今天开始陆续更新之前文章的阅读笔记,有一些文章是辅助实验简单读的,有一些文章是精读的。这里也不做分类了,只是每次在开头提一下相关信息。
文章链接:戳我
主要工作:描述了历史
平均值、时间序列、神经网络和非参数回归四个模型对高速公路交通流量的预测问题。
在运营环境中预测交通量的能力已被确定为智能交通系统(ITS)的一个关键需求。这项研究工作的重点是为弗吉尼亚州北部的首都环形公路上的两个地点开发交通量预测模型。
弗吉尼亚州北部的首都环形公路上的两个地点开发交通量预测模型。针对高速公路交通流量预测问题,开发并测试了四个模型。
问题描述:已知当前时刻的流量,以及前一个预测期的交易量(这里选择15分钟为一个预测期)。此外,假设过去的条件数据库可以用来计算历史平均量。那么问题就可以被下图描述。

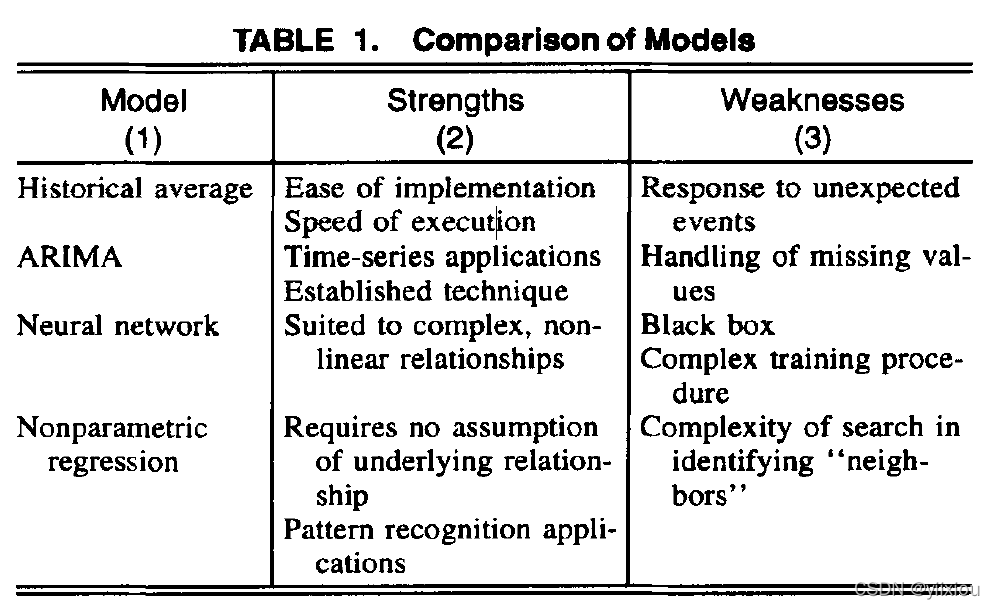
HA:利用过去交通量的平均值来预测将来的交通量。依赖交通流量的周期性,对于动态变化不能做出反应,比如事故,或者启动,急刹车这一类的。
HA的工作方式:在时间t,V(t+D)被估计为V(hist)(t+D)
Time series:自回归综合移动平均模型ARIMA:试图建立一个数学模型来解释之前的事。它依赖不间断的数据。
Back propagation neural network:反向传播是神经网络当前传播范围极广的范式。
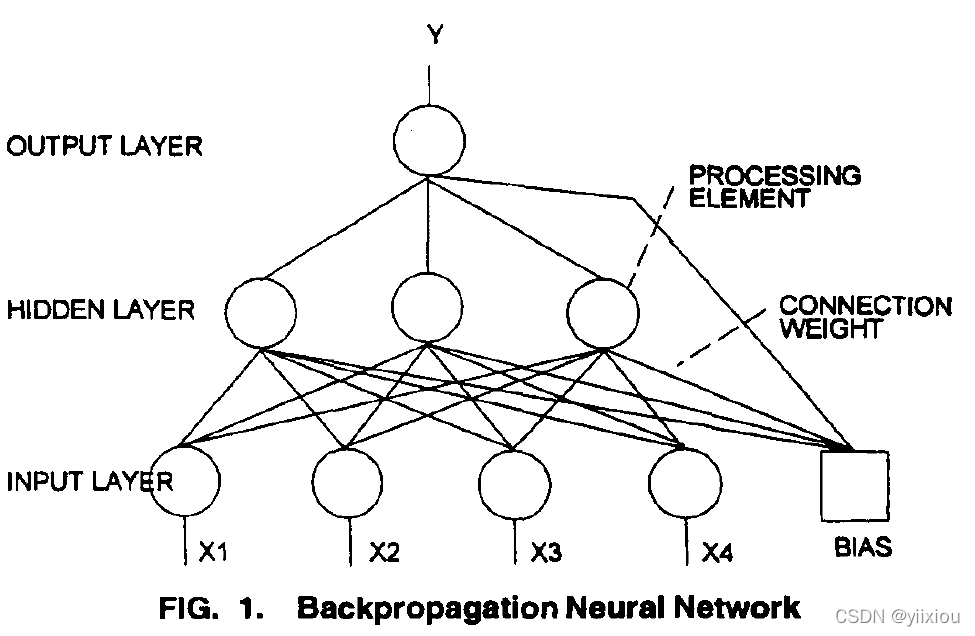
反向传播网络在输入层接受输入,讲将加权后的输入值在隐藏层求和,对总和进行加权,最后传递给输出层。输入和输出之间的映射是通过网络结构分布的。这种模型表示允许灵活性,但是变量之间的关系难以确定。反向传播神经网络可以有效的表达复杂的非线性关系,但是有可能对网络进行过度训练,从而导致不是对关系的概括。
非参数回归:非参数回归被认为是一类动态的聚类模型
非参数回归的近邻计算例子:
考虑一个双变量的估计,函数表示为f(x)=y,其中y的估计值需要对xA=4和xB=9进行估计。
一个包含13个先前观察到的x,y对的数据库,下图就是数据库。假设领域大小k=3,领域A和B被识别出来,通过平均领域内的案例的Y值来计算出Y的估计值。
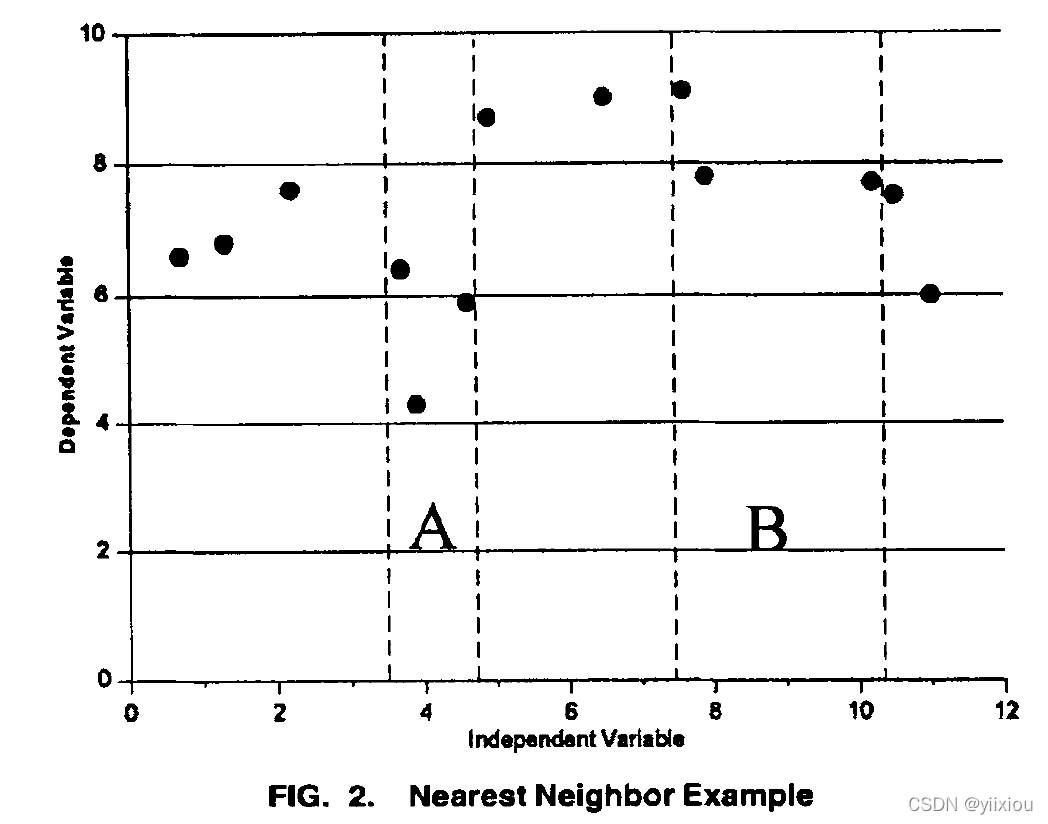
这个工作的算法被编码为自动邻居定义和预测生成过程。它可以通过简单地链接到一个站点的历史数据库来应用到场地,只需要与场地的历史数据库连接。
以上四种模型的优缺点可以表一描述。