Article
����:David Silver*, Aja Huang*, Chris J. Maddison etc.
������Ŀ:ͨ����������������������Χ����Ϸ
����ʱ��:2016
�����ڿ�:nature
https://github.com/jmgilmer/GoCNN
ժҪ
-
�������������ռ����������λ�ú��ƶ����Ѷ�,Χ��һֱ����Ϊ�˹����ܾ�����Ϸ�������ս�Ե���Ϸ��������,���ǽ�����һ���µļ����Χ�巽��,��ʹ�á���ֵ���硱����������λ�ú͡��������硱��ѡ���߷�����Щ���������ͨ������ר����Ϸ�ļලѧϰ��������Ϸ��ǿ��ѧϰ����ӱ��Ͻ���ѵ������û���κ�ǰհ�����������,�����������Ƚ������ؿ��������������ˮƽ����Χ��,ģ����ǧ�������������Ϸ�����ǻ�������һ���µ������㷨,�������ؿ���ģ�����ֵ�Ͳ����������ϡ�ʹ�����������㷨,���ǵij��� AlphaGo ������Χ�����ȡ���� 99.8% ��ʤ��,�� 5 �� 0 ����������ŷ��Χ��ھ��� ���Ǽ���������״�ȫ���������ְҵ����Χ��,��ǰ��Ϊ������Ҫʮ�����ʵ����һ׳�١�
-
����������Ϣ���Ķ���һ������ֵ���� v ? ( s ) v^*(s) v?(s),�����������������������������,ÿ������λ�û�״̬ s s s �IJ��Ľ������Щ��Ϸ����ͨ���ڰ�����Լ b d b^d bd �����ܵ��ƶ����е��������еݹ��������ֵ���������,���� b b b ����Ϸ�Ĺ��(ÿ��λ�õĺϷ��ƶ���), d d d �������(��Ϸ����)���ڴ�����Ϸ��,����������� ( b �� 35 , d �� 80 ) (b��35,d��80) (b��35,d��80),������Χ�� ( b �� 250 , d �� 150 ) (b��250,d��150) (b��250,d��150),��������Dz����е�,������ͨ������һ��ԭ�������Ч�����ռ䡣����,��������ȿ���ͨ��λ������������:�ض�״̬ s s s ����������,����һ������ֵ���� v ( s ) �� v ? ( s ) v(s)��v^*(s) v(s)��v?(s) �滻 s s s �·�������,�ú�������Ԥ��״̬ s s s �Ľ�������ַ����ڹ������塢����ͺڰ�����ȡ���˳��˵ı���,��������Ϸ�ĸ�����,������Ϊ����Χ�������Լ�Ԧ�����,����ͨ���Ӳ��� p ( a �O s ) p(a|s) p(a�Os) �в������������������Ĺ��,���� p ( a �O s ) p(a|s) p(a�Os) ��λ�� s s s �п����ƶ� a a a �ĸ��ʷֲ�������,���ؿ���ͨ���Ӳ��� p p p �ж�������ҵij��������н��в���,����ȫ����֧������������������ȡ��Դ����Ƴ�����ƽ�������ṩ��Ч��λ������,������˫½���ƴ����Ϸ��ʵ�ֳ��˵ı���,��Χ����ʵ������ҵ��ˮƽ��
-
Monte Carlo ������ (MCTS) ʹ�� Monte Carlo rollouts ��������������ÿ��״̬��ֵ�� ����ִ�и����ģ��,��������ø���,���ֵ��ø�ȷ�� ͨ��ѡ����и���ֵ������,�����������ڼ�ѡ������IJ���Ҳ����ʱ������ƶ��Ľ��� ������,�ò��������������淨,������������������ֵ������ ��ǰ��ǿ���Χ�������� MCTS,��ͨ������ѵ����Ԥ������ר�Ҷ����IJ��Եõ���ǿ�� ��Щ�������ڽ�������Χ��С��һϵ�и߸��ʶ���,�����Ƴ��ڼ�Զ������в����� ���ַ����Ѿ�ʵ����ǿ���ҵ��ӡ� Ȼ��,��ǰ�Ĺ��������ڻ�������������������ϵ�dz����Ի��ֵ������
-
����ʹ���ɻ���ѧϰ�ļ�������ɵ�pipeline��ѵ��������(ͼ 1)�� ��������ֱ�Ӵ�ר�����ද��ѵ���ලѧϰ (SL) �������� p �� p_�� p��?�� ��ͨ����ʱ�����������ݶ��ṩ���١���Ч��ѧϰ���¡� ��֮ǰ�Ĺ�������,���ǻ�ѵ����һ�����ٲ��� p �� p_�� p��?,�����ڲ����ڼ���ٲ��������� ������,����ѵ��һ��ǿ��ѧϰ (RL) �������� p �� p_�� p��?,��ͨ���Ż����Ҳ��ĵ����ս�����Ľ� SL �������硣 ��ᳯ��Ӯ�ñ�������ȷĿ���������,���������Ԥ��ȷ�ԡ� ���,����ѵ����һ����ֵ���� v �� v_�� v��?,������Ԥ�� RL �����������������е���Ϸ�Ļ�ʤ�ߡ� ���ǵij��� AlphaGo �����Ժͼ�ֵ������ MCTS ��Ч�ؽ����һ��
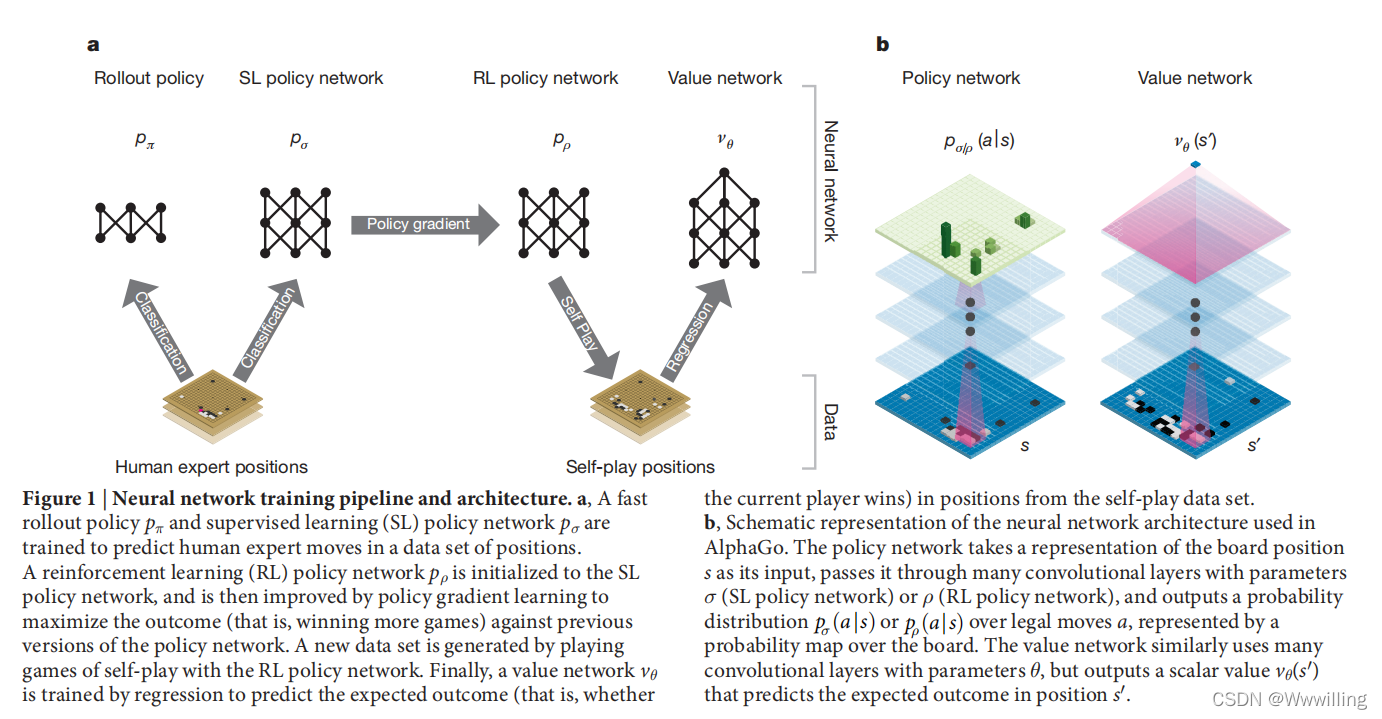
-
ͼ1 |������ѵ���ܵ��ͼܹ���
a,ѵ�������Ƴ����� p �� p_�� p��? �ͼලѧϰ (SL) �������� p �� p_�� p��? ��Ԥ������ר����λ�����ݼ��е��ƶ���ǿ��ѧϰ (RL) �������� p �� p_�� p��? ����ʼ��Ϊ SL ��������,Ȼ��ͨ�������ݶ�ѧϰ���иĽ�,����Կ���ǰ�汾�IJ�������Ľ��(��Ӯ�ø�����Ϸ)��һ���µ����ݼ���ͨ���� RL ��������������Ҳ��Ķ����ɵġ����,ͨ���ع�ѵ����ֵ���� v �� v_�� v��?,��Ԥ�����Ҷ������ݼ���λ�õ�Ԥ�ڽ��(����ǰ����Ƿ��ʤ)��
b,AlphaGo ��ʹ�õ�������ܹ���ʾ��ͼ���������罫����λ�� s s s �ı�ʾ��Ϊ������,����ͨ������Ϊ �� �� ��(SL ��������)�� �� �� ��(RL ��������)�����������,��������ʷֲ� p �� ( a �O s ) p_��(a|s) p��?(a�Os) �� p �� ( a �O s ) p_�� (a|s) p��?(a�Os) ͨ���Ϸ��ƶ� a a a,�������ϵĸ���ͼ��ʾ����ֵ�������Ƶ�ʹ��������в��� �� �� �� �ľ�����,�����һ������ֵ v �� ( s �� ) v_��(s') v��?(s��) ��Ԥ��λ�� s �� s' s�� ��Ԥ�ڽ����
��������ļලѧϰ
- ����ѵ���ܵ��ĵ�һ��,���ǽ�����ʹ�üලѧϰԤ��Χ����Ϸ��ר�Ҷ�������ǰ�����Ļ����ϡ� SL ��������
p
��
(
a
�O
s
)
p_��(a|s)
p��?(a�Os) ��Ȩ��Ϊ
��
��
�� �ľ������������������֮�佻�档 ���һ�� softmax ��������кϷ��ƶ�
a
a
a �ĸ��ʷֲ��� �������������
s
s
s �Ƕ��»�״̬�ļ�ʾ(�μ���չ���ݱ� 2)�� �������������������״̬-������
(
s
,
a
)
(s, a)
(s,a) �Ͻ���ѵ��,ʹ������ݶ������������״̬
s
s
s ��ѡ��������ƶ�
a
a
a �Ŀ����ԡ�
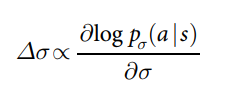
- ���Ǵ� KGS Go Server �� 3000 ���λ��ѵ����һ�� 13 ��IJ�������,���dz�֮Ϊ SL �������硣 �����¼������,����Ԥ��ר���ڱ����IJ��Լ����ƶ�,ʹ����������������ȷ��Ϊ 57.0%,��ʹ��ԭʼ����λ�ú��ƶ���ʷ��Ϊ�����ȷ��Ϊ 55.7% ���������о�С��� 44.4% ���ύ֮��(��չ���ݱ� 3 �е��������)�� ȷ�Ե�С��������������ǿ�ȵĴ������(ͼ 2a); �����������Ի�ø��õ�ȷ��,�������������������ٶȽ����� ���ǻ�ʹ��Ȩ��Ϊ �� ��Сģʽ���������� softmax(�μ���չ���ݱ� 4)ѵ����һ�����쵫��̫ȷ�� rollout ����
p
��
(
a
�O
s
)
p_��(a|s)
p��?(a�Os); ��ʵ���� 24.2% ��ȷ��,��ʹ�� 2��s ��ѡ��һ������,�����Dz�������� 3ms��
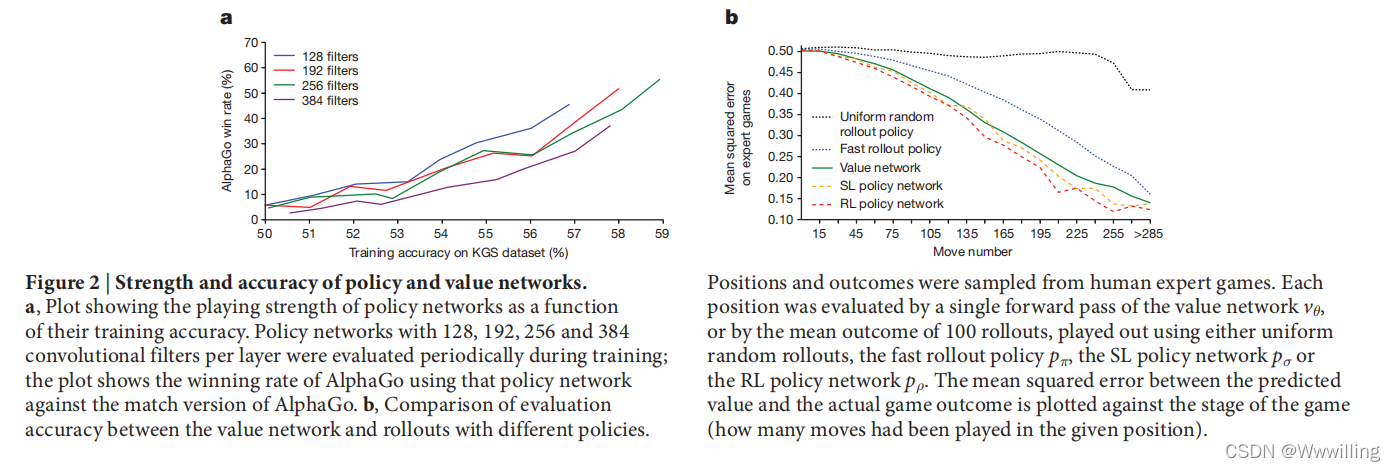
- ͼ2 | ���Ժͼ�ֵ�����ǿ�Ⱥ�ȷ�ԡ�
a,��ʾ��������IJ���ǿ����Ϊ��ѵ��ȷ�Եĺ�����ͼ�� ��ѵ���ڼ䶨������ÿ����� 128��192��256 �� 384 �������˲����IJ�������; ��ͼ��ʾ��ʹ�øò�������� AlphaGo ��ƥ��汾�� AlphaGo �Ļ�ʤ�ʡ�
b,��ֵ����Ͳ�ͬ���Ե�rollouts֮����������ȱȽϡ� λ�úͽ���Ǵ�����ר����Ϸ�в����ġ� ÿ��λ�ö�ͨ����ֵ���� v �� v_�� v��? �ĵ���ǰ�ݽ�������,��ͨ�� 100 �� rollout ��ƽ�������������,ʹ�þ������ rollout������ rollout ���� p �� p_�� p��?��SL �������� p �� p_�� p��? �� RL �������� p �� p_�� p��? ���������� Ԥ��ֵ��ʵ����Ϸ���֮��ľ�����������Ϸ��(�ڸ���λ�ý����˶��ٲ�)���ơ�
���������ǿ��ѧϰ
- ѵ���ܵ��ĵڶ���ּ��ͨ�������ݶ�ǿ��ѧϰ (RL) �Ľ��������硣 RL ��������
p
��
p_��
p��? �ڽṹ���� SL ����������ͬ,��Ȩ��
��
��
�� ����ʼ��Ϊ��ͬ��ֵ,
��
=
��
��=��
��=���� �����ڵ�ǰ��������
p
��
p_��
p��? ��֮ǰ���ѡ��IJ����������֮������Ϸ�� �����ַ�ʽ��һ������������ͨ����ֹ������ϵ�ǰ�������ȶ�ѵ���� ����ʹ�ý�������
r
(
s
)
r(s)
r(s) �������з��ն�ʱ�䲽
t
<
T
t<T
t<T Ϊ�㡣 ���
z
t
=
��
r
(
s
T
)
z_t=��r(s_T)
zt?=��r(sT?) ����ʱ�䲽��
t
t
t �ӵ�ǰ��ҵĽǶ�����,��Ϸ����ʱ�����ս���:Ӯ+1,��-1�� Ȼ����ÿ��ʱ�䲽��
t
t
t ͨ�������Ԥ�ڽ���ķ���������ݶ�����������Ȩ�ء�
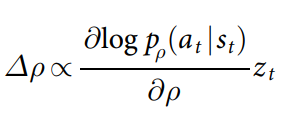
- ���������� RL ������������Ϸ�е�����,��ÿ��������������ʷֲ��в��� a t �� p �� ( ? �O s t ) a_t \sim p_��(?|s_t) at?��p��?(?�Ost?)�� ���� SL ��������������潻��ʱ,RL ��������Ӯ���� 80% ���ϵĶ�ս SL �������硣 ���ǻ������ǿ��Ŀ�ԴΧ����� Pachi �����˲���,Pachi ��һ�����ӵ����ؿ�����������,�� KGS �������� 2 ҵ���λ,ÿ��ִ�� 100,000 ��ģ�⡣ ��ȫ��ʹ������,RL ������������ Pachi �ı�����Ӯ���� 85% ��ʤ���� ���֮��,��ǰ�����¼��������ڼල��
- ���֮��,֮ǰ�����¼��������ھ�������ļලѧϰ,�ڶԿ� Pachi �ı�����Ӯ���� 11% ��ʤ��,�ڶԿ������ij��� Fuego �ı�����Ӯ���� 12% ��ʤ����
��ֵ�����ǿ��ѧϰ
- ѵ���ܵ������β�����λ������,����һ����ֵ����
v
p
(
s
)
v^p(s)
vp(s),�ú���ͨ�����������ʹ�ò���
p
p
p ��Ԥ������������Ϸ��λ��
s
s
s �Ľ����
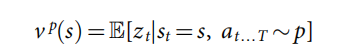
- ���������,������֪��������Ϸ
v
?
(
s
)
v^*(s)
v?(s) �µ�����ֵ����; ��ʵ����,����ʹ�� RL ��������
p
��
p_��
p��? ������������ǿ���Եļ�ֵ����
v
p
��
v^{p_��}
vp��?�� ����ʹ��Ȩ��Ϊ
��
��
��,
v
��
(
s
)
��
v
p
��
(
s
)
��
v
?
(
s
)
{v_\theta }\left( s \right) \approx {v^{{p_\rho }}}\left( s \right) \approx {v^*}\left( s \right)
v��?(s)��vp��?(s)��v?(s)�ļ�ֵ����
v
��
(
s
)
v_��(s)
v��?(s) �����Ƽ�ֵ������ �����������������������Ƶļܹ�,��������ǵ���Ԥ������Ǹ��ʷֲ��� ����ͨ��״̬-�����
(
s
,
z
)
(s, z)
(s,z) �ϵĻع���ѵ����ֵ�����Ȩ��,ʹ������ݶ��½�����С��Ԥ��ֵ
v
��
(
s
)
v_��(s)
v��?(s) ����Ӧ���
z
z
z ֮��ľ������ (MSE) ��
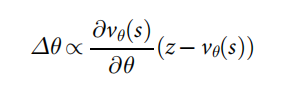
- �Ӱ���������Ϸ��������Ԥ����Ϸ��������ɷ����ᵼ�¹�����ϡ�������������λ����ǿ��ص�,ֻ��һ��ʯͷ��ͬ,��������Ϸ�����ع�Ŀ�ꡣ�������ַ�ʽ�� KGS ���ݼ���ѵ��ʱ,��ֵ�����ס�˱�����������Ƿ�������λ��,�ڲ��Լ���ʵ���� 0.37 ����С MSE,����ѵ��������Ϊ 0.19��Ϊ�˻����������,����������һ���µ�����Ϸ���ݼ�,���� 3000 �����ͬ��λ��,ÿ��λ�ö���һ����������Ϸ�в�����ÿ����Ϸ���� RL ����������������֮�����,ֱ����Ϸ��ֹ���Ը����ݼ���ѵ������ѵ�����Ͳ��Լ��� MSE �ֱ�Ϊ 0.226 �� 0.234,�����������С��ͼ 2b ��ʾ�˼�ֵ�����λ����������,��ʹ�ÿ��� rollout ���� p�� �� Monte Carlo rollout ���;��ֵ����ʼ�ո�ȷ���� v �� ( s ) v_��(s) v��?(s) �ĵ�������Ҳ�ӽ�ʹ�� RL �������� p �� p_�� p��? �� Monte Carlo rollouts ��ȷ��,��ʹ�õļ����������� 15,000 ����
ʹ�ò��Ժͼ�ֵ�����������
-
AlphaGo �� MCTS �㷨(ͼ 3)�н���˲��Ժͼ�ֵ����,���㷨ͨ������������ѡ������
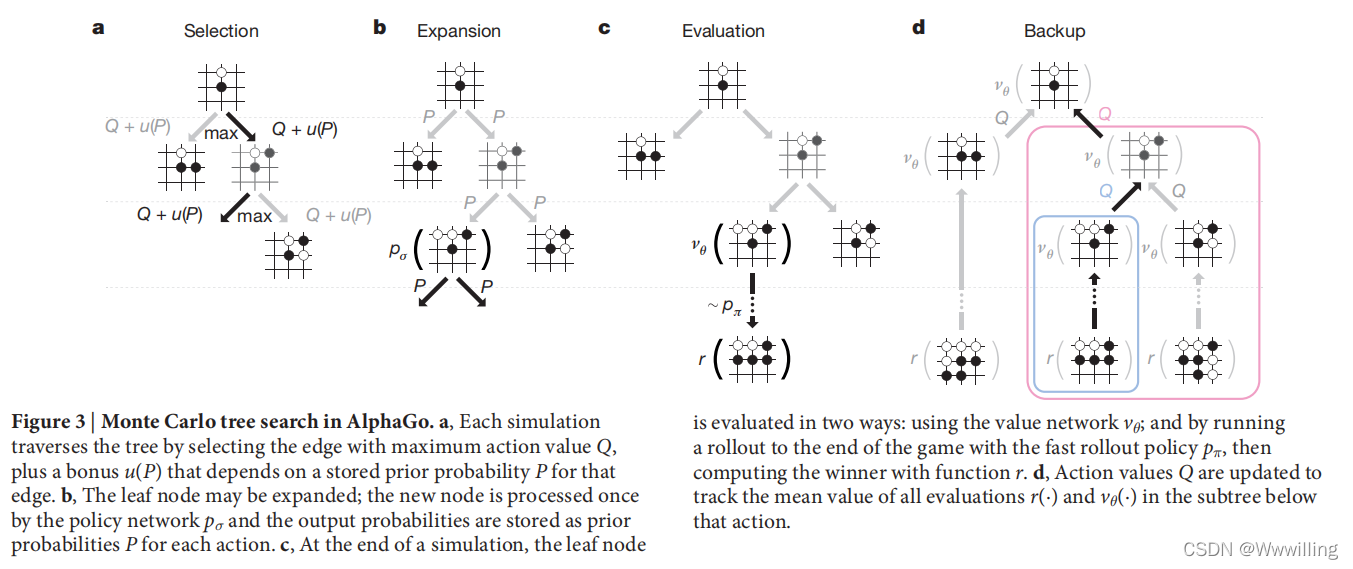
-
ͼ 3 | AlphaGo �е����ؿ�����������
a,ÿ��ģ�ⶼͨ��ѡ����������ֵ Q Q Q �ı��Լ�ȡ���ڸñߴ洢��������� P P P �Ľ��� u ( P ) u(P) u(P) ����������
b��Ҷ�ӽڵ������չ; �½ڵ��ɲ������� p �� p_�� p��? ����һ��,������ʴ洢Ϊÿ��������������� P P P��
c����ģ�����ʱ,Ҷ�ӽڵ�ͨ�����ַ�ʽ��������:ʹ�ü�ֵ���� v �� v_�� v��?; ��ͨ��ʹ�ÿ����Ƴ����� p �� p_�� p��? �����Ƴ�����Ϸ����,Ȼ��ʹ�ú��� r r r �����ʤ�ߡ�
d,���¶���ֵ Q Q Q �Ը��ٸö����·��������������� r ( ? ) r(��) r(?) �� v �� ( ? ) v_��(��) v��?(?) ��ƽ��ֵ�� -
��������ÿ���� ( s , a ) (s, a) (s,a) ���洢��һ������ֵ Q ( s , a ) Q(s, a) Q(s,a)�����ʴ��� N ( s , a ) N(s, a) N(s,a) ��������� P ( s , a ) P(s, a) P(s,a)�� ��ͨ��ģ�����(����û�б��ݵ�������Ϸ���½���),�Ӹ�״̬��ʼ�� ��ÿ��ģ���ÿ��ʱ�䲽�� t t t,��״̬ s t s_t st? ��ѡ��һ������ a t a_t at?��
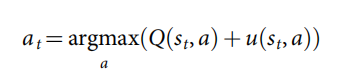
-
�Ӷ�����ȵ�����ж���ֵ�ͽ���
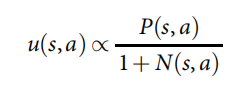
-
����������ʳ�����,���������ظ����ʶ�˥���Թ���̽���� �������ڲ��� L L L ����Ҷ�ڵ� s L s_L sL? ʱ,������չҶ�ڵ㡣 SL �������� p �� p_�� p��? ֻ����Ҷλ�� s L s_L sL? һ�Ρ����������Ϊÿ���Ϸ���Ϊ a a a ��������� P P P �洢, P ( s �O a ) = P �� ( a �O s ) P(s|a)= P_��(a|s) P(s�Oa)=P��?(a�Os) �� Ҷ�ڵ������ֽ�Ȼ��ͬ�ķ�ʽ��������:����,ͨ����ֵ���� v �� ( s L ) v_��(s_L) v��?(sL?); ���,����ʹ�ÿ����Ƴ����� p �� p_�� p��? ������Ƴ��Ľ�� z L z_L zL?,ֱ���ն˲��� T T T Ϊֹ; ʹ�û�ϲ��� �� �� �� ����Щ������ϳ�Ҷ������ V ( s L ) V(s_L) V(sL?)

-
��ģ�����ʱ,�������б����ߵĶ���ֵ�ͷ��ʼ����� ÿ�����ۻ�ͨ���ñߵ�����ģ��ķ��ʼ�����ƽ������
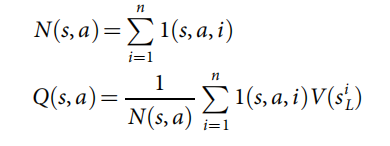
-
���� s L i {s_L}^i sL?i �ǵ� i i i ��ģ���Ҷ�ڵ�, 1 ( s , a , i ) 1(s, a, i) 1(s,a,i) ��ʾ�ڵ� i i i ��ģ���ڼ��Ƿ�����˱� ( s , a ) (s, a) (s,a)�� ������ɺ�,�㷨�Ӹ�λ��ѡ������������ƶ���
-
ֵ��ע�����,SL �������� p �� p_�� p��? �� AlphaGo �еı��ֱȸ�ǿ�� RL �������� p �� p_�� p��? ����,��������Ϊ����ѡ����һϵ����ϣ�����߷�,�� RL �Ż��˵�һ������߷��� Ȼ��,�Ӹ�ǿ�� RL �������絼���ļ�ֵ���� v �� ( s ) �� v p �� ( s ) {v_\theta }\left( s \right) \approx {v^{{p_\rho }}}\left( s \right) v��?(s)��vp��?(s) �� AlphaGo �бȴ� SL �������絼���ļ�ֵ���� v �� ( s ) �� v p �� ( s ) {v_\theta }\left( s \right) \approx {v^{{p_\sigma }}}\left( s \right) v��?(s)��vp��?(s) ���ֵø��á�
-
�������Ժͼ�ֵ������Ҫ�ȴ�ͳ��������ʽ�㷨�༸���������ļ��㡣 Ϊ����Ч�ؽ� MCTS ���������������,AlphaGo ʹ���첽���߳������� CPU ��ִ��ģ��,���� GPU �ϲ��м�����Ժͼ�ֵ���硣 AlphaGo �����հ汾ʹ���� 40 �������̡߳�48 �� CPU �� 8 �� GPU�� ���ǻ�ʵ����һ���ֲ�ʽ�汾�� AlphaGo,�������˶�̨������40 �������̡߳�1,202 �� CPU �� 176 �� GPU�� ���������ṩ���첽�ͷֲ�ʽ MCTS ��������ϸ��Ϣ��
����AlphaGo������
- Ϊ������ AlphaGo,������ AlphaGo �ı������������Χ�����֮��ٰ���һ���ڲ�����,���а�����ǿ����ҵ���� Crazy Stone �� Zen,�Լ���ǿ�Ŀ�Դ���� Pachi�� Fuego�� ������Щ�����ڸ����ܵ� MCTS �㷨�� ����,���ǻ�������Դ���� GnuGo,����һ��ʹ�� MCTS ֮ǰ�����Ƚ����������� Go ���� ���г���ÿ���ƶ��������� 5 ��ļ���ʱ�䡣
- �������Ľ��(��ͼ 4a)����,���� AlphaGo ����ǰ���κ�Χ�����Ҫǿ�ܶ��λ,��������Χ������ 495 ��������Ӯ�� 494 ��(99.8%)�� Ϊ�˸�AlphaGo�ṩ�������ս,���ǻ��������Ŀ�����(������������)�ĶԾ�; AlphaGo �ֱ��� 77%��86% �� 99% ��ʤ��սʤ�� Crazy Stone��Zen �� Pachi�� AlphaGo �ķֲ�ʽ�汾���Ը�ǿ��,�Ե��� AlphaGo �ı���ʤ��Ϊ 77%,����������ı���ʤ��Ϊ 100%��
- ���ǻ������˽�ʹ�ü�ֵ����
(
��
=
0
)
(�� = 0)
(��=0) ���ʹ�� rollouts
(
��
=
1
)
(�� = 1)
(��=1) ����λ�õ� AlphaGo ����(��ͼ 4b)�� ��ʹû���Ƴ�,AlphaGo Ҳ��������������Χ����������,�������ֵ����ΪΧ���е����ؿ��������ṩ�˿��е���������� Ȼ��,������� (��=0.5) �������,������������ı����л�ʤ�ʡ�95%�� ���������λ�����������ǻ�����:��ֵ���������ǿ������ʵ�ʵ��� p�� ������Ϸ�Ľ��,�� rollouts ���Ծ�ȷ�����ֺ������������Ͽ�� rollout ���� p�� �����Ϸ�Ľ�� . ͼ 5 ��ʾ�� AlphaGo ����ʵ��Ϸλ�õ�������
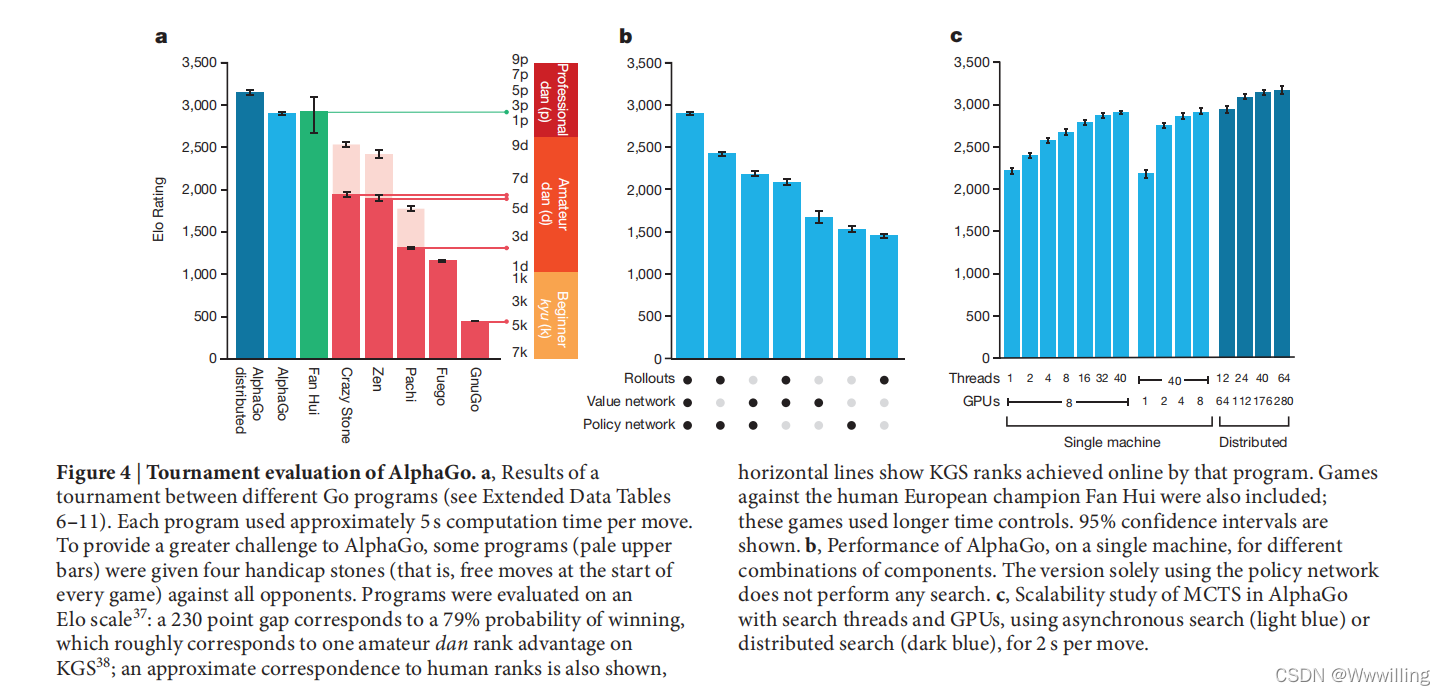
- ͼ 4 | AlphaGo �ı���������
a,��ͬΧ�����֮��ı������(�μ���չ���ݱ� 6-11)��ÿ������ÿ���ƶ�ʹ�ô�Լ 5 ��ļ���ʱ�䡣Ϊ���� AlphaGo �ṩ�������ս,һЩ����(������)�������Ŀ��ò���(��ÿ��������ʼʱ�����ɲ�)�Կ����ж��֡�������������� Elo ����37:230 �ֵIJ���Ӧ�� 79% �Ļ�ʤ����,���¶�Ӧ�� KGS38 �ϵ�һ��ҵ���λ����;����ʾ��������ȼ��Ľ��ƶ�Ӧ��ϵ,ˮƽ����ʾ�˸ó�������õ� KGS �ȼ���������ŷ�ھ����Եı���Ҳ��������;��Щ��Ϸʹ���˸�����ʱ����ơ���ʾ�� 95% ���������䡣
b, AlphaGo �ڵ�̨������,��ͬ�����ϵ����ܡ���ʹ�ò�������İ汾��ִ���κ�������
c,ʹ���첽����(dz��ɫ)��ֲ�ʽ����(����ɫ),�� AlphaGo ��ʹ�������̺߳� GPU ���� MCTS �Ŀ���չ���о�,ÿ�� 2 �롣
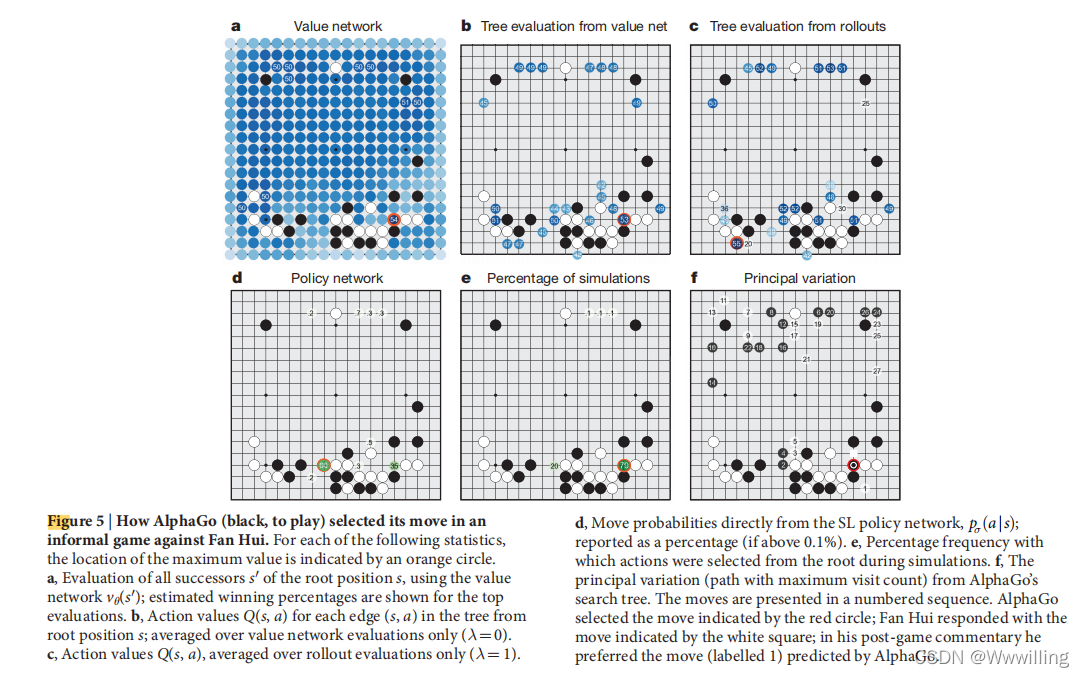
- ͼ 5 | AlphaGo(����,����)���뷶�Եķ���ʽ��Ϸ�����ѡ���岽����������ÿ��ͳ����,���ֵ��λ���ɳ�ɫԲȦ��ʾ��
a, ʹ�ü�ֵ���� v �� ( s �� ) v_��(s') v��?(s��) ������λ�� s s s �����к�� s �� s' s��;��ʾ������۵Ĺ��ƻ�ʤ�ٷֱȡ�
b, ���дӸ�λ�� s s s ��ʼ��ÿ���� ( s , a ) (s, a) (s,a) �Ķ���ֵ Q ( s , a ) Q(s, a) Q(s,a);���Լ�ֵ������������ƽ�� ( �� = 0 ) (��=0) (��=0)��
c,����ֵ Q ( s , a ) Q(s, a) Q(s,a),���� rollout ������ȡƽ��ֵ ( �� = 1 ) (��=1) (��=1)��
d,ֱ�Ӵ� SL ���������ƶ�����, p �� ( a �O s ) p_��(a|s) p��?(a�Os);����Ϊ�ٷֱ�(������� 0.1%)��
e,��ģ���ڼ�Ӹ���ѡ�����İٷֱ�Ƶ�ʡ�
f,���� AlphaGo ����������Ҫ����(���������ʴ�����·��)����Щ���������˳����֡� AlphaGo ѡ���˺�ɫԲȦ��ʾ���߷�;������ɫ������ʾ�Ķ�����Ӧ;����������������,����ϲ�� AlphaGo Ԥ����߷�(���Ϊ 1)�� - ���,���ǽ��ֲ�ʽ�汾�� AlphaGo ��רҵ 2 �����֡�2013��2014 �� 2015 ��ŷ��Χ��������ھ����۽����˶Աȡ� 2015 �� 10 �� 5 ���� 9 ��,AlphaGo �ͷ��۽�����һ����ʽ����ֱ����� AlphaGo �� 5 �� 0 Ӯ�ñ���(ͼ 6 ����չ���ݱ� 1)�� ���Ǽ����Χ������һ����������Χ����������ϰ��ػ�������ְҵ���֡�����ǰ������Ϊ��һ׳��������Ҫʮ��ʱ�����ʵ�֡�

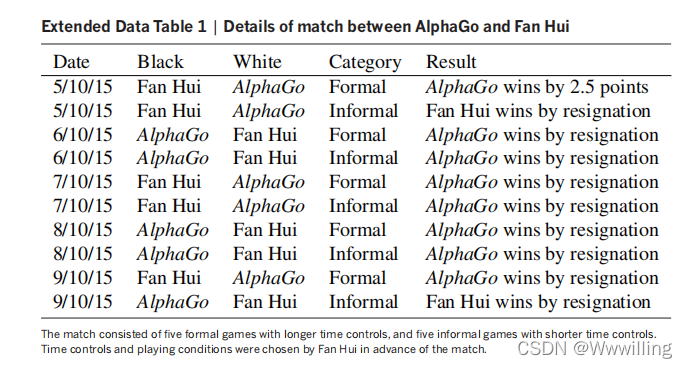
- ͼ 6 | AlphaGo ��ŷ�ھ����۵ı�����
�ƶ��������Dz��ŵ�˳�����Ӧ�ı��˳����ʾ�� ��ͬһ������ϵ��ظ��ƶ��������·��ɶ���ʾ�� ÿ���еĵ�һ���ƶ����ָʾ�ظ��ƶ���ʱ��,���ɵڶ����ƶ���ű�ʶ�Ľ���㴦(�μ�������Ϣ)��
����
- ���������,���ǿ�����һ��������������������������ϵ�Χ�����,������ǿ��������ҵ�ˮƽ�Ϸ�������,�Ӷ�ʵ�����˹����ܵġ��ش���ս��֮һ . �����״ο�������Ч��Χ���߷�ѡ���λ����������,�������������,��Щ����ͨ���ලѧϰ��ǿ��ѧϰ����ӱ��Ͻ���ѵ���� ����������һ���µ������㷨,���㷨�ɹ��ؽ������������� Monte Carlo rollouts ���ϡ� ���ǵij��� AlphaGo ��һ�������ܵ������������д��ģ�ؽ���Щ���������һ��
- AlphaGo �뷮��ĶԾ�,����������˹��������������ǧ��; ͨ�������ܵ�ѡ����Щλ��������,ʹ�ò�������,��ʹ�ü�ֵ�������ȷ���������ǡ���һ�ֿ��ܸ��ӽ�������Ϸ��ʽ�ķ����� ����,��Ȼ�����������ֹ���������������,�� AlphaGo ����������ֱ�Ӵ���Ϸ�淨��ͨ��ͨ�üල��ǿ��ѧϰ����ֱ��ѵ���ġ�
- Χ��������涼���˹��������ٵ����ѵĵ䷶:������ս�Եľ����������Դ����������ռ��Լ���˸��ӵ����Ž������,������ʹ�ò��Ի��ֵ����ֱ�ӱƽ��ƺ��Dz����еġ� ֮ǰ�����Χ����ش�ͻ��,MCTS ������,���������������������Ӧ����; ����,һ����Ϸ������滮�����ֹ۲�滮�����Ⱥ�Լ�����㡣 ͨ��������������Ժͼ�ֵ��������,AlphaGo ������Χ���ϴﵽ��רҵˮƽ,Ϊ���������Ƽ��ֵ��˹������������ڿ���ʵ������ˮƽ�ı����ṩ��ϣ����
����
- ����������������ȫ��Ϣ����,��������塢���塢�����ޡ�����˫½���Χ��,���Զ���Ϊ���������ɷ��ġ�����Щ��Ϸ��,��һ��״̬�ռ�
S
S
S(����״̬������ǰ���Ҫ���ָʾ);һ�������ռ�
A
(
s
)
A(s)
A(s) �������κθ���״̬
s
��
S
s \in S
s��S �еĺϷ�����;״̬ת������
f
(
s
,
a
,
��
)
f(s, a, ��)
f(s,a,��)��������״̬
s
s
s ��ѡ����
a
a
a ���������
��
��
��(��������)��ĺ��״̬;���һ����������
r
i
(
s
)
r^i(s)
ri(s) ���������
i
i
i ��״̬
s
s
s ���յ��Ľ��������ǽ�ע�������������������Ϸ,
r
1
(
s
)
=
?
r
2
(
s
)
=
r
(
s
)
r^1(s)=?r^2(s)=r(s)
r1(s)=?r2(s)=r(s),����ȷ����״̬ת��,
f
(
s
,
a
,
��
)
=
f
(
s
,
a
)
f(s, a, ��)=f(s, a)
f(s,a,��)=f(s,a),�������ն�ʱ�䲽
T
T
T ֮��,�㽱���� ��Ϸ�Ľ��
z
t
=
��
r
(
s
T
)
z_t=��r(s_T)
zt?=��r(sT?) ����ʱ�䲽
t
t
t ʱ�ӵ�ǰ��ҵĽǶ�������Ϸ����ʱ���ն˽���������
p
(
a
�O
s
)
p(a|s)
p(a�Os) �Ƿ�����Ϊ
a
��
A
(
s
)
a \in A(s)
a��A(s) �ĸ��ʷֲ���������ݲ���
p
p
p ѡ�����������ߵ����ж���,���ֵ������Ԥ�ڽ��,��
v
p
(
s
)
=
E
[
z
t
�O
s
t
=
s
,
a
t
.
.
.
T
��
p
]
v^p(s)=E[z_t|s_t=s,a_t...T \sim p]
vp(s)=E[zt?�Ost?=s,at?...T��p] �������Ϸ��һ�����ص����ż�ֵ����
v
?
(
s
)
v^*(s)
v?(s),���������������������Ϸ��״̬
s
s
s �Ľ��,
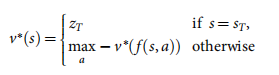
- ֮ǰ�Ĺ����� ����ֵ��������ͨ�� minimax(���Ч�� negamax)�����ݹ���㡣 �������Ϸ�����꾡����С imax ��������˵̫����; �෴,ͨ��ʹ�ý���ֵ���� v ( s ) �� v ? ( s ) v(s)��v^*(s) v(s)��v?(s) �����ն˽������ض���Ϸ�� ʹ�� alpha-beta pruning ��������ȼ�С���������ڹ������塢����ͺڰ�����ȡ���˳��˵ı���,����Χ����Ч�����ѡ�
- ǿ��ѧϰ����ֱ�Ӵ����Ҳ�����ѧϰ��������ֵ������ �������ǰ�Ĺ��������������� ? ( s ) ?(s) ?(s) ��Ȩ�� �� �� �� ��������� v �� ( s ) = ? ( s ) ? �� v_��(s)=?(s)�� �� v��?(s)=?(s)?���� �ڹ������塢�����Χ����ʹ��ʱ����ѧϰѵ��Ȩ��; ���ںڰ����ƴ����Ϸ��ʹ�����Իع顣 ʱ��ѧϰҲ������ѵ�����������ƽ�����ֵ����,������˫½����ʵ�ֳ��˵ı���; ��ʹ�þ���������С��Χ����ʵ���� kyu �����ܡ�
- ��С������������һ�ַ��������ؿ��������� (MCTS),��ͨ��˫�ؽ��ƹ����ڲ��ڵ�����ֵ, V n ( s ) �� v p n ( s ) �� v ? ( s ) {V^n}\left( s \right) \approx {v^{{p^n}}}\left( s \right) \approx {v^*}\left( s \right) Vn(s)��vpn(s)��v?(s) ����һ������ֵ V n ( s ) �� v p n ( s ) {V^n}\left( s \right) \approx {v^{{p^n}}}\left( s \right) Vn(s)��vpn(s) ʹ�� n n n �����ؿ���ģ��������ģ����� P n P_n Pn? �ļ�ֵ�������ڶ�������ֵ v p n ( s ) �� v ? ( s ) {v^{{p^n}}}\left( s \right) \approx {v^*}\left( s \right) vpn(s)��v?(s)ʹ��ģ����� P n P_n Pn? ���漫С�������Ŷ�����ģ����Ը����������ƺ��� ( Q n ( s , a ) + u ( s , a ) ) \left( {{Q^n}\left( {s,a} \right) + u\left( {s,a} \right)} \right) (Qn(s,a)+u(s,a))ѡ����,���� UCT,�ú���ѡ����и��߶���ֵ���ӽڵ�, Q n ( s , a ) = ? V n ( f ( s , a ) ) {Q^n}\left( {s,a} \right) = - {V^n}\left( {f\left( {s,a} \right)} \right) Qn(s,a)=?Vn(f(s,a)),���Ͻ��� u ( s , a ) u(s, a) u(s,a) ����̽��; ������״̬ s s s û���������������,���ӿ����Ƴ����� p �� ( a �O s ) p_��(a|s) p��?(a�Os)�в��������� ���Ÿ����ģ�ⱻִ�в�����������ø���,ģ����Ա��Խ��Խȷ��ͳ�����ݡ� �ڼ��������,�������ƶ���þ�ȷ���� MCTS(����,ʹ�� UCT)����������ֵ���� lim ? n �� �� V n ( s ) = lim ? n �� �� v p n ( s ) = v ? ( s ) {\lim _{n \to \infty }}{V^n}\left( s \right) = {\lim _{n \to \infty }}{v^{{p^n}}}\left( s \right) = {v^*}\left( s \right) limn����?Vn(s)=limn����?vpn(s)=v?(s)�� ��ǰ��ǿ���Χ�������� MCTS��
- MCTS ��ǰ�������ڽ��������IJ�����С���߸����ƶ��IJ�������; ������ƫ��߸����ƶ��� MCTS �������һ��ֵ����,����������չ�Ľڵ��г�ʼ������ֵ,�����ؿ��������뼫С�����������ϡ� ���֮��,AlphaGo �Լ�ֵ������ʹ�û��ڽضϵ����ؿ��������㷨,���㷨����Ϸ����ǰ��ֹ�Ƴ�,��ʹ�ü�ֵ���������ն˽����� AlphaGo ��λ����������������� rollout �ͽضϵ� rollout,��ijЩ����������������֪��ʱ����ѧϰ�㷨 TD(��)�� AlphaGo ����֮ǰ�Ĺ�����ͬ,��ʹ���˸�������ǿ��IJ��Ժͼ�ֵ������ʾ; �����������������Ա�ʾ������������,��˱����첽������
- MCTS �������ںܴ�̶���ȡ�����Ƴ����Ե������� ֮ǰ�Ĺ����ص���ͨ���ලѧϰ��ǿ��ѧϰ��ģ��ƽ���������Ӧ���ֹ�����ģʽ��ѧϰ�ƹ����; Ȼ��,������֪,���� rollout ��λ������������ȷ�� AlphaGo ʹ����Լ� rollout,����ʹ�ü�ֵ�����ֱ�ӵؽ��λ����������ս�����⡣
- �����㷨�� Ϊ�˽�������������Ч�ؼ��ɵ� AlphaGo ��,����ʵʩ���첽���Ժ�ֵ MCTS �㷨 (APV-MCTS)�� �������е�ÿ���ڵ�
s
s
s �������кϷ�����
a
��
A
(
s
)
a \in A(s)
a��A(s) �ı�
(
s
,
a
)
(s, a)
(s,a) �� ÿ���ߴ洢һ��ͳ����Ϣ,
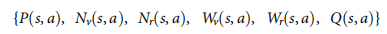
- ���� P ( s , a ) P(s, a) P(s,a) ���������, W v ( s , a ) W_v(s, a) Wv?(s,a)�� W r ( s , a ) W_r(s, a) Wr?(s,a) ���ܶ���ֵ�����ؿ�����,�� N v ( s , a ) N_v(s, a) Nv?(s,a) �� N r ( s , a ) N_r(s, a) Nr?(s,a) ���ۻ� ) �ֱ���Ҷ�������� rollout ����, Q ( s , a ) Q(s, a) Q(s,a) �Ǹñߵ����ƽ������ֵ�� ���ģ���ڵ����������߳��ϲ���ִ�С� APV-MCTS �㷨��ͼ 3.
- ѡ��(ͼ 3a)�� ÿ��ģ��ĵ�һ�� in-tree �δ��������ĸ���ʼ,��ģ����ʱ�䲽 L L L ����Ҷ�ڵ�ʱ��������ÿ��ʱ�䲽�� t < L t<L t<L ��,�����������е�ͳ������ѡ��һ������, a t = arg ? max ? a ( Q ( s t , a ) + u ( s t , a ) ) {a_t} = \arg {\max _a}\left( {Q\left( {{s_t},a} \right) + u\left( {{s_t},a} \right)} \right) at?=argmaxa?(Q(st?,a)+u(st?,a)) ʹ�� PUCT �㷨�ı��� p,���� cpuct ��ȷ��̽������ij���; �����������Ʋ��������ϲ�����и�������ʺ͵ͷ��ʴ����Ķ���,��������ϲ�����и߶���ֵ�Ķ���������Щʱ�䲽�е�ÿһ��, t < L t<L t<L,����ͳ��ѡ��һ������ �������� ��,t ʹ�� PUCT �㷨�ı��� u ( s , a ) = c p u c t P ( s , a ) �� b N r ( s , b ) 1 + N r ( s , b ) u\left( {s,a} \right) = {c_{puct}}P\left( {s,a} \right)\frac{{\sqrt {\sum\nolimits_b {{N_r}\left( {s,b} \right)} } }}{{1 + {N_r}\left( {s,b} \right)}} u(s,a)=cpuct?P(s,a)1+Nr?(s,b)��b?Nr?(s,b)?? ,���� c p u c t c_{puct} cpuct? ��ȷ��̽������ij���; �����������Ʋ��������ϲ�����и�������ʺ͵ͷ��ʴ����Ķ���,��������ϲ�����и߶���ֵ�Ķ�����
- ����(ͼ 3c)�� ��ֵ���罫Ҷ��λ�� s L s_L sL? ���ӵ��������������� v �� ( s L ) v_��(s_L) v��?(sL?),������֮ǰ�Ѿ����������� ÿ��ģ��ĵڶ����Ƴ��δ�Ҷ�ڵ� s L s_L sL? ��ʼ,һֱ��������Ϸ������ ����Щʱ�䲽���е�ÿһ��, t �� L t��L t��L,������Ҷ������Ƴ�����ѡ����, a t �� p �� ( ? �O s t ) a_t \sim p_��(?|s_t) at?��p��?(?�Ost?)�� ����Ϸ�ﵽ����״̬ʱ,��� z t = �� r ( s T ) z_t= �� r(s_T) zt?=��r(sT?) �����յ÷ּ���ó���
- ����(ͼ 3d)����ģ���ÿ�� in-tree ���� t �� L t��L t��L ��,���� rollout ͳ������,�ͺ������Ѿ������ n v l n_{vl} nvl? ������, N r ( s t , a t ) �� N r ( s t , a t ) + n v l N_r(s_t, a_t)��N_r(s_t, a_t)+n_{vl} Nr?(st?,at?)��Nr?(st?,at?)+nvl?; W r ( s t , a t ) �� W r ( s t , a t ) ? n v l W_r(s_t, a_t)��W_r(s_t, a_t) -n_{vl} Wr?(st?,at?)��Wr?(st?,at?)?nvl?;����������ʧ��ֹ�����߳�ͬʱ̽����ͬ�ı仯����ģ�����ʱ,��ÿ������ t �� L t��L t��L �ķ����и��� rollout ͳ����Ϣ,�ý�� N r ( s t , a t ) �� N r ( s t , a t ) ? n v l + 1 N_r(s_t, a_t)��N_r(s_t, a_t) -n_{vl}+1 Nr?(st?,at?)��Nr?(st?,at?)?nvl?+1 �滻������ʧ; W r ( s t , a t ) �� W r ( s t , a t ) + n v l + z t W_r(s_t, a_t)��W_r(s_t, a_t)+n_{vl}+z_t Wr?(st?,at?)��Wr?(st?,at?)+nvl?+zt?���첽��,��Ҷ��λ�� s L s_L sL? ���������ʱ,�����������ķ��ݡ���ֵ�������� v �� ( s L ) v_��(s_L) v��?(sL?) �����ڵڶ��η����и��¼�ֵͳ����Ϣ,ͨ��ÿ������ t �� L t �� L t��L, N v ( s t , a t ) �� N v ( s t , a t ) + 1 N_v(s_t, a_t)��N_v(s_t, a_t)+1 Nv?(st?,at?)��Nv?(st?,at?)+1, W v ( s t , a t ) �� W v ( s t , a t ) + v �� ( s L ) W_v(s_t, a_t) ��W_v(s_t, a_t)+v_��(s_L) Wv?(st?,at?)��Wv?(st?,at?)+v��?(sL?)��ÿ��״̬���������������� Monte Carlo ����ֵ �� �� �� �ļ�Ȩƽ��ֵ,������ֵ����� rollout �������Ȩ���� �� �� �� �����һ�����и��¶�������ִ�еġ�
- ��չ(ͼ 3b)�������ʴ���������ֵ N r ( s , a ) > n t h r N_r(s, a)>n_{thr} Nr?(s,a)>nthr? ʱ,�����״̬ s �� = f ( s , a ) s'=f(s, a) s��=f(s,a) ���ӵ��������С��½ڵ��ʼ��Ϊ { N ( s �� , a ) = N r ( s �� , a ) = 0 , W ( s �� , a ) = W r ( s �� , a ) = 0 , P ( s �� , a ) = p �� ( a �O s �� ) } \{ N(s', a)=N_r(s', a)=0, W(s', a)=W_r(s', a)=0, P(s',a) =p_��(a|s') \} {N(s��,a)=Nr?(s��,a)=0,W(s��,a)=Wr?(s��,a)=0,P(s��,a)=p��?(a�Os��)},ʹ�������� p �� ( a �O s �� ) p_��(a|s') p��?(a�Os��)(������ rollout ����,�����и����,��μ���չ���ݱ� 4)Ϊ����ѡ���ṩռλ��������ʡ�λ�� s �� s' s�� Ҳ�����뵽һ��������,���ڲ���������첽 GPU ��������������� SL �������� p �� �� ( ? �O s �� ) {p_��}^��(?|s��) p��?��(?�Os��) ����,softmax �¶�����Ϊ �� �� ��;��Щʹ��ԭ�Ӹ����滻��ռλ��������� $P( s��,a) �� {p_��}^��(a|s��) ����ֵ n t h r n_{thr} nthr? �Ƕ�̬������,��ȷ����λ�����ӵ����Զ��е������� GPU �������������������ƥ�䡣λ���ɲ�������ͼ�ֵ����ʹ�� mini-batch ��СΪ 1 ������,����С���˵�������ʱ�䡣
- ���ǻ�ʵ���˷ֲ�ʽ APV-MCTS �㷨�� �üܹ���ִ���������ĵ���������ִ���첽����Ķ��Զ�̹��� CPU �Լ�ִ���첽���Ժͼ�ֵ���������Ķ��Զ�̹��� GPU ��ɡ� �����������洢�� master ��,��ִֻ��ÿ��ģ��� in-tree �Ρ� Ҷλ����ִ��ģ����Ƴ��εĹ��� CPU ���� GPU ����ͨ��,�����������������������Ժͼ�ֵ���硣 ���������������ʷ��ظ����ڵ�,�����������滻����չ�ڵ��ռλ��������ʡ� ���� rollout �Ľ����ͼ�ֵ����������Է��ظ� master,������ԭʼ����·����
- ����������ʱ,AlphaGo ѡ����ʴ������Ķ���; �������ֵ���,����쳣ֵ��̫���С� �������ں���ʱ�䲽������:���Ŷ�����Ӧ���ӽڵ��Ϊ�µĸ��ڵ�; ������������������ͬ��������ͳ�����ݶ�����������,���������ಿ�ֱ������� AlphaGo �ı����汾�ڶ��ֵ��ƶ������м��������� �������ʴ����IJ����������ֵ�IJ�����һ��,����չ������ ʱ����Ʊ����Ϊ����Ϸ����ʹ�ô�ʱ�䡣 �� AlphaGo �������������ڹ��Ƶ� 10% Ӯ�ñ����ĸ���ʱ,�� m a x a Q ( s , a ) < ? 0.8 max_aQ(s,a)<-0.8 maxa?Q(s,a)<?0.8ʱ,AlphaGo ����ְ��
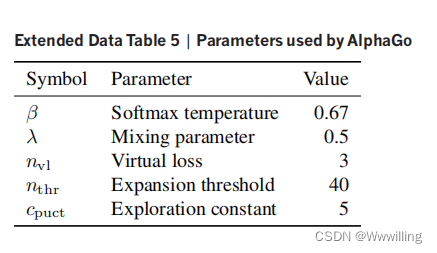
- AlphaGo û�в����ڴ�������ؿ���Χ�������ʹ�õ������岽������ٶ�����ֵ���Ʒ�; ��ʹ�ò���������Ϊ����֪ʶʱ,��Щ��ƫ��������ʽ�����ƺ���������κζ���ĺô��� ����,AlphaGo ��ʹ�ý���ʽ�ӿ�����̬ komi �֡� AlphaGo�ڷ��Ա�����ʹ�õIJ���������չ���ݱ�5�С�
- Rollout policy�� rollout ���� p �� ( a �O s ) p_��(a|s) p��?(a�Os) ��һ�ֻ��ڿ��١��������㡢���ھֲ�ģʽ������������ softmax ����,��������״̬ s s s ��ǰһ���ƶ���Χ�ġ���Ӧ��ģʽ����Χ�ġ�����Ӧ��ģʽ��ѡ����״̬ s s s ���ƶ� a a a��ÿ������Ӧģʽ��һ����Ԫ����,ƥ���� a a a Ϊ���ĵ��ض� 3��3 ģʽ,��ÿ�����ڽ�������ɫ(��ɫ����ɫ����)�����ɼ���(1��2����3)���塣ÿ����Ӧģʽ����һ����Ԫ����,����ǰһ���ƶ�Ϊ���ĵ� 12 ������ģʽ 21 �е���ɫ�����ɼ�����ƥ�䡣����,�����ֹ������ľֲ��������볣ʶ��Χ�����(�μ���չ���ݱ� 4)���������������,rollout ���Ե�Ȩ�� �� �� �� �Ǵ� Tygem ��������������Ϸ�� 800 ���λ��ѵ����,��ͨ������ݶ��½��������Ȼ���ڿհ���,ÿ�� CPU �߳�ÿ��ִ�д�Լ 1,000 ��ģ�⡣
- ���ǵ��Ƴ����� p �� ( a �O s ) p_��(a|s) p��?(a�Os) �������ֹ�֪ʶ�������Ƚ���Χ����� �෴,�������� MCTS �и��������Ķ���ѡ��,�������������Ͳ�������֪ͨ�ġ� ����������һ���¼���,���Ի����������е������ƶ�,Ȼ�����Ƴ��ڼ䲥�����Ƶ��ƶ�; �����һ���õĻظ�������ʽ�ĸ����� ����������ÿһ��,����ܵĶ����������뵽һ����ϣ����,�Լ�Χ��ǰһ���ƶ��͵�ǰ�ƶ��� 3��3 ģʽ������(��ɫ�����ɶȺ�ʯͷ����)�� �� rollout ��ÿһ��,ģʽ�����Ķ������ϣ������ƥ��; ����ҵ�ƥ��,��洢���ƶ��Ը߸��ʽ��С�
- �Գ�������֮ǰ�Ĺ�����,ͨ���ھ�������ʹ����ת�ͷ��䲻���˲��������� Go �ĶԳ��ԡ���������С���������п�����Ч,����ʵ���ϻ��������������,��Ϊ������ֹ�м������ʶ���ض��ķǶԳ�ģʽ ���෴,����ͨ��ʹ�ð˴η������ת�Ķ�������
d
1
(
s
)
,
��
,
d
8
(
s
)
d_1(s), ��, d_8(s)
d1?(s),��,d8?(s) ��̬�任ÿ��λ��
s
s
s ������ʱ���öԳ��ԡ�����ʽ�ԳƼ�����,���� 8 ��λ�õ�С�������ݵ�����������ֵ���粢���м��㡣���ڼ�ֵ����,���ֵ����ƽ�� ��
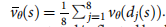
- ���ڲ�������,�������ƽ�汻��ת/�����ԭʼ����,��һ��ƽ�����ṩ����Ԥ��
��
��
�� ;���ַ����������ǵ�ԭʼ��������(�μ���չ���ݱ� 3)���෴,APV-MCTS ʹ����ʽ�ԳƼ���,Ϊÿ���������ѡ����ת/����
j
��
[
1
,
8
]
j \in [1, 8]
j��[1,8]������ֻ����÷����һ������;��ÿ��ģ����,����ͨ��
v
��
(
d
j
(
s
L
)
)
v_��(d_j(s_L))
v��?(dj?(sL?)) ����Ҷ�ڵ�
s
L
s_L
sL? ��ֵ,�������������̶���Щ��������ƽ�������Ƶ�,����Ϊ�������ѡ�����ת/��������������

- ��������:����������ѵ���������� p �� p_�� p��? �Ը��� KGS ���ݼ��е�ר�Ҷ�����λ�ý��з��ࡣ�����ݼ����� KGS 6 �� 9 λ���������� 160,000 �������е� 2940 ���λ��; 35.4% ����Ϸ�Dz����Ϸ�����ݼ���Ϊ���Լ�(ǰһ�����λ��)��ѵ����(���� 2840 ���λ��)�����������ų������ݼ��С�ÿ��λ�ö���ԭʼ�������� s s s ������ѡ����ƶ� a a a ��ɡ��������������ݼ�����ÿ��λ�õ����а˸��������ת��Ϊÿ��λ��Ԥ�ȼ����˶Գ���ǿ����������������ÿ��ѵ������,���Ǵ���ǿ�� KGS ���ݼ������ѡ���� m m m ��С��������, { s k , a k } k = 1 m \left\{ {{s^k},{a^k}} \right\}_{k = 1}^m {sk,ak}k=1m?��Ӧ���첽����ݶ��½�������������Ķ�����Ȼ, �� �� = a m �� k = 1 m ? log ? p �� ( a k �O s k ) ? �� \Delta \sigma = \frac{a}{m}\sum\nolimits_{k = 1}^m {\frac{{\partial \log {p_\sigma }\left( {{a^k}|{s^k}} \right)}}{{\partial \sigma }}} ����=ma?��k=1m??��?logp��?(ak�Osk)?������ �� �� �� ��ʼ��Ϊ 0.003,ÿ 8000 ���ѵ��������,û�ж�����,С������СΪ m = 16 m=16 m=16��ʹ�� DistBelief �� 50 �� GPU ���첽Ӧ�ø���;���� 100 �����ݶȱ������� 3.4 �ڸ�ѵ��������Ҫ��Լ 3 �ܵ�ʱ�䡣
- ��������:ǿ��ѧϰ������ͨ�������ݶ�ǿ��ѧϰ��һ��ѵ���˲������硣ÿ�ε����������������е�С���� n n n ����Ϸ,�ڵ�ǰ����ѵ���IJ������� p �� p_�� p��? ��ʹ��������ǰ�����IJ��� �� ? ��^- ��?�Ķ��� p �� ? {p_��}^? p��??֮��,�ӳ����������������ѵ�����ȶ��ԡ�Ȩ�ر���ʼ��Ϊ �� = �� ? = �� ��=��^? =�� ��=��?=����ÿ 500 �ε���,���ǽ���ǰ���� �� �� �� ���ӵ����ֳ��С�С�����е�ÿ����Ϸ i i i һֱ���е����� T i T_i Ti? ��ֹ,Ȼ���ÿ����ҵĽǶȽ���������ȷ����� z t i = �� r ( s T i ) z_t^i = \pm r\left( {{s_{{T^i}}}} \right) zti?=��r(sTi?)��Ȼ���ز���Ϸ��ȷ�������ݶȸ���, �� �� = a n �� i = 1 n �� t = 1 T i ? log ? p �� ( a t i �O s t i ) ? �� ( z t i ? v ( s t i ) ) \Delta \rho = \frac{a}{n}\sum\nolimits_{i = 1}^n {\sum\nolimits_{t = 1}^{{T^i}} {\frac{{\partial \log {p_\rho }\left( {a_t^i|{s_t}^i} \right)}}{{\partial \rho }}} } \left( {z_t^i - v\left( {s_t^i} \right)} \right) ����=na?��i=1n?��t=1Ti??��?logp��?(ati?�Ost?i)?(zti??v(sti?)),ʹ�� REINFORCE �㷨 ����� v ( s t i ) {v\left( {s_t^i} \right)} v(sti?)���ڷ�����١��ڵ�һ��ͨ��ѵ���ܵ�ʱ,��������Ϊ��;�ڵڶ�����,����ʹ�ü�ֵ���� v �� ( s ) v_��(s) v��?(s) ��Ϊ����;���ṩ��һ��С�����������������ַ�ʽ�Բ������������һ���ѵ��,ʹ�� 50 �� GPU,�� 128 ����Ϸ�� 10,000 ��С��������ѵ����
- ��ֵ����:�ع�������ѵ����һ����ֵ����
v
��
(
s
)
��
v
p
��
(
s
)
v_��(s) \approx v^{p_��}(s)
v��?(s)��vp��?(s)������ RL ��������
p
��
p_��
p��? �ļ�ֵ������Ϊ�˱�����������Ϸ��ǿ��ص�λ��,���ǹ�����һ���벻��ص�������Ϸλ�õ������ݼ���������ݼ��������� 3000 ���λ��,ÿ��λ�ö�����һ�����ص�������Ϸ��ÿ����Ϸ����ͨ���������ʱ�䲽��
U
��
u
n
i
f
{
1
,
450
}
U \sim unif \{1, 450 \}
U��unif{1,450} �Լ��� SL ���������в���ǰ
t
=
1
,
��
U
?
1
t=1,�� U?1
t=1,��U?1 �ƶ�,
a
t
��
p
��
(
?
�O
s
t
)
a_t \sim p_��(��|s_t)
at?��p��?(?�Ost?) �������������ɵ�;Ȼ��ӿ��õ��ƶ���������ȵز���һ���ƶ�,
a
U
��
u
n
i
f
{
1
,
361
}
a_U \sim unif \{1, 361 \}
aU?��unif{1,361}(�ظ�ֱ��
a
U
a_U
aU? �Ϸ�);Ȼ��� RL ��������
a
t
��
p
��
(
?
�O
s
t
)
a_t \sim p_��(��|s_t)
at?��p��?(?�Ost?) ��ʣ����ƶ����н��в���,ֱ����Ϸ����,
t
=
U
+
1
,
��
T
t=U+1, �� T
t=U+1,��T�����,����Ϸ����������ȷ�����
z
t
=
��
r
(
s
T
)
z_t=��r(s_T)
zt?=��r(sT?)��ÿ����Ϸ�����ݼ���ֻ������һ��ѵ��ʾ��
(
s
U
+
1
,
z
U
+
1
)
(s_{U+1}, z_{U+1})
(sU+1?,zU+1?)���������ṩ�˼�ֵ��������ƫ������
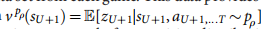
- �����ɵ�ǰ������,���Ǵ������ϴ�ķֲ��н��в���,���������ݼ��Ķ����ԡ�ѵ�������� SL ��������ѵ����ͬ,��֮ͬ�����ڲ������»���Ԥ��ֵ�۲쵽�Ľ���֮��ľ������,
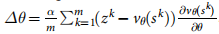
- ��ֵ����ʹ�� 50 �� GPU �� 32 ��λ�õ� 5000 ���С����������Ϊ��һ�ܵ�ѵ����
- ����/��ֵ����Ĺ�����ÿ��λ��
s
s
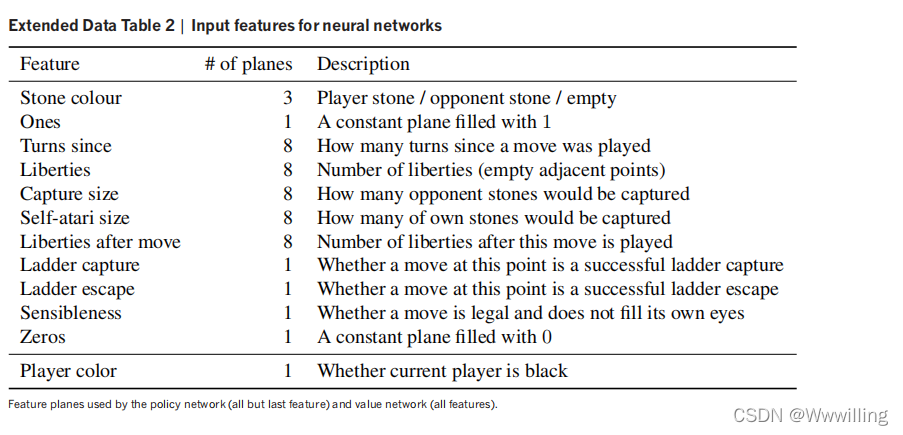
s ��Ԥ������һ�� 19��19 ������ƽ�档����ʹ�õ�����ֱ��������Ϸ�����ԭʼ��ʾ,����Χ�����̵�ÿ��������״̬:������ɫ�����ɶ�(�����������ڿյ�)�����Ϸ��ԡ������������Ļغ���,��(�������ڼ�ֵ����)��ǰҪ���ŵ���ɫ������,����ʹ��һ����ս��������������������Ľ��������������������ڵ�ǰҪ���ŵ���ɫ�����;����,ÿ��������ʯͷ��ɫ��ʾΪ��һ����,�����Ǻ�ɫ���ɫ��ÿ����������ֵ���ֳɶ�� 19��19 ƽ��Ķ�����ֵ(one-hot encoding)������,�����Ķ�Ԫ����ƽ�����ڱ�ʾ������Ƿ���� 1 ��liberties���ɡ�2 �����ɡ���������8 �����ɡ�����������ƽ�漯������չ���ݱ� 2 �С�
- ������ܹ��� ����������������� 48 ������ƽ����ɵ� 19��19��48 ͼ���ջ�� ��һ�����ز��㽫�������Ϊ 23��23 ��ͼ��,Ȼ�� k k k ���ں˴�СΪ 5��5 ���˲���������ͼ����о���,����Ϊ 1,��Ӧ�������������ԡ� �������ز� 2 �� 12 �е�ÿһ���������Ե�ǰһ�����ز�����䵽һ�� 21��21 ��ͼ����,Ȼ�� k k k ���ں˴�СΪ 3��3 ���˲����벽�� 1 ���о���,�ٴθ���������������� ���һ�㽫�ں˴�СΪ 1��1 �� 1 ���˲����벽�� 1 ���о���,ÿ��λ�þ��в�ͬ��ƫ��,��Ӧ�� softmax ������ AlphaGo �ı����汾ʹ���� k = 192 k=192 k=192 ��������; ͼ 2b ����չ���ݱ� 3 ����ʾ��ʹ�� k = 128��256 �� 384 ���˲�����ѵ�������
- ��ֵ���������Ҳ��һ�� 19��19��48 ��ͼ���ջ,����һ������Ķ�Ԫ����ƽ��������ǰҪ���ŵ���ɫ�� ���ز� 2 �� 11 �����������ͬ,���ز� 12 ��һ������ľ�����,���ز� 13 ���� 1 ���ں˴�СΪ 1��1 ���˲���,����Ϊ 1,���ز�14��һ��ȫ���ӵ����Բ�,��256��������Ԫ�� ������Ǿ��е��� tanh ��Ԫ��ȫ�������Բ㡣
- ����������ͨ���ٰ��ڲ�������������ÿ������� Elo �ȼ������������Χ���������ǿ�ȡ�����ͨ��������
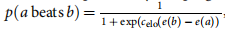
- ���Ƴ��� a ���ܳ��� b �ĸ���,��ͨ�� BayesElo ����ʹ�ñ����� c e l o = 1 / 400 c_{elo}=1/400 celo?=1/400 ����ı�Ҷ˹���ع�������� e ( ? ) e(��) e(?)������������ְҵΧ��ѡ�ַ��۵� BayesElo ����(�ύ����Ϊ 2,908)�����г���ÿ���ƶ������� 5 ��ļ���ʱ��;����ʹ���й�����Ʒ�,����Ϊ 7.5 ��(�ӷ��Բ�������ڶ���)�����ǻ������� AlphaGo ������Χ������°�����÷���Ϸ;������Щ��Ϸ,����ʹ���˷DZ����÷�ϵͳ,���б����˿���,����ͨ�����÷ֵ��ϸ��˺�ɫ�����ʯͷ��ʹ����Щ����, K K K �����ӵ��÷ֵ��൱�ڸ����� K ? 1 K-1 K?1 �����ɲ�,������ʹ�ñ����� Komi �õ����� K ? 1 / 2 K-1/2 K?1/2 �����ɲ�������ʹ����Щ�÷ֹ�������Ϊ AlphaGo �ļ�ֵ����ר��ѵ��Ϊʹ�� 7.5 �� komi��
- ���˷ֲ�ʽ AlphaGo ֮��,ÿ�������Χ��������Լ��ĵ�����ִ��,������ͬ�Ĺ��,ʹ�����µĿ��ð汾�ó���֧�ֵ����Ӳ������(�μ���չ���ݱ� 6)�� ��ͼ 4 ��,���������Ľ����������ڸó���ﵽ����� KGS ����; ����,KGS �汾�����빫���汾��ͬ��
- �Է��Եı����ɹ����IJ��н����ٲá� 5 ����ʽ������ 5 ������ʽ������ 7.5 komi�����÷������й�������С� AlphaGo �ֱ��� 5-0 �� 3-2 Ӯ������Щ��Ϸ(ͼ 6 ����չ���ݱ� 1)�� ��ʽ������ʱ������� 1 Сʱ����Ҫʱ��������� 30 ��ı���ʱ�䡣 ����ʽ��Ϸ��ʱ����������� 30 �� byoyomi�� ��ǰ����ѡ����ʱ����ƺͱ�������; ��ͬ����������������ȫ����ʽ���������� Ϊ�˴����������۶Լ����Χ�������������,���ǽ�����ʮ�������Ľ�����ӵ����ǵ��ڲ����������,������ʱ����ƵIJ��졣