简 介: 通过在AI Studio中对于三种创建项目方式进行测试。可以看到它们各自的特征,为了之后很好的在AI Studio进行项目运行提供经验。
关键词: AI,Studio
AI Studio
文章目录
建立测试工程
创建Notebook工程
创建脚本工程
终止后的任务日志
创建图形工程
总 结
?
§01 AI Studio
??今天(2021-12-07)是将AI Studio中的留有的信息(手机信息)修正之后,能够进行认证并将算力卡邀请码进行输入。因此,今天对于在AI Studio上建立简单的工程过程进行测试。

▲ 图1.1 输入AI Studio 算力卡之后的情况
一、建立测试工程
1、创建Notebook工程
??在自己的主页中,项目下可以看到创建和Fork项目,进入之后可以展示自己的已有的项目。电机“创建项目”。

▲ 图1.1.1 建立工程的界面
??下面显示创建项目的三种类型:
- Notebook
- 脚本任务
- 图像化任务

▲ 图1.1.2 创建新的工程的对话框
(1)Notebook方式
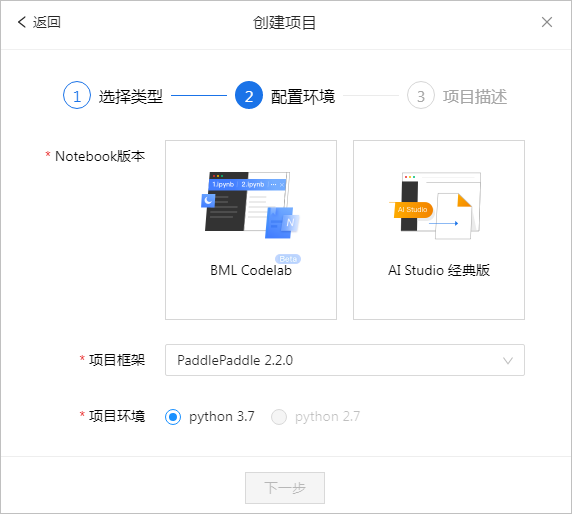
▲ 图1.1.3 配置环境
??选择AI Studio经典版本。后面经过输入相应的配置环境,输入数据集合,便进入了项目观察状态
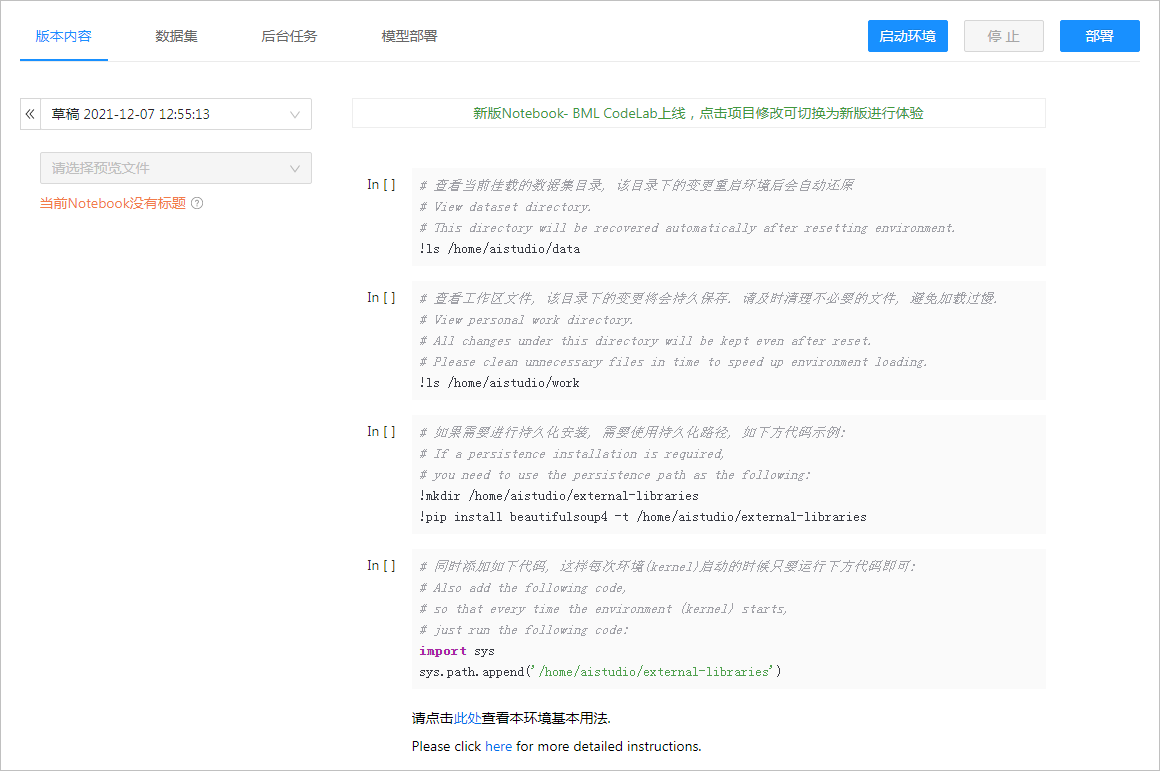
▲ 图1.1.4 项目创建完之后的观察状态
??打开启动环境,第一步需要进行选择运行环境。
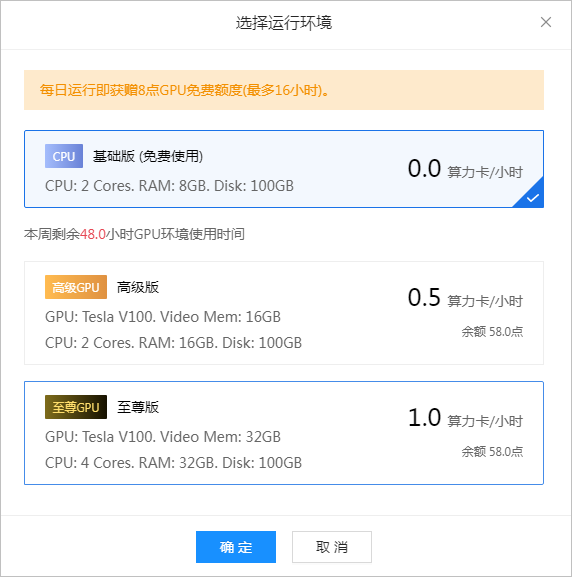
▲ 图1.1.5 选择运行环境
??确定后,便进入了两种工作模式:
- Notebook模式
- 终端-1工作模式
??在终端工作模式下,就如同远程登录服务器的模式一样。可以使用vi编辑python程序,并利用python运行它。

▲ 图1.1.6 在notebook下执行相应的程序
??终端可以在左侧的环境中进行关闭和建立。
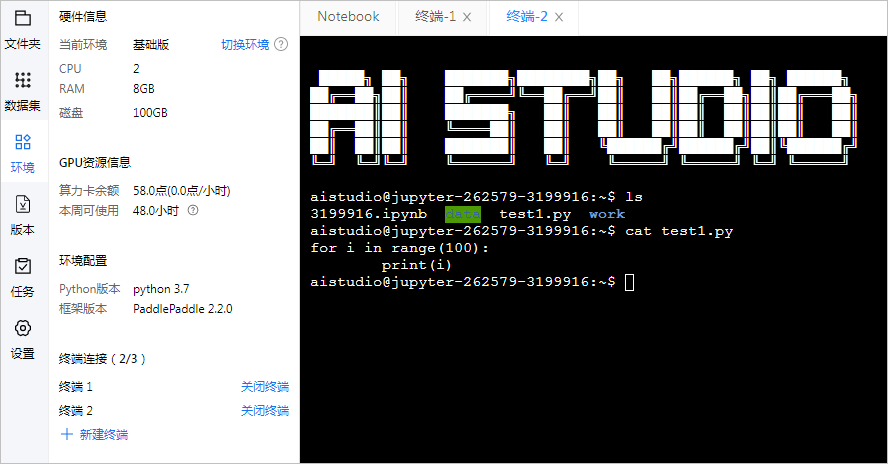
▲ 图1.1.7 在终端进行操作

▲ 图1.1.8 切换环境
2、创建脚本工程
(1)创建过程
??选择“创建脚本工程”,进入配置环境。
▲ 图1.1.9 创建脚本工程,配置环境
(2)工程查看
??如下是工程查看下的脚本程序:
# coding=utf-8
###### 欢迎使用脚本任务,首先让我们熟悉脚本任务的一些使用规则 ######
# 脚本任务支持两种运行方式
# 1.shell 脚本. 在 run.sh 中编写项目运行时所需的命令,并在启动命令框中填写 bash run.sh <参数1> <参数2>使脚本任务正常运行.
# 2.python 指令. 在 run.py 编写运行所需的代码,并在启动命令框中填写 python run.py <参数1> <参数2> 使脚本任务正常运行.
#注:run.sh、run.py 可使用自己的文件替代。
###数据集文件目录
datasets_prefix = '/root/paddlejob/workspace/train_data/datasets/'
# 数据集文件具体路径请在编辑项目状态下通过左侧导航「数据集」中文件路径拷贝按钮获取
train_datasets = '通过路径拷贝获取真实数据集文件路径 '
# 输出文件目录. 任务完成后平台会自动把该目录所有文件压缩为tar.gz包,用户可以通过「下载输出」可以将输出信息下载到本地.
output_dir = "/root/paddlejob/workspace/output"
# 日志记录. 任务会自动记录环境初始化日志、任务执行日志、错误日志、执行脚本中所有标准输出和标准出错流(例如print()),用户可以在「提交」任务后,通过「查看日志」追踪日志信息.
from argparse import ArgumentParser, REMAINDER
import paddle.distributed.launch as launch
from argparse import Namespace
# launch args
parser = ArgumentParser()
parser.add_argument("--cluster_node_ips", type=str, default="127.0.0.1",
help='# Paddle cluster nodes ips, such as 192.168.0.16,192.168.0.17..')
parser.add_argument("--node_ip", type=str, default="127.0.0.1", help='The current node ip.')
parser.add_argument("--use_paddlecloud", action='store_true', default=False,
help='wheter to use paddlecloud platform to run your multi-process job. If false, no need to set this argument.')
parser.add_argument("--started_port", type=int, default=None, help="The trainer's started port on a single node")
parser.add_argument("--print_config", type=bool, default=True, help='Print the config or not')
parser.add_argument("--selected_gpus", type=str, default=None,
help="It's for gpu training and the training process will run on the selected_gpus, each "
" process is bound to a single GPU. And if it's not set, this module will use all the gpu cards for training.")
parser.add_argument("--log_level", type=int, default=20, help='Logging level, default is logging.INFO')
parser.add_argument("--log_dir", type=str, default=None,
help="The path for each process's log.If it's not set, the log will printed to default pipe.")
args = parser.parse_args()
args.training_script="train.py"
# config for single card
args.training_script_args=["--dataset_base_path", datasets_prefix + "data65/", "--output_base_path", output_dir + "model"]
# config for multi card,add --distributed
# args.training_script_args=["--distributed", "--dataset_base_path", datasets_prefix + "data65/", "--output_base_path", output_dir + "model"]
print(args)
launch.launch(args)
(3)任务提交

▲ 图1.1.10 任务提交后的状态
3、终止后的任务日志
PADDLE_TRAINERS_NUM=1
PADDLE_USE_CUDA=1
NCCL_SOCKET_IFNAME=eth0
PADDLE_IS_LOCAL=1
OUTPUT_PATH=/root/paddlejob/workspace/output
LOCAL_LOG_PATH=/root/paddlejob/workspace/log
LOCAL_MOUNT_PATH=/mnt/code_20211207130856,/mnt/datasets_20211207130856
JOB_ID=job-5ea79b227e09736a0f139ddc7dae5f2d
TRAINING_ROLE=TRAINER
[INFO]: user command: python run.py
[INFO]: start trainer
~/paddlejob/workspace/code /mnt
usage: run.py [-h] [--log_dir LOG_DIR] [--backend BACKEND]
[--nproc_per_node NPROC_PER_NODE] [--run_mode RUN_MODE]
[--gpus GPUS] [--selected_gpus GPUS] [--ips IPS]
[--servers SERVERS] [--workers WORKERS]
[--heter_workers HETER_WORKERS] [--worker_num WORKER_NUM]
[--server_num SERVER_NUM] [--heter_worker_num HETER_WORKER_NUM]
[--http_port HTTP_PORT] [--elastic_server ELASTIC_SERVER]
[--job_id JOB_ID] [--np NP] [--scale SCALE] [--host HOST]
[--force FORCE]
training_script ...
run.py: error: the following arguments are required: training_script, training_script_args
/mnt
[INFO]: train job failed! train_ret: 2
4、创建图形工程
▲ 图1.1.11 创建图形工程对话框

▲ 图1.1.12 干干净净的图形工程
??具体使用过程可以参见: AI Studio图形化任务说明 。
◎ 建立工程总结
??从前面看的初步使用过来来看,使用Notebook方式可以很方便通过交互式完成程序的运行和测试。可以看到整个测执行过程运行的结果输出。 而对于脚本任务,则只能通过提交任务,最后等任务完成,中间的时间不可控制。
二、删除项目
??对于建立的项目,可以通过以下步骤删除:
- 选择项目:

▲ 图1.2.1 选择对应的项目
??在查看页中确定是否删除:

▲ 图1.2.2 在查看页中确定是否删除

▲ 图1.2.3 确定删除项目
& nbsp;
※ 总??结 ※
??通过在AI Studio中对于三种创建项目方式进行测试。可以看到它们各自的特征,为了之后很好的在AI Studio进行项目运行提供经验。
■ 相关文献链接:
● 相关图表链接: