难得一个名字不那么长的论文0.0
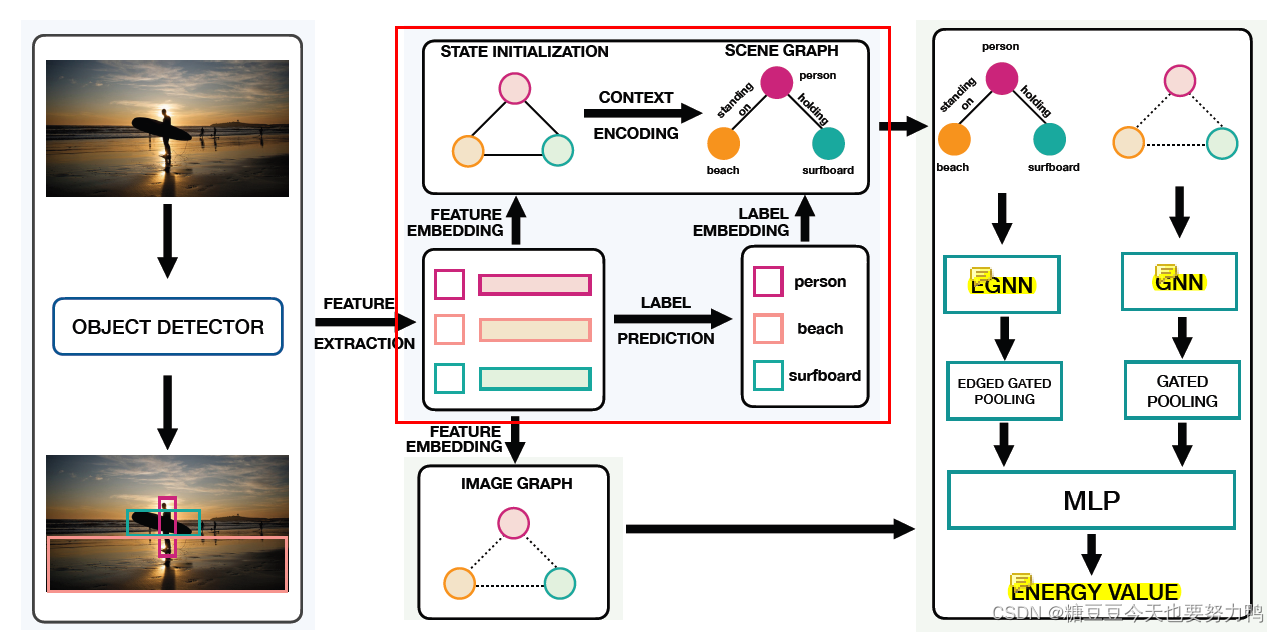
1.目标检测
2.淡蓝色底的部分,因为颜色比较淡用红框框出来了。这部分是传统的场景图生成流程。
3.绿色底的部分,也是这篇论文作者主要的贡献点:
(1)红框下面的image graph
输入图像的图表示,结点是从bbox提取的特征,注意这个图只有结点特征,没有边的特征
(2)计算生成的场景图和基于原图的图表示的联合能量
这部分感觉实质上就是对生成的场景图做refine。
第一步:进行消息传递
基于原图的图表示经过GNN进行消息传递。
传统方法生成的场景图经过edge GNN进行消息传递。
这里的edge GNN也是作者提出的网络:
结点特征更新公式如下:
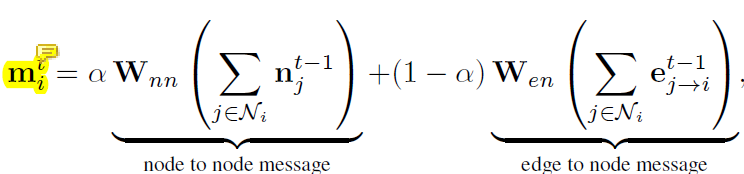
mit是第i个结点第t次迭代的特征
α是超参数,用于控制结点到结点和边到结点这两种消息来源的贡献
Wnn:node to node
Wen:edge to node
njt-1是第i个结点周边的第j个结点第t-1次迭代的特征
ej→it-1是从第j个结点到第i个结点的边的特征,同样是第t-1次迭代得到的(注意方向,j→i和i→j是不同的)
边特征更新公式如下:
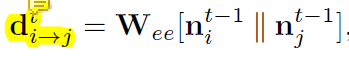
di→jt是第i个结点到第j个结点的边在第t次迭代得到的特征
Wee:edge to edge
nit-1:第i个结点特征(t-1次迭代)
njt-1:第j个结点特征(t-1次迭代)
第二步:Gated Pooling
对于场景图(经过edge GNN):
N:整个场景图的结点特征
E:整个场景图的边特征
fgate:把结点特征映射为标量的函数
ggate:把边特征映射为标量的函数
⊙:按元素乘
(这里应该是对所有的结点的特征都求了和,当做整个场景图的结点特征,边特征也是一样)
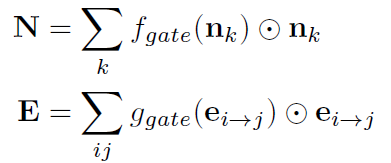
对于图特征(经过GNN):
没有边特征,只有结点特征
整个图的表示用结点特征代替
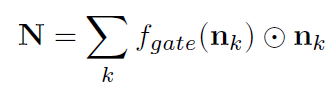
第三步:MLP
在将这两幅图的特征表示cat在一起后,经过一个MLP,得到最终表示,就是论文题目中的energy。它是input(image)和output(scene graph)的联合能量。
联合能量表示为Eθ(GI,GSG)
4.损失函数
GSG+是真实的场景图,GI+是基于原图真实bbox得到的图,这个损失函数的目的是让生成的场景图和原图之间的能量尽可能地接近
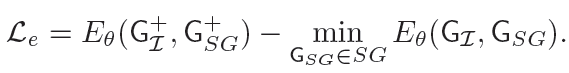
观察到梯度爆炸,所以加了L2范数
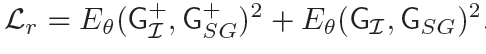
论文没给Lt的公式,只说Lt是在预测输出上作为初始预测的附加正则化,这段没看懂,明天再看看吧。
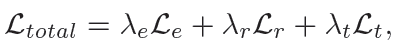
----------------------------一些碎碎念-------------------------
这周五就是我分享论文了。
打算分享这篇了。
搜了csdn和知乎也没有大佬解读这篇论文,于是自割腿肉(?)
有一说一感觉前面introduction的分析的目前场景图模型的欠缺和后面的模型联系不是很紧密(目前觉得是这样,我后面再康康)
去下了源码,发现是汤凯华大佬的代码基础上写的,哭哭,总算不是MOTIF改了的,在这里点名Probabilistic Modeling of Semantic Ambiguity for Scene Graph Generation(指指点点.jpg)