支持向量机是监督式学习算法,主要应用于分类,它的目的是寻找一个超平面对样本进行分割,分割的原则是间隔最大化。
(1)当训练数据线性可分时,通过硬间隔最大化,学习一个线性分类器,即线性可分支持向量机;
(2)当训练数据近似线性可分时,通过软间隔最大化,学习一个线性分类器,即线性支持向量机;
(3)当训练数据线性不可分时,通过核技巧(将低维数据映射到高维空间的办法)或软间隔最大化,学习一个线性分类器,即非线性支持向量机。
使用支持向量机对wine数据集进行分类
1、导入数据集(加载scikit-learn自带的数据集wine)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn import svm,datasets
from sklearn.model_selection import train_test_split
wine=datasets.load_wine() # 加载wine数据集
print('wine.data的形状为:',wine.data.shape)
print('wine.target的形状为:',wine.target.shape)
print('wine.target的特征名称为:',wine.target_names)
我们可以看到,wine数据集有13个特征、178个样本和3个类别。
2、拆分数据集(训练集和测试集)
x=wine.data
y=wine.target
# 数据集拆分为训练集和测试集
x_train,x_test,y_train,y_test=train_test_split(x,y,train_size=0.8,random_state=42)
print('拆分后训练集特征集的形状为:',x_train.shape)
print('拆分后训练集目标集的形状为',y_train.shape)
print('拆分后测试集特征集的形状为:',x_test.shape)
print('拆分后测试集目标集的形状为',y_test.shape) 使用train_test_split()方法将数据集拆分为训练集和测试集,通过调节train_size的值来改变训练集和测试集的样本量,此处以0.8的比例将数据集x和目标集y拆分为训练集和测试集x_train,x_test,y_train,y_test,即训练集样本数量是142个,测试集样本数量是36个。
使用train_test_split()方法将数据集拆分为训练集和测试集,通过调节train_size的值来改变训练集和测试集的样本量,此处以0.8的比例将数据集x和目标集y拆分为训练集和测试集x_train,x_test,y_train,y_test,即训练集样本数量是142个,测试集样本数量是36个。
3、使用核函数预测结果(4种核函数)及可视化
分别训练线性核、多项式核、径向基核和sigmoid核这4种核函数的支持向量机分类器,将模型训练、预测、可视化放在一个循环体中进行。
kernels=['linear','poly','rbf','sigmoid']
for kernel in kernels: # 循环体
clf_svm=svm.SVC(kernel=kernel,gamma=2) # 训练向量机
clf_svm.fit(x_train,y_train) # 调用训练好的向量机
y_pred=clf_svm.predict(x_test) # 预测结果
plt.rcParams['font.sans-serif']='SimHei' # 设置字体为SimHei以显示中文
plt.rcParams['axes.unicode_minus']=False # 坐标轴刻度显示负号
plt.figure(figsize=(10,4))
plt.rc('font',size=14) # 设置图中字号的大小
plt.scatter(range(len(y_test)),y_test,marker='o')
plt.scatter(range(len(y_pred)),y_pred+0.1,marker='*') # 将类标签错开
plt.xlabel('样本索引')
plt.ylabel('类标签')
plt.legend(['实际类标签','预测类标签'])
title=kernel+'函数对测试集的预测结果与实际目标变量对比'
plt.title(title)
g=plt.show()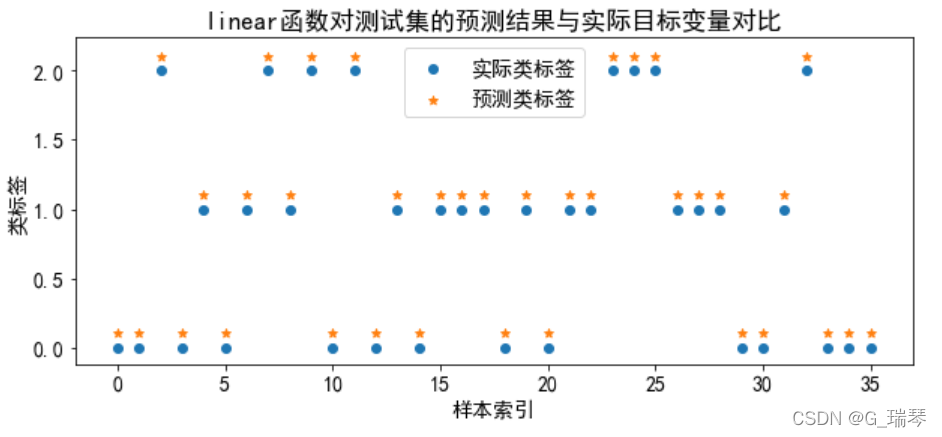
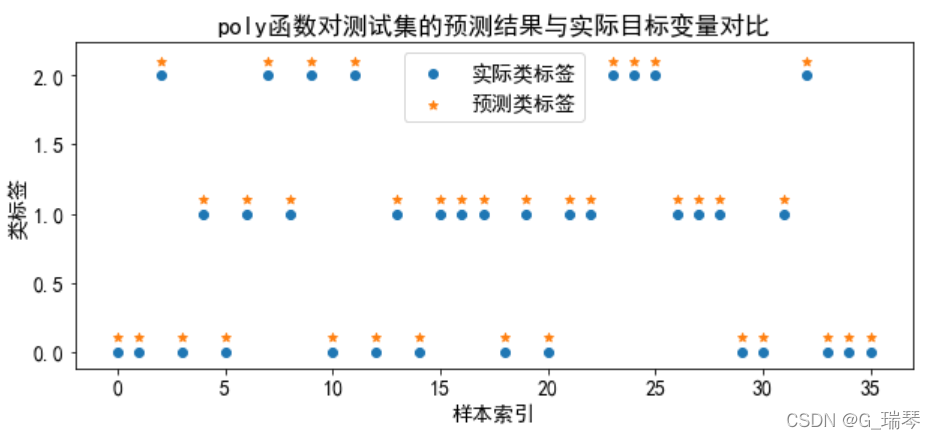
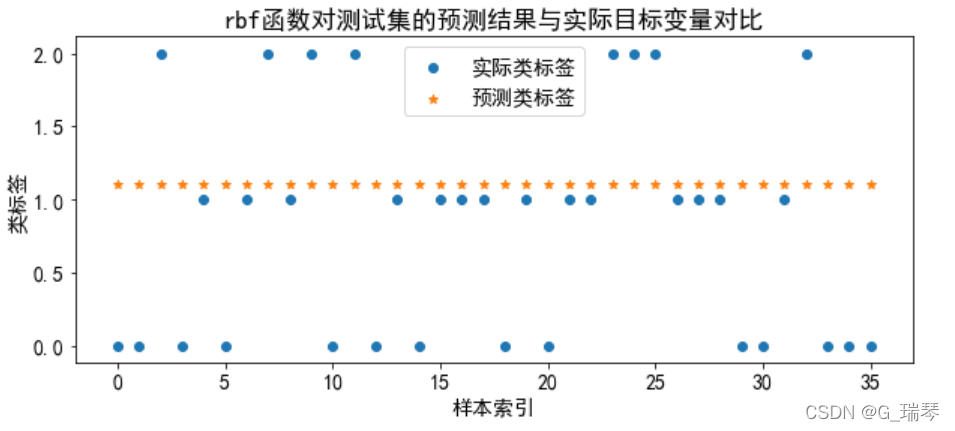
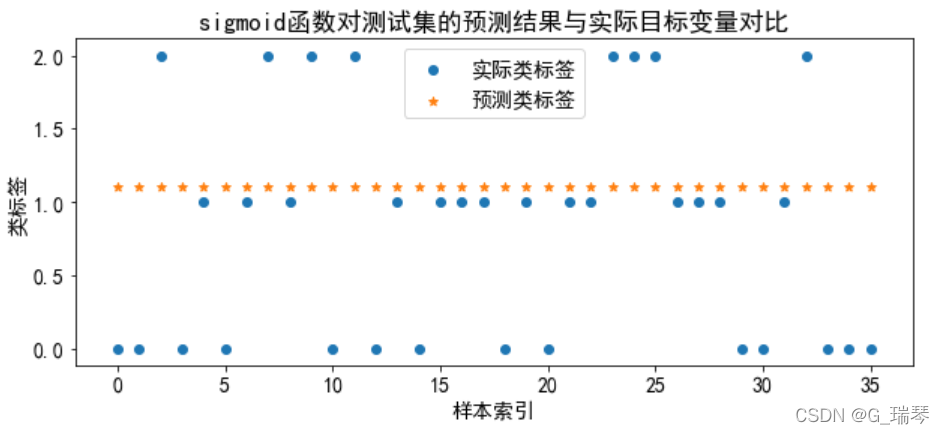
从图中我们得知,线性核和多项式核分类的准确率高;径向基核和sigmoid核的分类准确率低,不适合对wine数据集进行分类。