一、heatmap
热力图以颜色的明亮程度来显示数据的密集程度。颜色越明亮,数据越密集。
函数:seaborn.heatmap
常用参数:
| data | 接收二维矩阵数据集,用于绘图的数据集。 |
| vmin,vmax | 接收float,表示颜色映射的值的范围。默认为None |
| center | 接收float,表示以0为中心发散颜色,默认为None。 |
| cmap | 接收色彩映射或颜色列表,表示数值到颜色空间的映射,默认为None。 |
| robust | bool,如果为True,且vmin,vmax不存在,则用鲁棒分位数表示映射范围。默认为False。 |
| annot | bool或矩形数据集,表示是否在每个单元格显示数值。默认为1 |
| fmt | str,表示传递给FacetGrid的其他参数,默认为“auto” |
| linewidths | float,划分每个单元的线宽。默认为0. |
| linecolor | 划分每个单元的线条颜色,默认为“white” |
| square | bool,表示是否使每个单元为方形。 |
flights=sns.load_dataset('flights')
#生成交叉联表
flights=flights.pivot("month","year","passengers")
sns.heatmap(flights)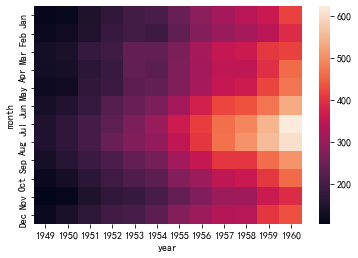
?添加数值标记:
sns.heatmap(flights,annot=True,fmt="d")
二、clustermap?
该函数用于绘制分层聚类热力图。它可以在左侧显示每一个样本的分层聚类情况,在上方显示每一个特征的分层聚类情况。以热力图的形式显示出样本的分布。
函数:seaborn.clustermap
常用参数:
| data | |
| pivot_kws | dict,颜色映射的值的范围,默认为None。 |
| method | str,聚类方法,默认为“average” |
| metric | float,表示数据距离度量方法。默认为“euclidean” |
| z_score | 0或1,表示选择0(行)或1(列)计算z分数。默认为None |
| standard_scale | 0或1,表示选择0(行)或1(列)进行标准化。默认为None |
| figsize | 表示创建图形大小,默认为None |
| {row,col}_cluster | bool,表示是否对样本或特征聚类,默认为True。 |
| {row,col}_linkage | Numpy的ndarray,表示对行或列计算链接矩阵,默认为None |
| {row,col}_color | 接收list,DataFrame,Series,表示行或列标记的颜色列表,默认为None |
| mask | 接收boolean,array,DF,表示是否屏蔽缺失单元格,默认为None。 |
iris=sns.load_dataset('iris')
#把species属性去掉后保存为一个新数据集
species=iris.pop("species")
sns.clustermap(iris)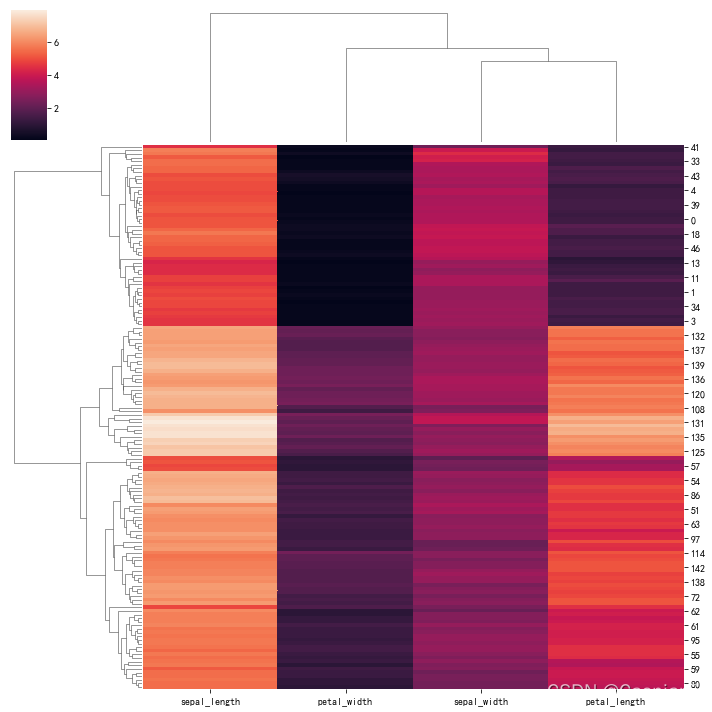
?改变聚类方法,只绘制样本聚类图:
sns.clustermap(iris,method='single',col_cluster=False)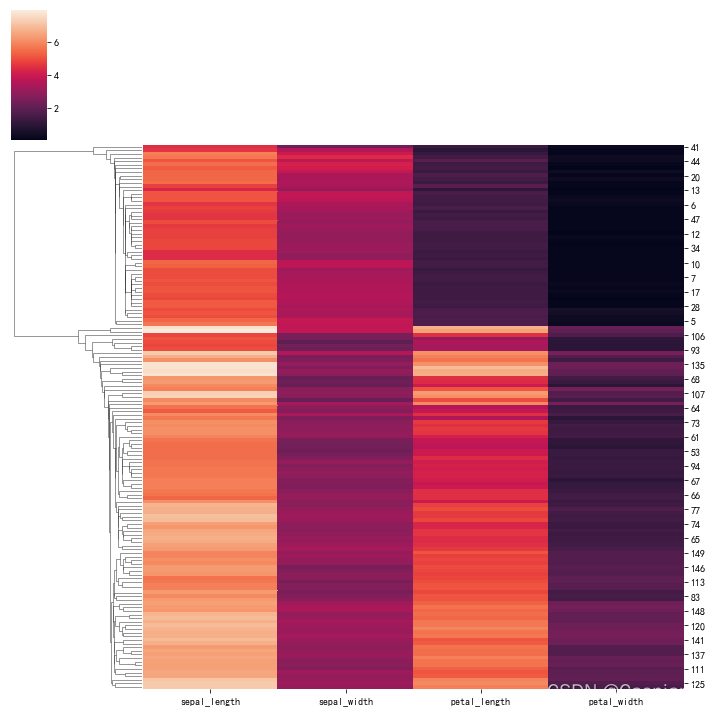
?