.3^3\approx 0.00222 0.770.33��0.00222
ģ�� C C C����Ȼֵ: 0. 1 7 0. 9 3 �� 0.00168 0.1^70.9^3\approx 0.00168 0.170.93��0.00168
������Ȼֵ����ģ�;ͽ������Ȼ���Ʒ���
������Ȼ��
���ǴӼ�����Ȼ���ƵĽǶ�����һ����ʧ������ѡ��
����ͼΪ��,��һЩͼƬ,���뵽������,��������������ͼƬ��è�Ŀ����ԡ�������ЩͼƬ��ѵ������,�����Ѿ���ЩͼƬ�Ƿ���è��
����Ӳ����,����ͨ�� �� \theta ������ʾ����,��������������Ծ������ W , b W,b W,b����ʾ��
�������:
P
(
x
1
,
x
2
,
x
3
,
?
?
,
x
n
�O
W
,
b
)
(5)
P(x_1,x_2,x_3,\cdots,x_n|W,b) \tag{5}
P(x1?,x2?,x3?,?,xn?�OW,b)(5)
n
n
n��ЩͼƬ�ĸ���;
x
i
��
{
0
,
1
}
x_i \in \{0,1\}
xi?��{0,1}�������������ͼƬ�Ƿ�Ϊè,
1
1
1�������
��������Ҳ������ʽ�ij����˵���ʽ:
P
(
x
1
,
x
2
,
x
3
,
?
?
,
x
n
�O
W
,
b
)
=
��
i
=
1
n
P
(
x
i
�O
W
,
b
)
(6)
P(x_1,x_2,x_3,\cdots,x_n|W,b) =\prod_{i=1}^n P(x_i|W,b) \tag{6}
P(x1?,x2?,x3?,?,xn?�OW,b)=i=1��n?P(xi?�OW,b)(6)
���ǾͿ��Եõ�������ЩͼƬ��ģ�͵���Ȼֵ,����Ҫ�ҵ�ʹ�������Ȼֵ����
W
,
b
W,b
W,b��
����
W
,
b
W,b
W,b?��һ��ȷ����ֵ,������֪����������Կ�������
W
,
b
W,b
W,b�������ȷ����һ������,�ú�����������
y
i
y_i
yi?��ʾ����ͼƬ
x
i
x_i
xi?��è�Ŀ������ж��,��
y
i
=
N
N
W
,
b
(
x
i
)
y_i = NN_{W,b}(x_i)
yi?=NNW,b?(xi?)??���������ǾͿ����ÿ�����
y
i
y_i
yi?���������IJ���
W
,
b
W,b
W,b:
P
(
x
1
,
x
2
,
x
3
,
?
?
,
x
n
�O
W
,
b
)
=
��
i
=
1
n
P
(
x
i
�O
y
i
)
(7)
P(x_1,x_2,x_3,\cdots,x_n|W,b) =\prod_{i=1}^n P(x_i|y_i) \tag{7}
P(x1?,x2?,x3?,?,xn?�OW,b)=i=1��n?P(xi?�Oyi?)(7)
�������벻ͬè��ͼƬ
x
i
x_i
xi?,���ǿ��Եõ���ͬ�ĸ���ֵ
y
i
y_i
yi?��
���ʽ������Ҫ���չ����,�����������ʱ��д���� x i x_i xi?��ȡֵ�й�,�� x i = 1 x_i=1 xi?=1ʱ,�����Ӧ�����ж�Ϊè�ĸ���,ȡ y i y_i yi?;�� x i = 0 x_i=0 xi?=0ʱ,�����Ӧ�����жϲ���è�ĸ���,ȡ 1 ? y i 1-y_i 1?yi?��
���ڻ����нⷨ��,���ʽ�ӿ���ͨ����Ŭ���ֲ�չ����,��Ϊ x i �� { 0 , 1 } x_i \in \{0,1\} xi?��{0,1}�������,ͬʱ y i y_i yi?����һ�����ʡ�

����Ӳ�ҵ���������,�� x = 1 x=1 x=1ʱ,������Ӳ��������ĸ��� p p pȥ��;�� x = 0 x=0 x=0��,������Ӳ���Ƿ���ĸ��� 1 ? p 1-p 1?pȥ�ˡ�
���ǾͿ���ͨ����Ŭ���ֲ������ʽ����չ��ʽ
(
7
)
(7)
(7),��:
P
(
x
1
,
x
2
,
x
3
,
?
?
,
x
n
�O
W
,
b
)
=
��
i
=
1
n
y
i
x
i
(
1
?
y
i
)
1
?
x
i
(8)
P(x_1,x_2,x_3,\cdots,x_n|W,b) = \prod_{i=1}^n y_i^{x_i}(1-y_i)^{1-x_i} \tag{8}
P(x1?,x2?,x3?,?,xn?�OW,b)=i=1��n?yixi??(1?yi?)1?xi?(8)
����ͨ���ڵ�ʽ�ұ�ȡ����,�����˱������,��Ϊȡ�������ı䵥���Եġ�
log
?
(
��
i
=
1
n
y
i
x
i
(
1
?
y
i
)
1
?
x
i
)
=
��
i
=
1
n
log
?
(
y
i
x
i
(
1
?
y
i
)
1
?
x
i
)
=
��
i
=
1
n
(
x
i
?
log
?
y
i
+
(
1
?
x
i
)
?
log
?
(
1
?
y
i
)
)
(9)
\begin{aligned} \log \left( \prod_{i=1}^n y_i^{x_i}(1-y_i)^{1-x_i} \right )&= \sum_{i=1}^n \log \left(y_i^{x_i}(1-y_i)^{1-x_i} \right) \\ &= \sum_{i=1}^n \left(x_i \cdot \log y_i + (1-x_i)\cdot \log (1-y_i) \right) \\ \end{aligned} \tag{9}
log(i=1��n?yixi??(1?yi?)1?xi?)?=i=1��n?log(yixi??(1?yi?)1?xi?)=i=1��n?(xi??logyi?+(1?xi?)?log(1?yi?))?(9)
����Ҫ����Ȼֵ,��ȡ�����ֵ,����ʧ������ȡ��Сֵ,���ǰѵ�ʽ���߳���һ������,���������Сֵ��
min
?
?
��
i
=
1
n
(
x
i
?
log
?
y
i
+
(
1
?
x
i
)
?
log
?
(
1
?
y
i
)
)
(10)
\min - \sum_{i=1}^n \left(x_i \cdot \log y_i + (1-x_i)\cdot \log (1-y_i) \right) \tag{10}
min?i=1��n?(xi??logyi?+(1?xi?)?log(1?yi?))(10)
��Ȼ���ʽ�ӿ�����������,��ʵ���ϻ����кܴ�ͬ��,��Ҫ�����������ǵ����ٲ�ͬ��
������Ķ��������ǹ������ȥ��,���Ҹ���Ҳ��Ϊ�˴ճ�����Сֵ��
�������Ǿ����˽�����ء�
KLɢ��
KLɢ��,Ҳ����Ϊ�����,���������������ֲ��ľ���,��
P
P
P��
Q
Q
Q���������ʷֲ�,��
P
P
P��
Q
Q
Q�������Ϊ:
D
K
L
(
P
�O
�O
Q
)
=
��
i
P
(
i
)
log
?
P
(
i
)
Q
(
i
)
(11)
D_{KL}(P||Q) = \sum_i P(i) \log \frac{P(i)}{Q(i)} \tag{11}
DKL?(P�O�OQ)=i��?P(i)logQ(i)P(i)?(11)
����
i
i
i�����ֲ��е��������
����
- ���߱��Գ���,�� D ( P �O �O Q ) �� D ( Q �O �O P ) D(P||Q) \neq D(Q||P) D(P�O�OQ)��?=D(Q�O�OP)
- �Ǹ���,�� D ( P �O �O Q ) �� 0 D(P||Q) \geq 0 D(P�O�OQ)��0
�ٸ�����,��������Ӳ��Ϊ��,����������һ����ƽ��Ӳ��,���������ʶ���50%;���ǻ���һ����ƫ���Ӳ��,���������Ϊ p p p,�������Ϊ q q q��
����Ҫ����ж��������ֲ�����������?
���ܲ��ûش�,��������֪��,��� p = 0.55 p=0.55 p=0.55,���϶��� p = 0.95 p=0.95 p=0.95Ҫ�����ơ�
���ǿ��Դ���Ӳ�ҵĽ������,
? ���蹫ƽӲ�ҵ��������Ϊ:HHTHHTTHTHTH
���� p = 0.55 p=0.55 p=0.55Ӳ�ҵ��������Ϊ:HHTHHTTHHHTH
���� p = 0.95 p=0.95 p=0.95Ӳ�ҵ��������Ϊ:HHHHHHTHHHHH
���ǿ��Լļ��㲻��ȵĽ������,���Ǹ��Ͻ��������Ǽ������ij���������Ȼֵ��
�����Ȼֵ�ܽӽ�,��ô˵�����������ʷֲ��ܽӽ���
����(��ƽӲ���׳���)�۲���,���ǾͿ��Լ��㹫ƽӲ�ҵ���Ȼֵ������Ӳ�ҵ���Ȼֵ�ı�ֵ:
P
(
�۲���
�O
��ƽӲ��
)
P
(
�۲���
�O
ƫ��Ӳ��
)
\frac{P(\text{�۲���}|\text{��ƽӲ��})}{P(\text{�۲���}|\text{ƫ��Ӳ��})}
P(�۲����Oƫ��Ӳ��)P(�۲����O��ƽӲ��)?
�����پ�һ������,������һöӲ��,���������Ϊ
p
1
p_1
p1?,�������Ϊ
p
2
p_2
p2?;
��������������öӲ��12��,�����Ľ��Ϊ:HHTHHTHHHTHT
���ǿ��Ժ����������öӲ�Ҳ����������ĸ���: p 1 ? p 1 ? p 2 ? p 1 ? p 1 ? p 2 ? p 1 ? p 1 ? p 1 ? p 2 ? p 1 ? p 2 p_1\cdot p_1 \cdot \color{red}p_2 \cdot \color{black}p_1 \cdot p_1 \cdot \color{red}p_2 \cdot \color{black}p_1 \cdot p_1 \cdot p_1 \cdot \color{red}p_2 \cdot \color{black}p_1 \cdot \color{red}p_2 p1??p1??p2??p1??p1??p2??p1??p1??p1??p2??p1??p2?
��������һöӲ��,����������ĸ���Ϊ q 1 q_1 q1?,�������Ϊ q 2 \color{red}q_2 q2?
��ô��ö�µ�Ӳ�Ҳ����������ĸ���Ϊ: q 1 ? q 1 ? q 2 ? q 1 ? q 1 ? q 2 ? q 1 ? q 1 ? q 1 ? q 2 ? q 1 ? q 2 q_1\cdot q_1 \cdot \color{red}q_2 \cdot \color{black}q_1 \cdot q_1 \cdot \color{red}q_2 \cdot \color{black}q_1 \cdot q_1 \cdot q_1 \cdot \color{red}q_2 \cdot \color{black}q_1 \cdot \color{red}q_2 q1??q1??q2??q1??q1??q2??q1??q1??q1??q2??q1??q2?
�����ڹ۲���,��
P ( �۲��� �O Ӳ��1 ) = p 1 N H p 2 N T P(\text{�۲���}|\text{Ӳ��1}) = p_1^{N_H}\color{red}p_2^{N_T} P(�۲����OӲ��1)=p1NH??p2NT??
P ( �۲��� �O Ӳ��2 ) = q 1 N H q 2 N T P(\text{�۲���}|\text{Ӳ��2}) = q_1^{N_H}\color{red}q_2^{N_T} P(�۲����OӲ��2)=q1NH??q2NT??
����
N
H
N_H
NH??��ʾ�۲�����Ϊ����Ĵ���,
N
T
N_T
NT??Ϊ����Ĵ��������Ǽ������ǵı�ֵ:
P
(
�۲���
�O
��ʵӲ��
)
P
(
�۲���
�O
Ӳ��2
)
=
p
1
N
H
p
2
N
T
q
1
N
H
q
2
N
T
(12)
\frac{P(\text{�۲���}|\text{��ʵӲ��})}{P(\text{�۲���}|\text{Ӳ��2})} = \frac{p_1^{N_H}\color{red}p_2^{N_T}}{q_1^{N_H}\color{red}q_2^{N_T}} \tag{12}
P(�۲����OӲ��2)P(�۲����O��ʵӲ��)?=q1NH??q2NT??p1NH??p2NT???(12)
�������ܼ������������Ӳ�ҵ������ԡ�
��ʵKLɢ�Ⱥ����������ƵĶ�������ô˵?
���ǰ���ʽ�ұ�ȡ����,������ʵ������
N
=
N
H
+
N
T
N=N_H+\color{red}N_T
N=NH?+NT?:
1
N
log
?
(
p
1
N
H
p
2
N
T
q
1
N
H
q
2
N
T
)
=
1
N
log
?
p
1
N
H
+
1
N
log
?
p
2
N
T
?
1
N
log
?
q
1
N
H
?
1
N
log
?
q
2
N
T
=
p
1
log
?
p
1
+
p
2
log
?
p
2
?
p
1
log
?
q
1
?
p
2
log
?
q
2
=
p
1
log
?
p
1
q
1
+
p
2
log
?
p
2
q
2
\begin{aligned} \frac{1}{N}\log \left( \frac{p_1^{N_H}\color{red}p_2^{N_T}}{q_1^{N_H}\color{red}q_2^{N_T}} \right) &= \frac{1}{N}\log p_1^{N_H} + \frac{1}{N}\log \color{red}p_2^{N_T} \color{black} - \frac{1}{N}\log q_1^{N_H} -\frac{1}{N}\log \color{red} q_2^{N_T} \\ &= p_1\log p_1 + p_2 \log \color{red}p_2 \color{black} - p_1 \log q_1 - \color{red}p_2 \color{black}\log \color{red}q_2 \\ &= p_1 \log \frac{p_1}{q_1} + \color{red}p_2 \color{black}\log \frac{\color{red}p_2}{\color{red}q_2} \end{aligned}
N1?log(q1NH??q2NT??p1NH??p2NT???)?=N1?logp1NH??+N1?logp2NT???N1?logq1NH???N1?logq2NT??=p1?logp1?+p2?logp2??p1?logq1??p2?logq2?=p1?logq1?p1??+p2?logq2?p2???
���� N H N = p 1 ???? N T N = p 2 \frac{N_H}{N}=p_1 \,\,\,\, \frac{\color{red}N_T}{N}=\color{red}p_2 NNH??=p1?NNT??=p2?������ p p p��һ�����ʷֲ�, q q q����һ�����ʷֲ�,��ʽ�Ӻ�KLɢ�ȵ�ʽ��һģһ����
������ͨ��������ʵ�ֲ�����Ȼֵ���Եڶ����ֲ�����Ȼֵ,��ȡ��һ���Ķ���,�͵õ���KLɢ�ȵı���ʽ��
���ǿ��Կ���,KLɢ����һ�ֺ����������ʷֲ�����ķ�ʽ,ͨ���۲�ڶ������ʷֲ�������һ�����ʷֲ������Ŀ����ԡ�
KLɢ�ȷdz����������ѧϰ�ij���,��Ϊ���ѧϰģ�ͻ������ǹ���Ϊ��֪��������ʵ�ֲ���ģ��
ʵ����,��������ʧ(cross entroy loss)�͵���KL��ʧ,��С�������ؾ�����С�������ֲ��ľ��롣
�����������½����صĶ��塣
������
������(Cross Entropy)��Ҫ�����������ʷֲ�֮��IJ����ԡ������ؿ�������������Ϊ��ʧ����,��:
H
(
P
?
�O
P
)
=
?
��
i
P
?
(
i
)
log
?
P
(
i
)
(13)
H(P^*|P)=- \sum_i P^*(i) \log P(i) \tag{13}
H(P?�OP)=?i��?P?(i)logP(i)(13)
����
P
?
P^*
P?��ʾ��ʵ�ֲ�;
P
P
P��ʾԤ��ֲ�;
i
i
i��ʾ�ֲ��е��������
KLɢ�Ⱥͽ�����
�����Ѿ��˽���KLɢ�Ⱥͽ�����,���DZ�С����������֮��Ĺ�ϵ��
����֪��,�����ؿ�����������Ԥ��ֲ�����ʵ�ֲ��IJ���(����)�����ǹ۲쵽��������������ʵ�ֲ�������,�������ǿ�����������KLɢ��:
D
K
L
(
P
?
�O
�O
P
)
=
D
K
L
(
P
?
(
y
�O
x
i
)
�O
�O
P
(
y
�O
x
i
;
��
)
(14)
D_{KL}(P^*||P) =D_{KL}\left ( P^* (y|x_i) || P(y|x_i;\theta\right) \tag{14}
DKL?(P?�O�OP)=DKL?(P?(y�Oxi?)�O�OP(y�Oxi?;��)(14)
����
P
?
P^*
P?����ʵ�ֲ�,
P
P
P�����ǵ�Ԥ��ֲ�;
x
i
x_i
xi?�ǵ�
i
i
i������,
y
y
y�����Ӧ�ı�ǩ;
��
\theta
����ģ�͵IJ�����
D
K
L
(
P
?
�O
�O
P
)
=
��
y
P
?
(
y
�O
x
i
)
log
?
P
?
(
y
�O
x
i
)
P
(
y
�O
x
i
;
��
)
=
��
y
P
?
(
y
�O
x
i
)
[
log
?
P
?
(
y
�O
x
i
)
?
log
?
P
(
y
�O
x
i
;
��
)
]
=
��
y
P
?
(
y
�O
x
i
)
log
?
P
?
(
y
�O
x
i
)
?
��
y
P
?
(
y
�O
x
i
)
log
?
P
(
y
�O
x
i
;
��
)
(15)
\begin{aligned} D_{KL}(P^*||P) &= \sum_y P^* (y|x_i) \log \frac{P^*(y|x_i)}{P(y|x_i;\theta)} \\ &=\sum_y P^* (y|x_i) \left [\log P^*(y|x_i) - \log P(y|x_i;\theta) \right] \\ &= \sum_y P^* (y|x_i)\log P^*(y|x_i) - \sum_y P^* (y|x_i) \log P(y|x_i;\theta) \\ \end{aligned} \tag{15}
DKL?(P?�O�OP)?=y��?P?(y�Oxi?)logP(y�Oxi?;��)P?(y�Oxi?)?=y��?P?(y�Oxi?)[logP?(y�Oxi?)?logP(y�Oxi?;��)]=y��?P?(y�Oxi?)logP?(y�Oxi?)?y��?P?(y�Oxi?)logP(y�Oxi?;��)?(15)
�۲��������յ�ʽ��,����
P
?
(
y
�O
x
i
)
log
?
P
?
(
y
�O
x
i
)
P^* (y|x_i)\log P^*(y|x_i)
P?(y�Oxi?)logP?(y�Oxi?)�����
��
\theta
����,ʵ��������ʵ�ֲ�����Ϣ��,��һ������;��
?
P
?
(
y
�O
x
i
)
log
?
P
(
y
�O
x
i
;
��
)
-P^* (y|x_i)\log P(y|x_i;\theta)
?P?(y�Oxi?)logP(y�Oxi?;��)����������Ϥ�Ľ����ص�ʽ�ӡ�
����������Ļ�,�������ǻ�һ��д��: D K L ( P ? �O �O P ) = ? S ( P ? ) + H ( P ? , P ) D_{KL}(P^*||P)= -S(P^*) + H(P^*,P) DKL?(P?�O�OP)=?S(P?)+H(P?,P), S ( P ? ) S(P^*) S(P?)�� P ? P^* P?����Ϣ��; H ( P ? , P ) H(P^*,P) H(P?,P)�ǽ�����,KLɢ�� = ������ - ��
���,������С�����ڲ���
��
\theta
����KLɢ��,���൱����С��ʽ
(
15
)
(15)
(15)�еĵڶ���,��:
arg
?
?
min
?
��
D
K
L
(
P
?
�O
�O
P
)
��
arg
?
?
min
?
��
?
��
i
P
?
(
y
�O
x
i
)
log
?
P
(
y
�O
x
i
;
��
)
(16)
\arg\,\min_{\theta}D_{KL}(P^*||P) \equiv \arg\,\min_{\theta} - \sum_i P^* (y|x_i) \log P(y|x_i;\theta) \tag{16}
arg��min?DKL?(P?�O�OP)��arg��min??i��?P?(y�Oxi?)logP(y�Oxi?;��)(16)
��
arg
?
?
min
?
��
D
K
L
(
P
?
�O
�O
P
)
��
arg
?
?
min
?
��
H
(
P
?
,
P
)
(17)
\arg\,\min_{\theta}D_{KL}(P^*||P) \equiv \arg\,\min_{\theta} H(P^*,P) \tag{17}
arg��min?DKL?(P?�O�OP)��arg��min?H(P?,P)(17)
���,�ڻ���ѧϰ��,����Ҫ����Ԥ��ģ�ͺ���ʵģ��֮��IJ��,����ʹ��KLɢ��,��KLɢ���е���Ϣ����һ���ֲ���,����ֻ��Ҫ��ע�����ؾͿ����ˡ�
����KLɢ�Ⱥ㲻С���������,�����ҵ���һ���ܺõ�ͼʾ:
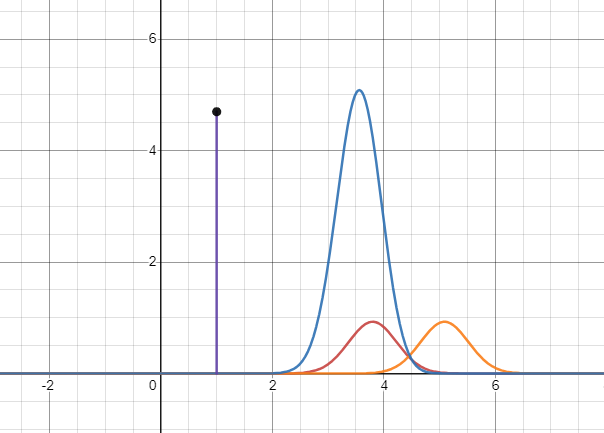
��ɫ���ߴ�����ʵ���ʷֲ�;��ɫ���ߴ���Ԥ����ʷֲ�;���ߴ�����ɫ�����µ����,�����������ֲ��Ľ����ء�
�����صĴ�С��Ԥ��ֲ�����ʵ�ֲ���ƫ��̶���ء�
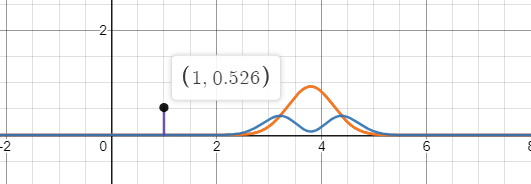
�������ֲ��ص�ʱ,��ʱ��������С,Ϊ��ʵ�ֲ�����Ϣ�ء�
��������ʧ
�ڻ���ѧϰ��,������Ҫ������ǩֵ y y y��Ԥ��ֵ y ^ \hat y y^?֮��IJ��,����֪��ֻ��Ҫ��ע�����ء�һ���ڻ���ѧϰ��ֱ���ý���������ʧ����������ģ�͡�
l
o
s
s
=
?
��
j
=
1
n
y
j
log
?
y
^
j
(18)
loss=-\sum_{j=1}^n y_j \log \hat y_j \tag{18}
loss=?j=1��n?yj?logy^?j?(18)
����
y
j
y_j
yj?����ʵ�����ı�ǩ;
y
^
j
\hat y_j
y^?j?��Ԥ��ֵ,ͨ����һ������;
n
n
n�Ƿ���ĸ���;���������Ե������������,���������������,��ô�����ؼ��㹫ʽΪ:
L
=
?
��
i
=
1
m
��
j
=
1
n
y
i
j
log
?
y
^
i
j
(19)
\mathcal L = -\sum_{i=1}^m \sum_{j=1}^n y_{ij} \log \hat y_{ij} \tag{19}
L=?i=1��m?j=1��n?yij?logy^?ij?(19)
����
m
m
m��������;
n
n
n�Ƿ�������
������
��һ����������,��������Ϊ
2
2
2,���Ƕ��������⡣������������,����
n
=
2
n=2
n=2,
y
1
=
1
?
y
2
y_1=1-y_2
y1?=1?y2?,
y
^
1
=
1
?
y
^
2
\hat y_1 = 1- \hat y_2
y^?1?=1?y^?2?,���Խ����ؿ��Լ�Ϊ:
l
o
s
s
=
?
[
y
1
log
?
y
^
1
+
(
1
?
y
1
)
log
?
(
1
?
y
^
1
)
]
(20)
loss = - \left[ y_1 \log \hat y_1 + (1-y_1)\log (1-\hat y_1) \right] \tag{20}
loss=?[y1?logy^?1?+(1?y1?)log(1?y^?1?)](20)
�������������Ľ�����Ϊ:
L
=
?
��
i
=
1
m
[
y
i
log
?
y
^
i
+
(
1
?
y
i
)
log
?
(
1
?
y
^
i
)
]
(21)
\mathcal L = - \sum_{i=1}^m \left [ y_i \log \hat y_i + (1-y_i)\log(1-\hat y_i) \right] \tag{21}
L=?i=1��m?[yi?logy^?i?+(1?yi?)log(1?y^?i?)](21)
ͨ�����ڶ���������,������Ϊ
1
1
1,����Ϊ
0
0
0�������ʽ�����������ֻ����һ�����ڡ�
�����
�������Ƕ��������,��������
n
��
3
n \geq 3
n��3�����������������������Ľ�������ʧ��Ϊʽ
(
19
)
(19)
(19):
L
=
?
��
i
=
1
m
��
j
=
1
n
y
i
j
log
?
y
^
i
j
\mathcal L = -\sum_{i=1}^m \sum_{j=1}^n y_{ij} \log \hat y_{ij}
L=?i=1��m?j=1��n?yij?logy^?ij?
�����б�Ҫָ������,���ڶ��������,��ǩֵһ����ö��ȱ���,Ԥ��ֵ�����֮ǰ�ᾭ��Softmaxת��Ϊ���ʷֲ���������������ʧֻ���עԤ����ȷ�����ĸ��ʡ�
��������ʹ�ô����дҲ�ȼƽ�ֱ�ۡ�
�������ͽ�����
����֪��,���Իع����ʧ�����Ǿ������,�����ع����ʧ����Ϊ��������ʧ��Ϊʲô��?
�ȿ����ع�Ϊʲô�ý�������ʧ�����Ǿ�����
���ع���ʵ�Ƿ�������,�������һ������,�����ؾ������ں������ʾ���ĺ���,����ѡ�ý�������ʧ������Ѹ���ֵ������һ����ֵ�Ļ�,Ҳ�����þ��������ǵ���Ϊʲô��?
���ǿ��ԴӾ������ͽ����صĺ���ͼ�����֡�
�Զ���������Ϊ��,�ȿ������صĺ���ͼ�Ρ�
import numpy as np
import matplotlib.pyplot as plt
def cross_entropy(y_hat, y):
return -np.log(y_hat) if y == 1 else -np.log(1 - y_hat)
y_hat = np.arange(0.01,1,0.01)
plt.plot(y_hat, cross_entropy(y_hat, 1), label='y=1')
plt.plot(y_hat, cross_entropy(y_hat, 0), label='y=0')
plt.legend()
plt.show()
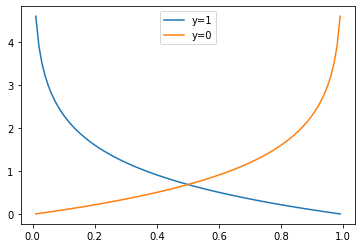
�������ߴ�����ʵ��ǩ y = 1 y=1 y=1ʱ�Ľ�������ʧ����ͼ��,���ߴ�����ʵ��ǩ y = 0 y=0 y=0ʱ��ͼ�Ρ����������Ԥ��ֵ,�����������ʧֵ��
���Կ���,�� y = 1 y=1 y=1ʱ(����),���Ԥ���Խ��ȷ(Ԥ��ֵ��1Խ��),����ʧ(�ͷ�)ԽС,��Խ�ӽ�0��λ��,��ʧԽ��
������,�� y = 0 y=0 y=0ʱ(����),���Ԥ���Խ��ȷ(Ԥ��ֵ��0Խ��),����ʧԽС,��Խ�ӽ�1��λ��,��ʧԽ��
����������,�� y = 1 y=1 y=1ʱ,Ԥ����Ϊ y ^ = 0.1 \hat y=0.1 y^?=0.1ʱ����ʧ:
> cross_entropy(0.1, 1)
2.3025850929940455
��Լ�� 2.3 2.3 2.3��
������������������ͼ��:
def mse(y_hat, y):
return (y - y_hat)**2
plt.plot(y_hat,mse(y_hat, 1) , label='y=1')
plt.plot(y_hat, mse(y_hat, 0), label='y=0')
plt.legend()
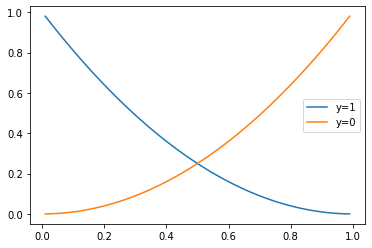
�������ߴ�����ʵ��ǩ y = 1 y=1 y=1ʱ�ľ��������ʧ����ͼ��,���ߴ�����ʵ��ǩ y = 0 y=0 y=0ʱ��ͼ�Ρ����������Ԥ��ֵ,�����������ʧֵ��
�����������ֵҲֻ�� 1.0 1.0 1.0,��������ͼ������Ҳû���ر����ݶȡ�
����Ҳ������,�� y = 1 y=1 y=1ʱ,Ԥ����Ϊ y ^ = 0.1 \hat y=0.1 y^?=0.1?ʱ����ʧ:
> mse(0.1, 1)
0.81
����ʧֵҲ����,���ѡ�þ��������Ϊ���ع����ʧ����,�ܿ���ѵ����������
�������Ǿ�������Ϊʲô���ع�Ҫѡ���ء�
�������������Իع�Ϊʲô��ѡ���ء�ֱ��˵����,������ʷֲ�Ϊ��˹�ֲ��������,���ý�������ʧ��ͬ�ڲ��þ��������ʧ�����֤���������ϲ��ҡ�
��������ʧ���ݶ�
�����Զ��������Ϊ��,�����˲���֮ǰ����һƪ����Softmax��Cross-entropy������
softmax����Ϊ:
y ^ i = e z i �� k = 1 K e z k \hat y_i = \frac{e^{z_i}}{\sum_{k=1}^K e^{z_k}} y^?i?=��k=1K?ezk?ezi??
����
K
K
K����������,��������
y
^
i
\hat y_i
y^?i?��ij�����
z
j
z_j
zj?�ĵ���,
?
y
^
i
?
z
j
=
?
e
z
i
��
k
=
1
K
e
z
k
?
z
j
\frac{\partial \hat y_i}{\partial z_j} = \frac{\partial \frac{e^{z_i}}{\sum_{k=1}^K e^{z_k}}}{\partial z_j}
?zj??y^?i??=?zj??��k=1K?ezk?ezi???
����Ҫ���������,�ֱ��� i = j i=j i=j�� i �� j i \neq j i��?=j���� i = j i=j i=jʱ, e z i e^{z_i} ezi?�� z j z_j zj?�ĵ���Ϊ e z i e^{z_i} ezi?,���� i �� j i \neq j i��?=jʱ,����Ϊ 0 0 0��
��
i
=
j
i = j
i=j,
?
y
^
i
?
z
j
=
e
z
i
?
��
k
=
1
K
e
z
k
?
e
z
i
?
e
z
j
(
��
k
=
1
m
e
z
k
)
2
=
e
z
i
��
k
=
1
m
e
z
k
?
e
z
i
��
k
=
1
m
e
z
k
?
e
z
j
��
k
=
1
m
e
z
k
=
y
^
i
?
y
^
i
2
=
y
^
i
(
1
?
y
^
i
)
\begin{aligned} \frac{\partial \hat y_i}{\partial z_j} &= \frac{e^{z_i}\cdot \sum_{k=1}^K e^{z_k} - e^{z_i} \cdot e^{z_j} }{(\sum_{k=1}^m e^{z_k})^2} \\ &= \frac{e^{z_i}}{\sum_{k=1}^m e^{z_k}} - \frac{e^{z_i}}{\sum_{k=1}^m e^{z_k}} \cdot \frac{e^{z_j}}{\sum_{k=1}^m e^{z_k}} \\ &= \hat y_i - \hat y_i^2 = \hat y_i(1 - \hat y_i) \end{aligned}
?zj??y^?i???=(��k=1m?ezk?)2ezi??��k=1K?ezk??ezi??ezj??=��k=1m?ezk?ezi???��k=1m?ezk?ezi???��k=1m?ezk?ezj??=y^?i??y^?i2?=y^?i?(1?y^?i?)?
��
i
��
j
i \neq j
i��?=j,
?
y
^
i
?
z
j
=
0
?
��
k
=
1
K
e
z
k
?
e
z
i
?
e
z
j
(
��
k
=
1
m
e
z
k
)
2
=
?
e
z
i
��
k
=
1
m
e
z
k
?
e
z
j
��
k
=
1
m
e
z
k
=
?
y
^
i
y
^
j
\begin{aligned} \frac{\partial \hat y_i}{\partial z_j} &= \frac{0 \cdot \sum_{k=1}^K e^{z_k} - e^{z_i} \cdot e^{z_j}}{(\sum_{k=1}^m e^{z_k})^2} \\ &= - \frac{e^{z_i}}{\sum_{k=1}^m e^{z_k}} \cdot \frac{e^{z_j}}{\sum_{k=1}^m e^{z_k}} \\ &= - \hat y_i \hat y_j \end{aligned}
?zj??y^?i???=(��k=1m?ezk?)20?��k=1K?ezk??ezi??ezj??=?��k=1m?ezk?ezi???��k=1m?ezk?ezj??=?y^?i?y^?j??
��ʧ����
L
L
LΪ:
L
=
?
��
k
y
k
log
?
y
^
k
L = -\sum_k y_k \log \hat y_k
L=?k��?yk?logy^?k?
���� y k y_k yk?����ʵ���,�൱��һ������,�������� L L L�� z j z_j zj?�ĵ���
? L ? z j = ? ? ( �� k y k log ? y ^ k ) z j = ? ? ( �� k y k log ? y ^ k ) ? y ^ k ? y ^ k ? z j = ? �� k y k 1 y ^ k ? y ^ k z j = ( ? y k ? y ^ k ( 1 ? y ^ k ) 1 y ^ k ) k = j ? �� k �� j y k 1 y ^ k ( ? y ^ k y ^ j ) = ? y j ( 1 ? y ^ j ) ? �� k �� j y k ( ? y ^ j ) = ? y j + y j y ^ j + �� k �� j y k ( y ^ j ) = ? y j + �� k y k ( y ^ j ) = ? y j + y ^ j = y ^ j ? y j \begin{aligned} \frac{\partial L}{\partial z_j} &= \frac{\partial -(\sum_k y_k \log \hat y_k)}{z_j}\\ &= \frac{\partial -(\sum_k y_k \log \hat y_k)}{\partial \hat y_k} \frac{\partial \hat y_k}{\partial z_j} \\ &= -\sum_k y_k \frac{1}{\hat y_k} \frac{\partial \hat y_k}{z_j} \\ &= \left(-y_k \cdot \hat y_k(1 - \hat y_k) \frac{1}{\hat y_k} \right)_{k=j} - \sum_{k \neq j} y_k \frac{1}{\hat y_k} (-\hat y_k \hat y_j) \\ &= - y_j (1 -\hat y_j) - \sum_{k \neq j} y_k (-\hat y_j) \\ &= - y_j + y_j \hat y_j + \sum_{k \neq j} y_k (\hat y_j) \\ &= - y_j + \sum_{k} y_k (\hat y_j) \\ &= - y_j +\hat y_j \\ &= \hat y_j -y_j \end{aligned} ?zj??L??=zj???(��k?yk?logy^?k?)?=?y^?k???(��k?yk?logy^?k?)??zj??y^?k??=?k��?yk?y^?k?1?zj??y^?k??=(?yk??y^?k?(1?y^?k?)y^?k?1?)k=j??k��?=j��?yk?y^?k?1?(?y^?k?y^?j?)=?yj?(1?y^?j?)?k��?=j��?yk?(?y^?j?)=?yj?+yj?y^?j?+k��?=j��?yk?(y^?j?)=?yj?+k��?yk?(y^?j?)=?yj?+y^?j?=y^?j??yj??
�����õ��� �� k y k = 1 \sum_{k} y_k = 1 ��k?yk?=1