目录
2.1 Consistency Regularization(一致性正则)
??2.2 Entropy Minimization(熵最小化)
2.3 Traditional Regularization(传统正则化)
?4.1 Implementation details(实验的细节)
4.2 Semi-Supervised Learning(半监督学习)
本周完成的计划
- 读论文《MixMatch: A Holistic Approach to Semi-Supervised Learning》
- 在cifar10数据集上使用250个label,复现MixMatch代码,查看效果
- 复习大数据,参加考试
论文阅读
MixMatch: A Holistic Approach to Semi-Supervised Learning(MixMatch:一种半监督学习的整体方法)
?Abstract(摘要)
半监督学习已被证明是一种利用未标记数据来减轻对大型标记数据集的依赖的强大范例。在这项工作中,我们整合了目前主流的半监督学习方法,产生了一种新的算法MixMatch,该算法对数据扩充的未标记样本猜测低熵标签,并使用MixUp算法。MixMatch在许多数据集和标记数据量中混合标记和未标记的数据,获得了最先进的结果。例如,在具有250个标签的CIFAR-10上,我们将错误率降低了4倍(从38%降低到11%),在STL-10上降低了2倍。
1. Introduction(介绍)
最近在训练大型深度神经网络方面取得的成功,在很大程度上要归功于大型标签数据集的存在。然而,收集标记的数据对于许多学习任务来说是昂贵的,因为它必然涉及专业知识。这一点最好的例证可能是医疗任务,在医疗任务中,测量需要昂贵的机器,而标签是从多名人类专家那里提取的耗时分析的成果。此外,数据标签可能包含私有信息。相比之下,在许多任务中,获取未标记数据要容易得多,成本也低得多。
半监督学习寻求通过允许模型利用未标记数据来在很大程度上减轻对标记数据的需求。最近的许多半监督学习方法增加了一个损失项,该损失项是在未标记的数据上计算的,并鼓励模型更好地推广到不可见的数据。在最近的工作中,这种损失项属于三类之一:熵最小化鼓励模型对未标记的数据输出有信心的预测;一致性正则化-鼓励模型在其输入受到扰动时产生相同的输出分布;以及通用正则化-鼓励模型很好地推广,避免过度拟合训练数据。
在本文中,我们介绍了一种SSL算法MixMatch,它引入了单一损失,完美地统一了半监督学习的这些主要方法。简而言之,MixMatch为未标记的数据引入了一个统一的损失项,它可以无缝地降低熵,同时保持一致性,并与传统的正则化技术保持兼容。
2. Related Work(相关工作)
2.1 Consistency Regularization(一致性正则)
一致性规则化将数据扩充应用于半监督学习,它利用分类器应该为未标记的样本输出相同的类分布的思想,即使在该样本已经被扩充之后也应该输出相同的类分布。
请注意,Augment(X)是一个随机变换,所以方程(1)中的两项不完全相同。MixMatch通过对图像使用标准数据增强(随机水平翻转和裁剪),实现一致性正则化。
?2.2 Entropy Minimization(熵最小化)
在许多半监督学习方法中,一个共同的基本假设是分类器的决策边界不应该穿过边缘数据分布的高密度区域。实现这一点的一种方法是要求分类器对未标记的数据输出低熵预测。MixMatch还通过对未标记数据的目标分布使用“锐化”函数来隐式地实现熵最小化,
2.3 Traditional Regularization(传统正则化)
正则化是指对模型施加约束以使其更难记忆训练数据的一般方法,因此有望使其更好地推广到看不见的数据。我们使用权重衰减来惩罚模型参数的L2范数。
3. MixMatch
在这一部分中,我们介绍了我们提出的半监督学习方法MixMatch。MixMatch是一种“整体”(holistic)方法,它结合了第2节中讨论的主要SSL范例的思想和组件。给定一批![]() 带有One Hot 标签的样本和一批大小相等的未标记样本
带有One Hot 标签的样本和一批大小相等的未标记样本![]() ,MixMatch将生成一批已增强的标记样本
,MixMatch将生成一批已增强的标记样本![]() 和一批已增强的未标记样本
和一批已增强的未标记样本![]() ,这些已增强的未标记样本带有“guessed”的标签。更正式地说,半监督学习的组合损失L定义为:
,这些已增强的未标记样本带有“guessed”的标签。更正式地说,半监督学习的组合损失L定义为:
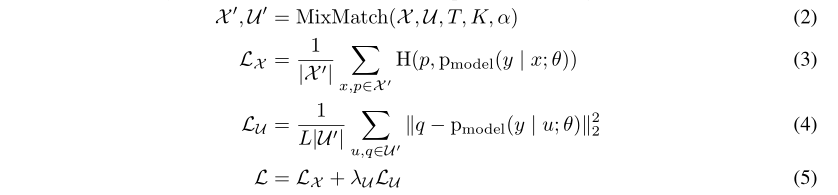
?3.1 Data Augmentation(数据增强)
?与许多SSL方法中的典型情况一样,我们对已标记和未标记的数据都使用数据扩充。
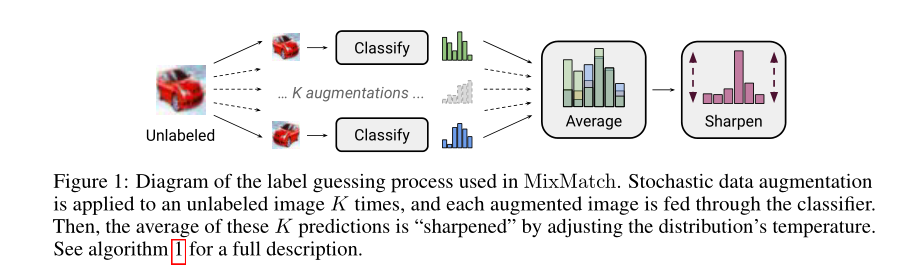
我们对一个Batch中的有标签数据做一次数据增广,对一个Batch中的无标签数据做K次数据增广

?我们使用单独的数据增强为每个无标签数据生成“guessed label” qb ,当然还使用了一些其它技巧,下面详细说明。
3.2 Label Guessing(标签猜测)
对于U中每个未标记的样本,MixMatch会使用模型的预测为每个未标记的样本生成一个“猜测”,要做到这一点,我们计算模型K次预测的class的分布的平均值
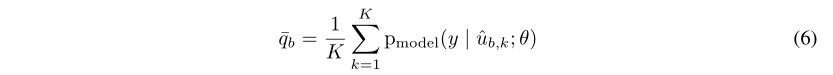
?![]()
?在生成标签猜测时,我们执行了另外一个步骤,灵感来自于半监督学习中熵最小化的成功(在第2.2节中讨论),我们应用锐化函数来降低标签分布的熵,降低温度会鼓励模型产生更低熵的预测。
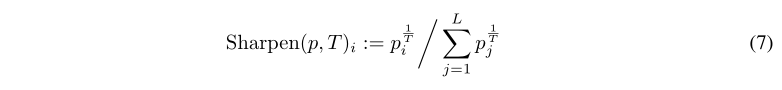
![]()
3.3 MixUp(混合)
?我们将有标签的示例和无标签的示例与标签猜测(如第3.2节所述生成的)混合在一起。
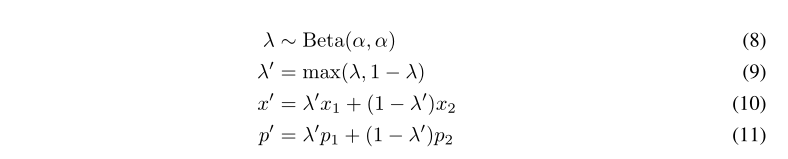
考虑到有标签和无标签的数据连接在同一批次中,我们需要保持批次的顺序,以便适当地计算单个损失分量。?这是通过等式(9)来实现的,这确保了x' 比x2更接近x1。要使用Mixup,我们首先将所有增强的带标签的样本和所有未带标签的样本及其猜测的标签收集到,
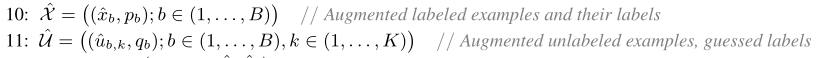
?然后,我们将这些集合组合在一起,并将结果进行Shuffle操作生成W
![]()
??????然后,我们进行Mixup操作。
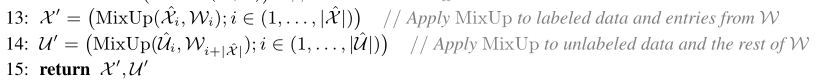
?3.4 Loss Function(损失函数)
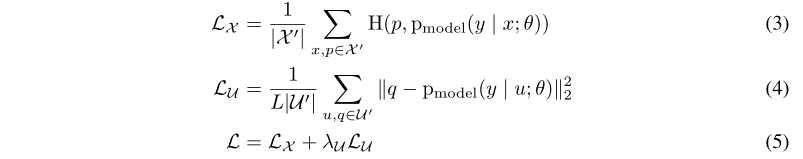
最后,回顾一下MixMatch的整体训练流程图:

?4 Experiments(实验)
?我们测试了MixMatch在标准SSL基准的有效性,我们的消融实验梳理了MixMatch的每个组件的贡献。
?4.1 Implementation details(实验的细节)
?除非另外说明,在所有实验中,我们都使用“Wide ResNet-28”模型,首先,我们使用参数的指数移动平均来评估模型,衰减率为0.999,其次,对于Wide ResNet-28模型,我们在每次更新时应用0.0004的权重衰减。
4.2 Semi-Supervised Learning(半监督学习)
首先,我们评估了MixMatch在四个标准基准数据集的有效性:CIFAR-10和CIFAR-100、SVHN和STL-10。评估前三个数据集的半监督学习的标准做法是将大部分数据集视为未标记的,并使用一小部分作为已标记的数据。
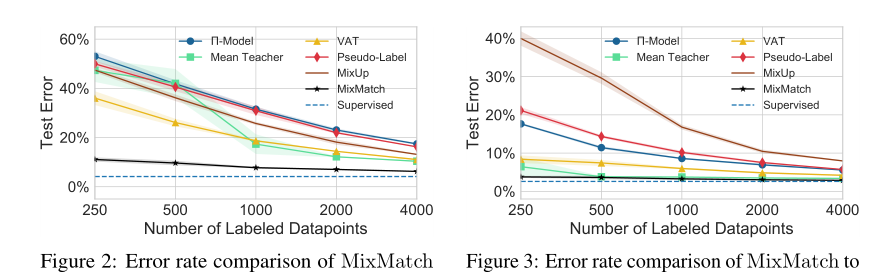
?图2是不同范围的有标签数据性能在Cifar10数据集上的比较,从250个label到4000个label分别比较各个基准模型与MixMatch的性能。
图3是不同范围的有标签数据性能在SVHN数据集上的比较,可以看出我们只使用了250个label的MixMatch的半监督和使用了73257个label的全监督(蓝色虚线那个Supervised)居然相差不大,可以看出MixMatch取得的惊人效果!!!!
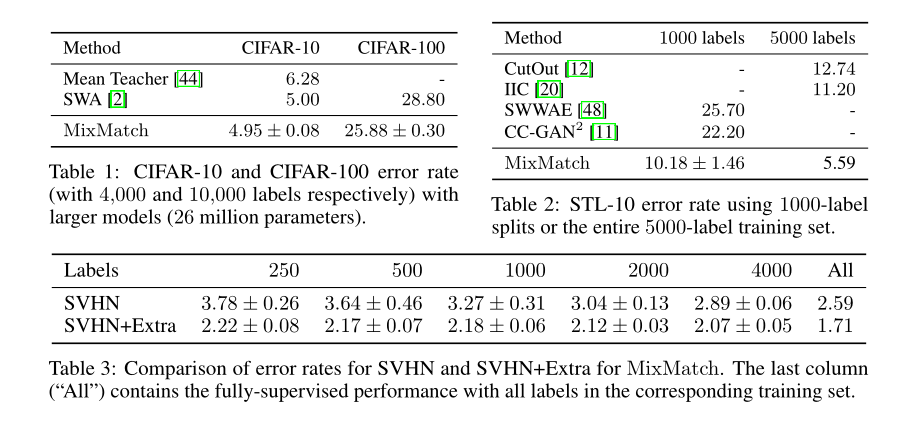
上面表3中,最有趣的一点就是,使用250个label的MixMatch半监督模型在SVHN+Extra数据集上表现比使用73257个label的在完全监督模型SVHN数据集上的表现还要好!!!
4.3??Ablation Study(消融实验)

在CIFAR10上分别使用了250个label和4000个label来做消融实验,找出最能影响MixMatch准确率的组件,可以看出使用了temperature sharpening和混合的Mixup方法对准确率影响最大。
5 Conclusion(结论)
我们介绍了MixMatch,这是一种半监督学习方法,它结合了当前主流SSL范例的思想和组件。通过对半监督学习学习的广泛实验,我们发现在我们研究的所有环境下,MixMatch比其他方法都有显著的性能提高,通常可以降低两个或两个以上的错误率。
论文复现的代码?
网络结构文件model.py
import torch
import torchvision
from torch import nn
from config import HP
class WideResnet50_2(nn.Module):
def __init__(self):
super(WideResnet50_2, self).__init__()
resnet = torchvision.models.wide_resnet50_2(pretrained=False)
last_fc_dim = resnet.fc.in_features # defaut imagenet, 1000
fc = nn.Linear(in_features=last_fc_dim, out_features=HP.classes_num)
resnet.fc = fc
self.wideresnet4cifar10 = resnet
def forward(self, input_x):
return self.wideresnet4cifar10(input_x)
自定义的损失文件loss.py
import torch
import torch.nn.functional as F
from torch import nn
class MixUpLoss(nn.Module):
def __init__(self):
super(MixUpLoss, self).__init__()
def forward(self, output_x, trg_x, output_u, trg_u):
"""
loss function: eq. (2) - (4)
:param output_x: mixuped x output: [N, 10]
:param trg_x: trg_x: mixuped targ: [N, 10]
:param output_u: mixuped u output [2*N, 10]
:param trg_u: mixuped target u output: [2*N, 10]
:return:Lx, Lu
"""
Lx = -torch.mean(torch.sum(F.log_softmax(output_x, dim=-1)*trg_x, dim=-1)) # cross-entropy, supervised loss
Lu = F.mse_loss(output_u, trg_u) # consistency reg
return Lx, Lu超参数文件config.py
# ################################################################
# HyperParameters
# ################################################################
# semi-supervised learning:
# 1. model structure
# 2. hype setting are important!
class Hyperparameters:
# ################################################################
# Data
# ################################################################
device = 'cuda' # cuda for training, cpu/cuda for inference
classes_num = 10 # cifar10
n_labeled = 250 # total labeled data number
seed = 1234
# ################################################################
# Model
# ################################################################
T = 0.5 # sharpen temperature
K = 2 # agument K
alpha = 0.75 # beta sample hype
lambda_u = 75. # consistency loss weight
# ################################################################
# Exp
# ################################################################
batch_size = 8
init_lr = 0.002
epochs = 1000
verbose_step = 300
save_step = 300
HP = Hyperparameters()工具文件util.py
包括论文的几个重要提升的方法:EMA、label guessing、sharpen、mixup等算法
import torch
import numpy as np
# make training more stable
class WeightEMA:
def __init__(self, model, ema_model, alpha=0.999):
self.model = model
self.ema_model = ema_model
self.alpha = alpha
self.params = list(model.state_dict().values())
self.ema_params = list(ema_model.state_dict().values())
self.weight_decacy = 0.0004
for param, ema_param in zip(self.params, self.ema_params):
param.data.copy_(ema_param)
def step(self):
for param, ema_param in zip(self.params, self.ema_params):
if ema_param.dtype == torch.float32: # model weights only!
ema_param.mul_(self.alpha)
ema_param.add_(param*(1-self.alpha))
# apply weight
param.mul_((1-self.weight_decacy))
def lambda_rampup(step, MAX_STEP=1e6, max_v=75):
"""
3.5 Hyperparameters: rampup
:param step: training step
:param MAX_STEP: max step
:param max_v: max value of lambda_u
:return: current value of lambda_u
"""
return np.clip(a=max_v*(step/MAX_STEP), a_min=0., a_max=max_v)
# label guessing = post distribution average + shrarpen
def label_guessing(out_u, out_u2):
"""
label guessing: eq. (6), K=2(default) as the paper said
:param out_u: [N, 10], model output(logits output)
:param out_u2: [N, 10]
:return: average label guessing, [N, 10]
[[0.22, 0.32......], => sum = 1.
[0.01, 0.3, 0.03...], => sum = 1.
....]
"""
q = (torch.softmax(out_u, dim=-1) + torch.softmax(out_u2, dim=-1)) / 2.
# algorithm 1, line 7
return q
def sharpen(p, T):
"""
sharpen: eq. (7), algorithm 1 line 8
:param p: post distribution: [N, 10]
[[0.22, 0.32......], => sum = 1.
[0.01, 0.3, 0.03...], => sum = 1.
....]
:param T: temperature
:return: sharpened result
"""
p_power = torch.pow(p, 1./T)
return p_power / torch.sum(p_power, dim=-1, keepdim=True) # [N , 10]
def mixup(x, u, u2, trg_x, out_u, out_u2, alpha=0.75):
"""
mixup: eq. (8)-(11), algorithm: Line12-Line14
:param x: labeled x, [N, 3, H, W]
:param u: the first unlabeled data, [N, 3, H, W]
:param u2: the second unlabeled data, [N, 3, H, W]
:param trg_x: labeled x target(y),[N, ]=[0, 7, 8...]
:param out_u: q_b, after lable guessing
:param out_u2: q_b
:param alpha: Beta hype
:return: mixuped result: x: [3*N, 3, H, W], y: [3*N, 10]
"""
batch_size = x.size(0) # batch size = HP.batch_size
n_classes = out_u.size(1) # classes number: 10
device = x.device
# [0.1,0.3.0.01.....] dim=10
# [0., 0.,0., 0.,0., 0.,0., 0.,1., 0.,] dim=10
# target x back to onehot
trg_x_onehot = torch.zeros(size=(batch_size, n_classes)).float().to(device)
# [0, 0., 0., 0., 0., 0, 0., 0., 0., 0.,]
# trg_x [7]
# [0, 0., 0., 0., 0., 0, 0., 1., 0., 0.,]
trg_x_onehot.scatter_(1, trg_x.view(-1, 1), 1.)
# mixup
x_cat = torch.cat([x, u, u2], dim=0)
trg_cat = torch.cat([trg_x_onehot, out_u, out_u2], dim=0)
n_item = x_cat.size(0) # N*3
lam = np.random.beta(alpha, alpha) # eq. (8)
lam_prime = max(lam, 1-lam) # eq. (9)
rand_idx = torch.randperm(n_item) # a rand index sequence: [0,2, 1], [1, 0, 2]
x_cat_shuffled = x_cat[rand_idx] # x2
trg_cat_shuffled = trg_cat[rand_idx]
x_cat_mixup = lam_prime * x_cat + (1-lam_prime) * x_cat_shuffled # eq. (9)
trg_cat_mixup = lam_prime * trg_cat + (1- lam_prime) * trg_cat_shuffled # eq. (10)
return x_cat_mixup, trg_cat_mixup
def accuracy(output, target, topk=(1, )):
"""
topk acc
:param output: [N, 10]
:param target: [N, ]
:param topk: top1,top3, top5
:return: acc list
"""
maxk = max(topk) # max k, topk=(1, 3, 5)
batch_size = target.size(0)
_, pred = output.topk(maxk, 1, True, True)
pred = pred.t() # [maxk, N]
correct = pred.eq(target.view(1, -1).expand_as(pred))
res = []
for k in topk:
correct_k = correct[:k].reshape(-1).float().sum(0)
res.append(correct_k.mul_(100./batch_size))
return res # [50, 85, 99]
训练文件train.py
# mixmatch training process
import os
import random
from argparse import ArgumentParser
import torch.cuda
import torch.nn as nn
import torch.optim as optim
import torch.utils.data as data
import torchvision.transforms as transforms
from model import WideResnet50_2
import dataset.cifar10 as dataset
from utils import *
from tensorboardX import SummaryWriter
from config import HP
from loss import MixUpLoss
# seed init
torch.manual_seed(HP.seed)
torch.cuda.manual_seed(HP.seed)
random.seed(HP.seed)
np.random.seed(HP.seed)
# stochastic transformation for training
transform_train = transforms.Compose([
dataset.RandomPadandCrop(32),
dataset.RandomFlip(),
dataset.ToTensor(),
])
# inference / validation / test
transform_val = transforms.Compose([
dataset.ToTensor(),
])
# $$$$$$ Algorithm Line1-Line6 $$$$$$
# labeled dataloader / 2 unlabeled dataloaders / validation dataloader
train_labeled_set, train_unlabeled_set, val_set, test_set = dataset.get_cifar10('./data',
n_labeled=HP.n_labeled,
transform_train=transform_train,
transform_val=transform_val)
labeled_trainloader = data.DataLoader(train_labeled_set, batch_size=HP.batch_size, shuffle=True, drop_last=True)
unlabeled_trainloader = data.DataLoader(train_unlabeled_set, batch_size=HP.batch_size, shuffle=True, drop_last=True)
val_loader = data.DataLoader(val_set, batch_size=HP.batch_size, shuffle=False, drop_last=False)
logger = SummaryWriter('./log')
# shadow ema model
def new_ema_model():
model = WideResnet50_2()
model = model.to(HP.device)
for param in model.parameters():
param.detach_() # disable gradient trace
return model
# save func
def save_checkpoint(model_, ema_model_, epoch_, optm, checkpoint_path):
save_dict = {
'epoch': epoch_,
'model_state_dict': model_.state_dict(),
'ema_model_state_dict': ema_model_.state_dict(),
'optimizer_state_dict': optm.state_dict(),
}
torch.save(save_dict, checkpoint_path)
# evaluation func: loss(CE),
def evaluate(model_, val_loader_, crit):
model_.eval()
sum_loss = 0.
acc1, acc5 = 0., 0.
with torch.no_grad():
for batch in val_loader_:
# load eval data
inputs_x, trg_x = batch
inputs_x, trg_x = inputs_x.to(HP.device), trg_x.long().to(HP.device)
out_x = model_(inputs_x) # model inference
top1, top5 = accuracy(out_x, trg_x, topk=(1, 5))
acc1 += top1
acc5 += top5
sum_loss += crit(out_x, trg_x)
loss = sum_loss / len(val_loader_)
acc1 = acc1 / len(val_loader_)
acc5 = acc5 / len(val_loader_)
model_.train()
return acc1, acc5, loss
# train func
def train():
parser = ArgumentParser(description='Model Training')
parser.add_argument(
'--c',
default=None,
type=str,
help='train from scratch or resume from checkpoint'
)
args = parser.parse_args()
# new models: model/ema_model and WeightEMA instance
model = WideResnet50_2()
model = model.to(HP.device)
ema_model = new_ema_model()
model_ema_opt = WeightEMA(model, ema_model)
# loss
criterion_val = nn.CrossEntropyLoss() # for eval
criterion_train = MixUpLoss() # for training
opt = optim.Adam(model.parameters(), lr=HP.init_lr, weight_decay=0.001) # optimizer with L2 regular
start_epoch, step = 0, 0
if args.c:
checkpoint = torch.load(args.c)
model.load_state_dict(checkpoint['model_state_dict'])
ema_model.load_state_dict(checkpoint['ema_model_state_dict'])
opt.load_state_dict(checkpoint['optimizer_state_dict'])
start_epoch = checkpoint['epoch']
print('Resume From %s.' % args.c)
else:
print('Training from scratch!')
model.train()
eval_loss = 0.
n_unlabeled = len(unlabeled_trainloader) # as regist count for trainin step
best_acc = 0.0
# train loop
for epoch in range(start_epoch, HP.epochs):
print('Start epoch: %d, Step: %d' % (epoch, n_unlabeled))
for i in range(n_unlabeled): # one unlabeled data turn as an epoch
# inputs_x: [N, 3, H, W], trg_x: [N,]
inputs_x, trg_x = next(iter(labeled_trainloader)) # get one batch from alabeled dataloader
# inputs_u / inputs_u2 -> [N, 3, H, W]
(inputs_u, inputs_u2), _ = next(iter(unlabeled_trainloader))
inputs_x, trg_x, inputs_u, inputs_u2 = inputs_x.to(HP.device), trg_x.long().to(HP.device), inputs_u.to(HP.device), inputs_u2.to(HP.device)
# $$$$$$ Algorithm Line7-Line8 $$$$$$: Label Guessing
with torch.no_grad():
out_u = model(inputs_u) # Aug K=1, inference [N, 10]
out_u2 = model(inputs_u2) # Aug K=2, inference [N, 10]
q = label_guessing(out_u, out_u2) # average post distribution [N, 10]
q = sharpen(q, T=HP.T) # [N, 10],
# $$$$$$ Algorithm Line10-Line15 $$$$$$: Label Guessing
# mixuped_x: [3*N, 3, H, W], mixuped_out: [3*N, 10]
mixuped_x, mixuped_out = mixup(x=inputs_x, u=inputs_u, u2=inputs_u2, trg_x=trg_x, out_u=q, out_u2=q)
# model forward
mixuped_logits = model(mixuped_x) # [3*N, 10]
logits_x = mixuped_logits[:HP.batch_size] # [N, 10]
logits_u = mixuped_logits[HP.batch_size:] # [2*N, 10]
# eq. (2) - (5)
loss_x, loss_u = criterion_train(logits_x, mixuped_out[:HP.batch_size], logits_u, mixuped_out[HP.batch_size:])
loss = loss_x + lambda_rampup(step, max_v=HP.lambda_u) * loss_u # eq. (5)
logger.add_scalar('Loss/Train', loss, step)
opt.zero_grad()
loss.backward()
opt.step()
model_ema_opt.step()
if not step % HP.verbose_step: # evaluation
acc1, acc5, eval_loss = evaluate(model, val_loader, criterion_val)
logger.add_scalar('Loss/Dev', eval_loss, step)
logger.add_scalar('Acc1', acc1, step)
logger.add_scalar('Acc5', acc5, step)
# if not step % HP.save_step: # save model
# model_path = 'model_%d_%d.pth' % (epoch, step)
# save_checkpoint(model, ema_model, epoch, opt, os.path.join('./model_save', model_path))
print('Epcoh: [%d/%d], step: %d, Train Loss: %.5f, Dev Loss: %.5f, Acc1: %.3f, Acc5: %.3f'%
(epoch, HP.epochs, step, loss.item(), eval_loss, acc1, acc5))
step += 1
logger.flush()
if acc1 > best_acc:
best_acc = acc1
model_path = 'model_%d_%d.pth' % (epoch, step)
save_checkpoint(model, ema_model, epoch, opt, os.path.join('./model_save', model_path))
logger.close()
if __name__ == '__main__':
train()实验超参数
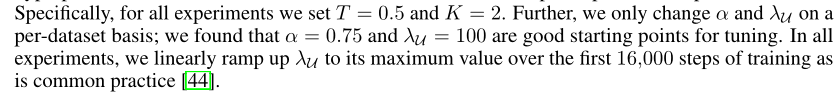
实验超参数说明,论文中给出的锐化温度T=0.5,K则数据增强K=2,,即进行的是两则数据增强,alpha参数设置为0.75,λu=100,都在配置文件HyperMeter.py文件中。
训练结果
?论文中给出的在CIFAR10数据集中使用250个label训练的结果
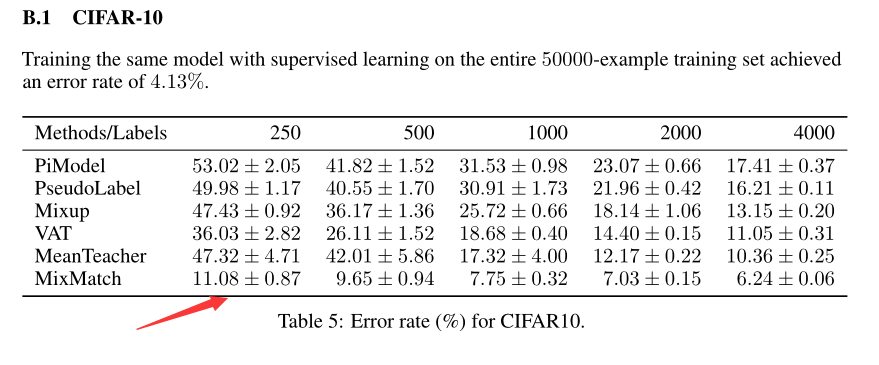
?使用MixMatch,250个label训练的错误率是11.08-0.87~11.08+0.87之间,也就是准确率在88.05~89.79左右。
自己跑的结果:这是10分类的混淆矩阵的结果,这是使用CIFAR10数据集250个label进行训练ed
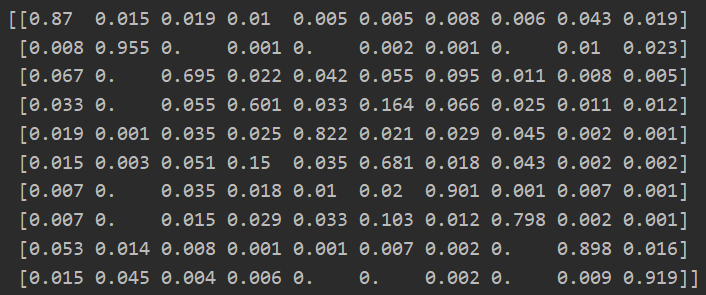
目前训练的准确率结果,最好的top-1-acc是0.8178,论文是能训练到88.05~89.79左右的准确率,我训练完等看看

本周工作总结?
学习的这篇半监督MixMatch论文,主要其主要是将之前几篇半监督论文的优点结合起来了,论文的主要使用的Mixup(混合)、Guessing label(猜测标签)、K data augmentation(K则数据增强)和Shapening(锐化)等操作对应了半监督学习中的一致性正则、熵最小化、通用正则化等,使得模型利用无标注数据,增强自己的泛化能力。