mini-batch
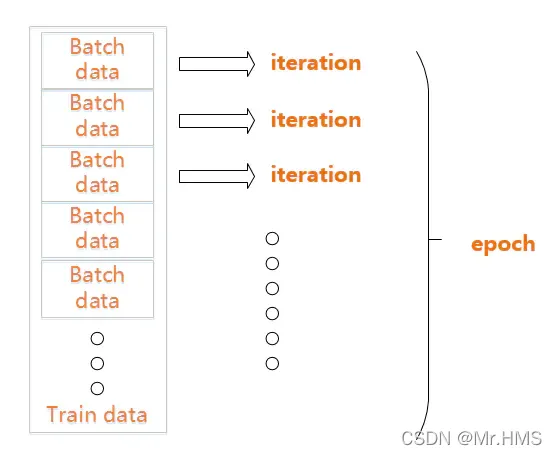
我们已知在梯度下降中需要对所有样本进行处理过后然后走一步,那么如果我们的样 本规模的特别大的话效率就会比较低。假如有500万,甚至5000万个样本(在我们的业务场景中,一般有几千万行,有些大数据有10亿行)的话走一轮迭代就会非常的耗时。这个时候的梯度下降叫做full batch。 所以为了提高效率,我们可以把样本分成等量的子集。 例如我们把100万样本分成1000份, 每份1000个样本, 这些子集就称为mini batch。然后我们分别用一个for循环遍历这1000个子集。 针对每一个子集做一次梯度下降。 然后更新参数w和b的值。接着到下一个子集中继续进行梯度下降。 这样在遍历完所有的mini batch之后我们相当于在梯度下降中做了1000次迭代。 我们将遍历一次所有样本的行为叫做一个 epoch,也就是一个世代。 在mini batch下的梯度下降中做的事情其实跟full batch一样,只不过我们训练的数据不再是所有的样本,而是一个个的子集。 这样在mini batch我们在一个epoch中就能进行1000次的梯度下降,而在full batch中只有一次。 这样就大大的提高了我们算法的运行速度。
Batch
对于一个有 2000 个训练样本的数据集。将 2000 个样本分成大小为 500 的 batch,那么完成一个 epoch 需要 4 个 iteration。
如果把准备训练数据比喻成一块准备打火锅的牛肉,那么epoch就是整块牛肉,batch就是切片后的牛肉片,iteration就是涮一块牛肉片(饿了吗?)。