因机器无法直接接收单词、词语、字符等标识符(token),所以把标识符数值化一直是人们研究的内容。开始时人们用整数表示各标识符,这种方法简单但不够灵活,后来人们开始用独热编码(One-Hot Encoding)来表示。这种编码方法虽然方便,但非常稀疏,属于硬编码,且无法重载更多信息。此后,人们想到用数值向量或标识符嵌入(Token Embedding)来表示,即通常说的词嵌入(Word Embedding),又称为分布式表示。不过Word Embedding方法真正流行起来,还要归功于Google的word2vec。
从文本、标识符、独热编码到向量表示的整个过程,可以用下图表示:
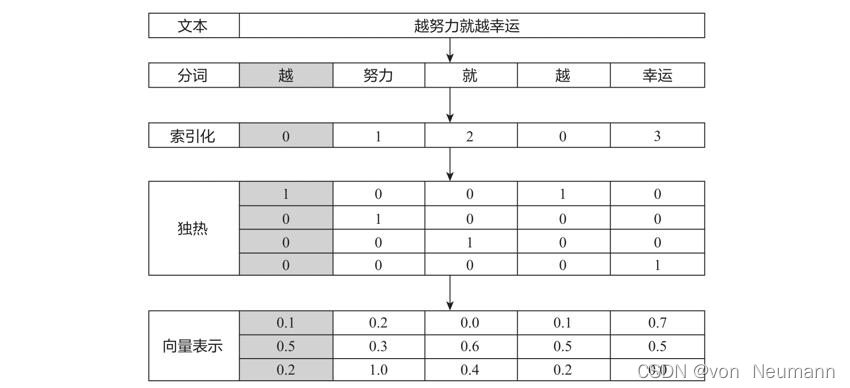
从上图可以看出,独热编码是稀疏、高维的硬编码,如果一个语料有一万个不同的词,那么每个词就需要用一万维的独热编码表示。如果用向量或词嵌入表示,那么这些向量就是低维、密集的,且这些向量值都是通过学习得来的,而不是硬性给定的。至于词嵌入的学习方法,大致可以分为两种:利用机器学习框架的Embedding层学习词嵌入和使用预训练的词嵌入。
利用机器学习框架的Embedding层学习词嵌入
在完成任务的同时学习词嵌入,例如,把Embedding作为第一层,先随机初始化这些词向量,然后利用机器学习框架(如PyTorch、TensorFlow等框架)不断学习(包括正向学习和反向学习),最后得到需要的词向量。
使用预训练的词嵌入
利用在较大语料上预训练好的词嵌入或预训练模型,把这些词嵌入加载到当前任务或模型中。预训练模型很多,如word2vec、ELMo、BERT、XLNet、ALBERT等,后续的文章将介绍这些预训练模型。